一、基于特征工程完成对贷款数据集Lending Club的预处理
1、✌ 数据集
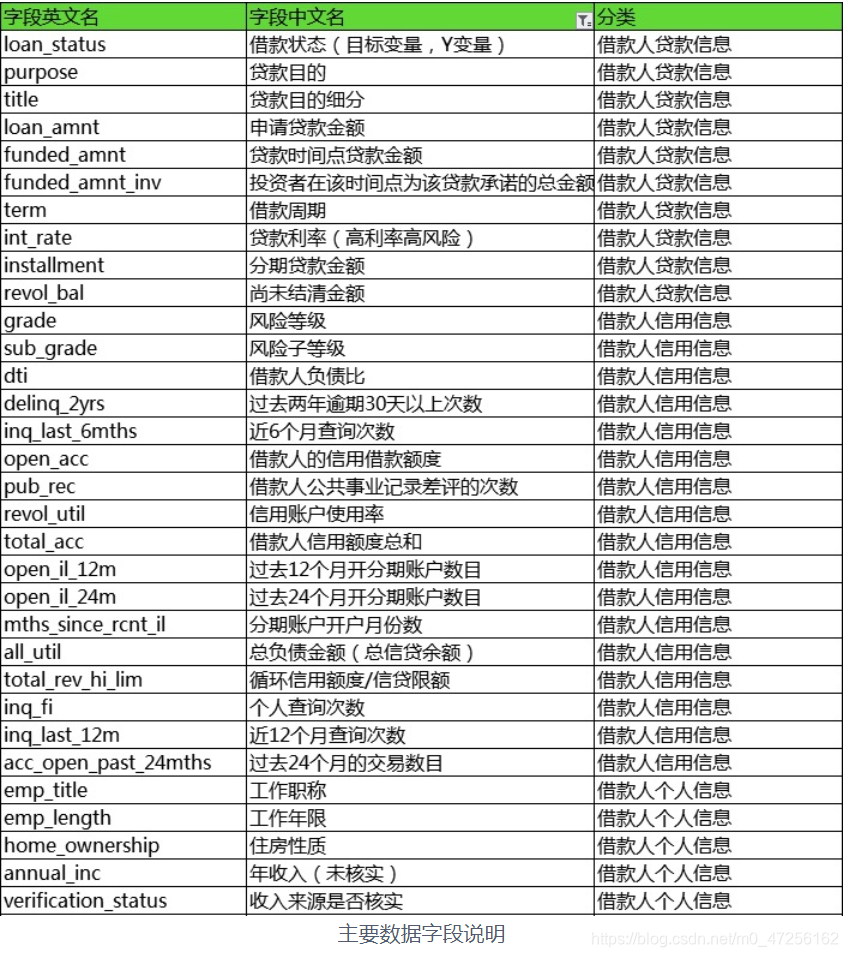
Lending Club 创立于2006年,主营业务是为市场提供P2P贷款的平台中介服务,公司总部位于旧金山。因此合理地对用户进行信用等级划分对贷款业务有着至关重要的意义。
import pandas as pd data=read_csv('loan.csv')
2、✌ 基本流程
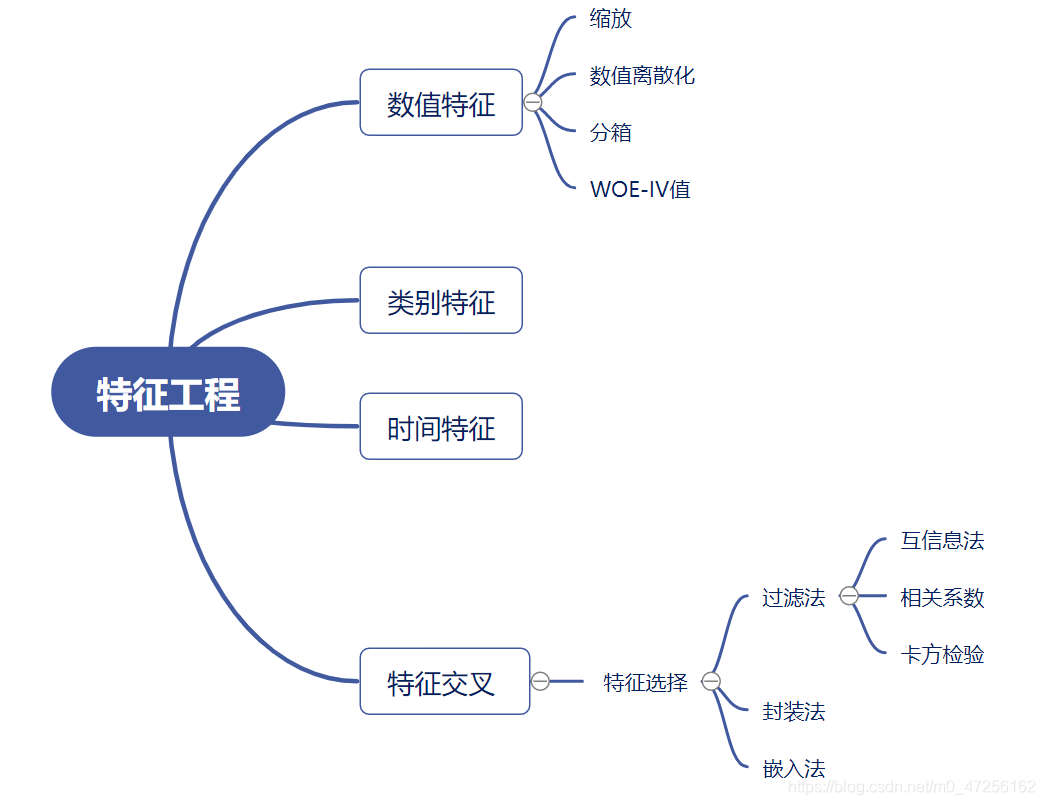
原始特征数据集可能太大,或者信息冗余,因此在机器学习的应用中,一个初始步骤就是选择特征的子集,或构建一套新的特征集,减少功能来促进算法的学习,提高泛化能力和可解释性。特别地,特征工程的主要环节包括特征提取和特征选择。其中特征构建需要用到较多的专业领域知识,将在后面的实战环节进行演示。本教程旨在介绍如何使用pandas和numpy等科学计算工具来进行特征提取处理和特征选择,并介绍了一些常见的处理方法。
3、✌ 特征提取和处理
特征提取和处理是将原始特征转换为一组具有明显物理或统计意义的特征,就是将机器学习算法所识别不了的数据转变成可识别到的数据特征的过程。特别地,提取到的特征能够增强模型的可解释性。
特征提取和处理可以根据不同的特征类型进行,通常有数值特征、类别特征、时间特征、空间特征、文本特征、图像特征等;此外,通过不同特征的交叉组合,也能提取得到新的特征。
在数据挖掘问题中,主要介绍下面几方面的特征提取和处理方法:
- 数值特征
- 类别特征
- 时间特征
- 特征交叉
3.1 ✌ 数值特征
原始数据中可能会包含部分数值类型的特征,他们有测量或计数的意义。主要可分为两类:连续特征和离散特征。
常用的对数值特征提取和处理方法有:
缩放特征的缩放是一种用来统一特征取值范围的方法,在逻辑回归、SVM等不属于树模型的算法中,往往需要进行缩放以使模型取得较好的效果。常用方法有:Z-score标准化、最大最小归一化等。
对数变换对数变换可以对数值较大的范围进行压缩,对数值较小的范围进行扩展,可以很好地应对长尾分布现象,使数据分布更接近正态分布。
数值离散化当原始特征的数值作用不大时,可以采用某种临界点等方法将原始特征转化为二值特征。
分箱当数值跨越的数量级范围较大时,可以把数值按一定的顺序划分为几部分,常用方法有:固定宽度分箱、分位数分箱、卡方分箱、聚类分箱等。
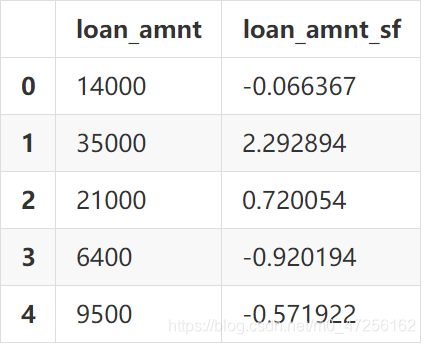
✌ 缩放
sfDf=data['loan_amnt'].to_frame() loan_mean=sfDf['loan_amnt'].mean() loan_std=sfDf['loan_amnt'].std() sfDf['loan_amnt_sf']=(sfDf['loan_amnt']-loan_mean)/load_std sfDf.head()
✌ 数据离散化
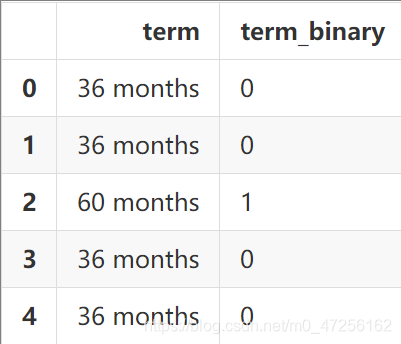
以数据集中的term特征为例,它代表贷款的期限,有36 months和60 months两种取值
termDf=data['term'].to_frame() termDf['term_binary']=termDf['term'].map({' 36 months':0,' 60 months':1}) termDf.head()
✌ 分箱-简单分箱
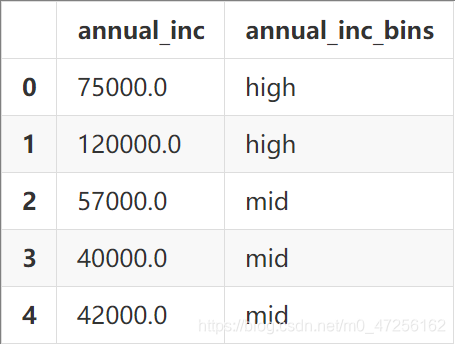
以数据集中annual_inc为例,它代表贷款人的年收入
binsDf=data['annual_inc'].to_frame() set_bins=[0,20000,60000,data['annual_inc'].max()+1] set_labels=['low','mid','high'] binsDf['annual_inc
3.2 ✌ 类别特征
类别特征的取值没有数学意义,不能直接进行计算,需要通过各种编码方法将其变为数值特征。
常用的类别特征提取方法有:
- 标签编码(Label Encoding)标签编码是对类别特征中的每一类特征值赋予一个数值,从而转化为数值特征。当类别特征取值为有序变量时,优先选择标签编码;其他情况下则一般不采用,否则会为特征引入额外的空间距离信息。
- 独热编码(One-Hot Encoding)独热编码又称一位有效编码,是最为常用的编码方法,可以将一个维度为M的特征转变为M个二值特征。对类别特征采用One-Hot编码,会使特征之间距离计算更加合理,也起到了扩充特征的作用。
- 计数编码(Count Encoding)计数编码通过计算每个特征值出现的次数来表示特征的信息,在各种模型中都有一定的效果。其缺点是容易受到异常值的影响,且不同特征值的编码可能产生冲突,根据这一点进一步提出计数排名(LabelCount)编码。
- 目标编码(Target Encoding)目标编码是一种结合目标变量进行编码的方法,即有监督的编码方法,最典型的是Micci-Barreca提出的均值编码(Mean Encoding)。对于高基数(即特征取值较多)特征,使用独热编码会导致特征维度急剧增加,不利于模型预测,而目标编码则适合于这种情形。
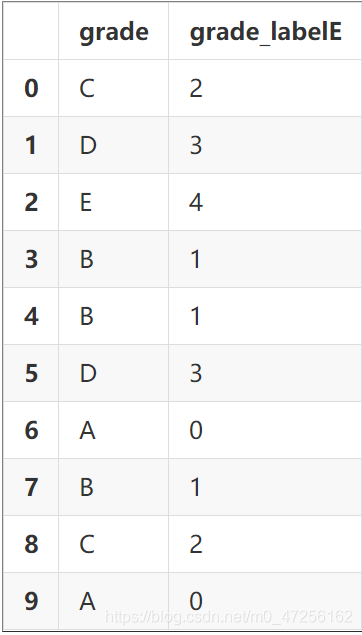
✌ 标签编码
from sklearn.preprocessing import LabelEncoder graDf=data['grade'].to_frame() graDf['grade_label']=LabelEncoder().fit_transform(graDf['grade']) graDf.head()
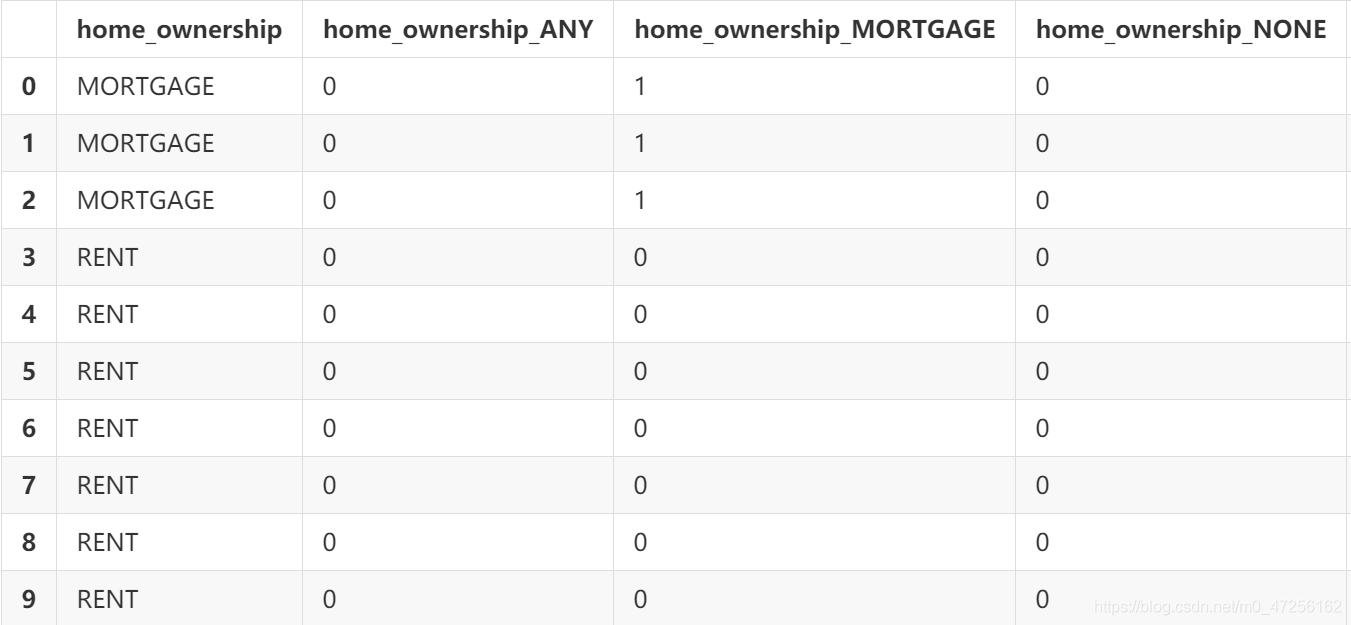
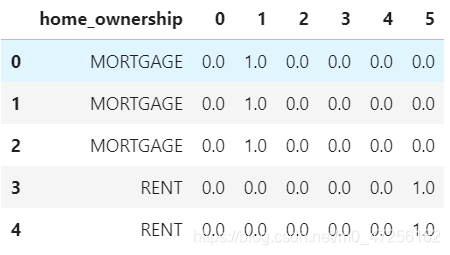
✌ 独热编码
homeDf=data['home_ownership'].to_frame() home_onehot=pd.get_dummies(homeDf,prefix='home') homeDf=pd.concat([homeDf,home_onehot],axis=1) homeDf.head()
from sklearn.preprocessing import OneHotEncoder homeDf2=data['home_ownership'].to_frame() home_onehot2=OneHotEncoder(categories='auto').fit_transform(homeDf2).toarray() homeDf2=pd.concat([homeDf2,pd.DataFrame(home_onehot2)],axis=1) homeDf2.head()
3.3 ✌ 特征交叉
前面所讲到的特征都为独立的类别特征或者是统计特征,其中不同的特征与特征之间还会联系,因此我们会对不同特征之间进行处理得到新的特征。
常用的特征交叉有:
- 数值特征之间
- 类别特征之间
- 数值特征与类别特征
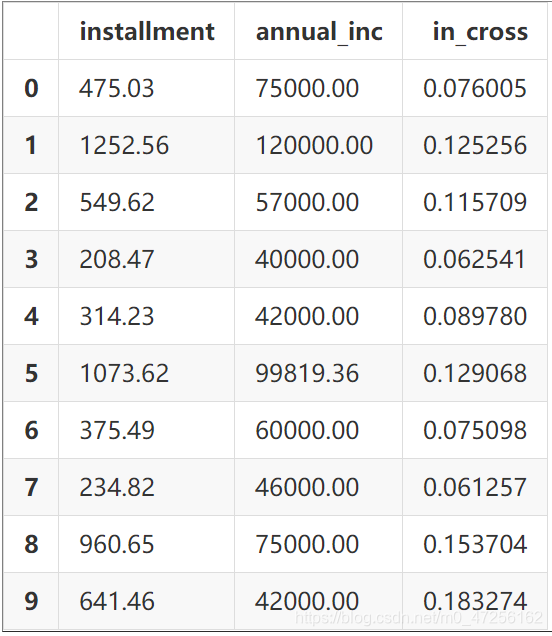
nuCrossDf = data[['installment', 'annual_inc']] monthly_inc = nuCrossDf['annual_inc'] / 12 nuCrossDf['in_cross'] = nuCrossDf['installment'] / monthly_inc 额占月收入的比例 nuCrossDf.head()
4、✌ 特征选择
特征选择是从特征集合中挑选一组具有明显物理或统计意义的特征子集,是一个去掉无关特征、保留相关特征的过程,其作用有简化模型、减少模型训练时间、降低模型过拟合风险等。
根据特征选择的形式,可以将特征选择的方法分为以下三种:
- 过滤法(Filter)
- 封装法(Wrapper)
- 嵌入法(Embedded)
4.1 ✌ 过滤法
过滤法根据发散性或相关性指标对特征进行评分,选择分数大于阈值的特征或分数最大的前k个特征。
常见的过滤法主要有以下几种:
- 方差选择法使用方差作为特征选择指标,方差越大则代表某列特征对区分样本贡献度越大。
- 皮尔逊(Pearson)相关系数使用Pearson系数作为特征选择指标,系数绝对值越大,相关性越强。
- 卡方(Chi2)检验使用卡方统计量作为特征选择指标,卡方值越大,相关性越强。
- 互信息法互信息系数法能够衡量各种相关性的特征集,计算相对复杂。
过滤法的特点是不依赖于机器学习算法,即先进行特征选择,再进行模型训练。其优点是简单易行、便于解释;缺点是没有考虑特征间的相互关系,对特征优化、提高模型泛化性等效果一般。
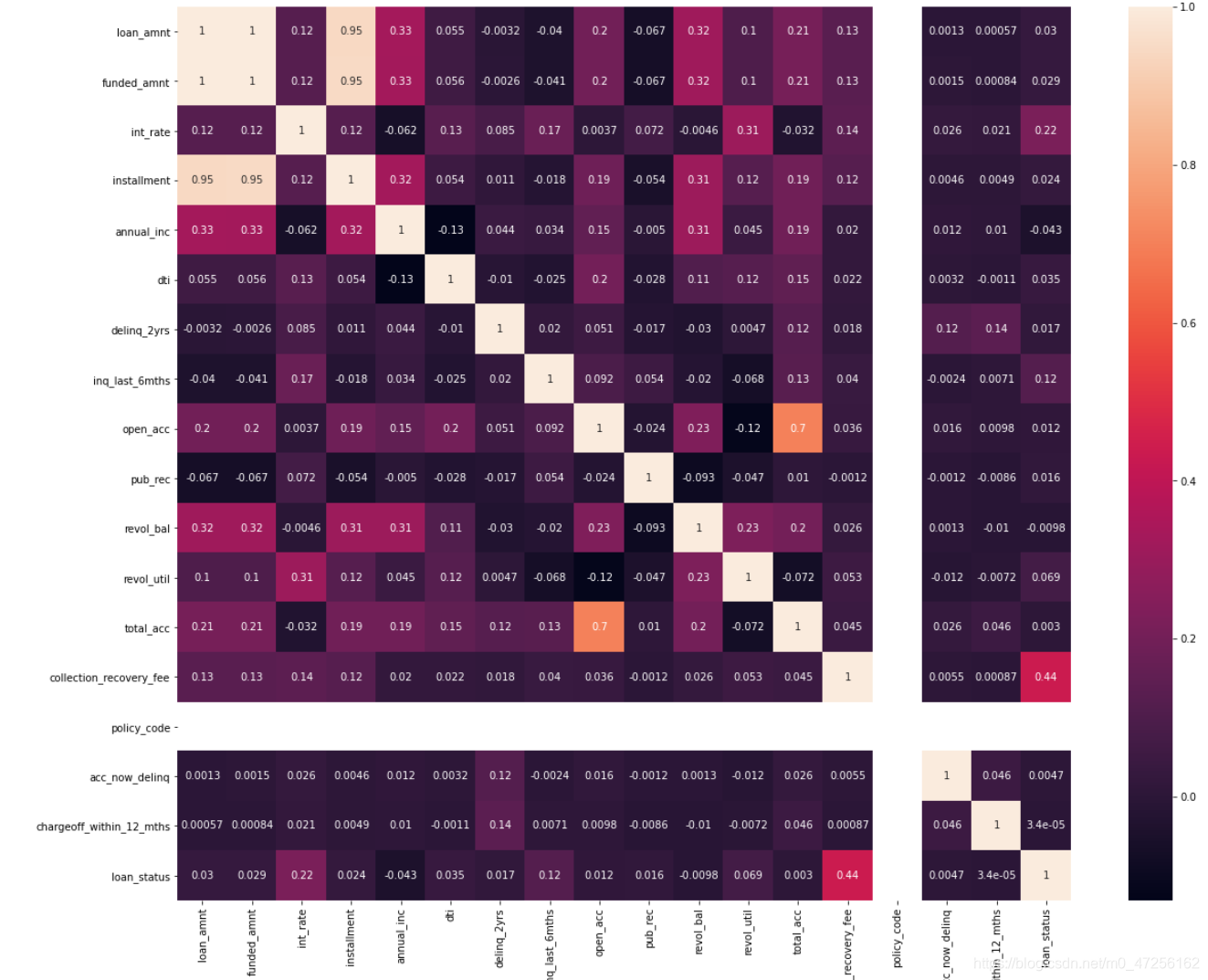
import seaborn as sns import matplotlib.pyplot as plt nu_fea=data.columns[(data.dtypes=='float64')|(data.dtypes=='int64')] nu_fea=list(nu_fea) pearson_mat=data[nu_fea].corr(method='pearson') plt.figure(figsize=(20,16)) sns.heatmap(pearson_mat,square=True,annot=True) plt.show()
4.2 ✌ 封装法
不同于过滤法,封装法直接使用机器学习算法进行特征选择。通过不断选取或排除特征,在验证集上测试模型的准确率,即根据目标函数衡量特征子集对目标变量的影响,寻找最优特征子集。
常用的封装法有以下几种:
前向搜索前向搜索的过程是从一个空的特征集合开始,逐步添加最优的特征到集合中。
后向搜索后向搜索从总的特征集合开始,逐步删除集合中剩余的最差特征。
递归特征消除法使用一个基模型进行多轮训练,每轮训练后消除若干权值系数的特征,在基于新的特征集合进行下一轮训练。
封装法的优点是与算法运行过程相结合,一般有着较高的准确性;缺点是计算量较大,每次进行特征变动时需要重新训练模型,消耗时间较长,且容易过拟合。
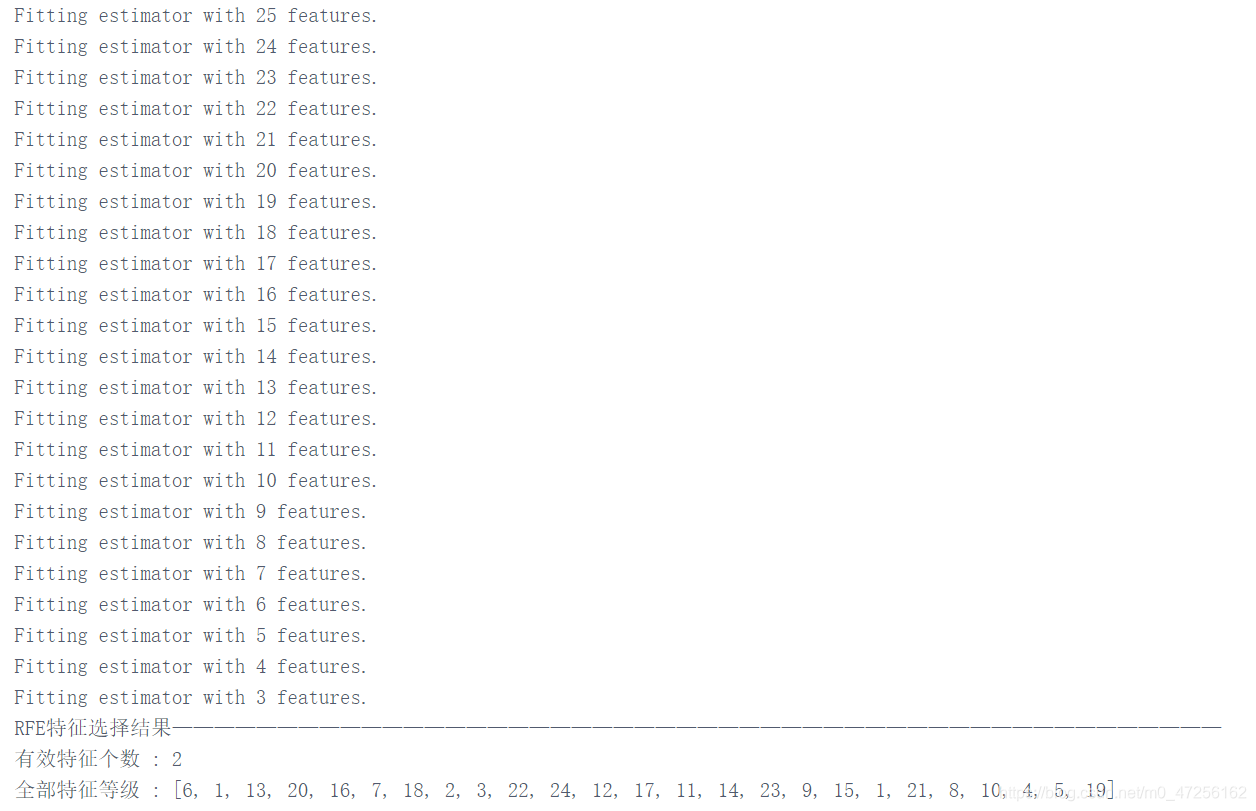
接下来的代码演示了递归特征消除法(RFE)。首先设定n_features_to_select( 经过特征选择后,特征集中剩余的特征个数),然后使用一个基模型(SVM model)来进行多轮训练,每轮训练后移除若干权值系数的特征,再基于新的特征集进行下一轮训练,直至特征个数为n_features_to_select。sklearn在feature_selection模块中封装了RFE。
from sklearn.datasets import make_classification X, y = make_classification(n_samples=1000, n_features=25, n_informative=3, n_redundant=2, n_repeated=0, n_classes=8, n_clusters_per_class=1, random_state=0) from sklearn.svm import SVC svc = SVC(kernel="linear") from sklearn.feature_selection import RFE rfe = RFE(estimator = svc, n_features_to_select = 2, step = 1, verbose = 1 ).fit(X,y) X_RFE = rfe.transform(X) print("RFE特征选择结果——————————————————————————————————————————————————") print("有效特征个数 : %d" % rfe.n_features_) print("全部特征等级 : %s" % list(rfe.ranking_))
4.3 ✌ 嵌入法
嵌入法是利用算法本身的特性,将特征选择嵌入到模型的构建过程当中,典型的有Lasso和树模型等。
常用的嵌入法有以下几种:
基于惩罚项的特征选择法可以使用L1或L2正则化进行特征选择。
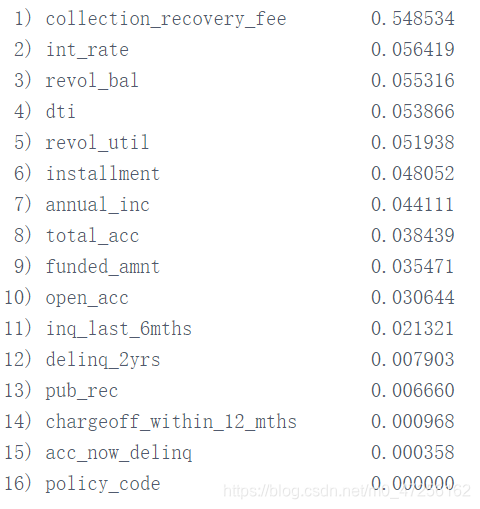
基于学习模型的特征选择很多机器学习算法自带特征重要性属性,根据特征在模型训练的每轮迭代中所起的作用来衡量,常见的是各种基于决策树的集成模型,如随机森林、GBDT、XGBoost等。
嵌入法计算的时间复杂度介于过滤法和封装法之间,优点是准确率较高,缺点是不是所有机器学习算法都能采用嵌入法。
from sklearn.ensemble import RandomForestClassifier cols = data.columns[(data.dtypes == 'float64') | (data.dtypes == 'int64')] cols = list(cols)[:-1] clf = RandomForestClassifier(n_estimators=100) clf.fit(data[cols], data['loan_status']) importance = clf.feature_importances_ indices = np.argsort(importance)[::-1] for f in range(data[cols].shape[1]): print("%2d) %-*s %f" % (f + 1, 30, cols[indices[f]], importance[indices[f]]))