
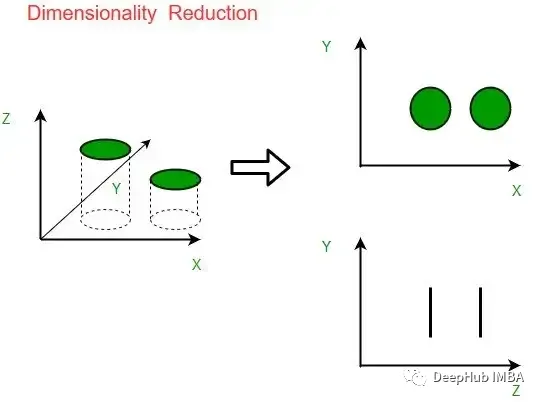
降维?
降低数据集中特征的维数,同时保持尽可能多的信息的技术被称为降维。它是机器学习和数据挖掘中常用的技术,可以最大限度地降低数据复杂性并提高模型性能。
降维可以通过多种方式实现,包括:
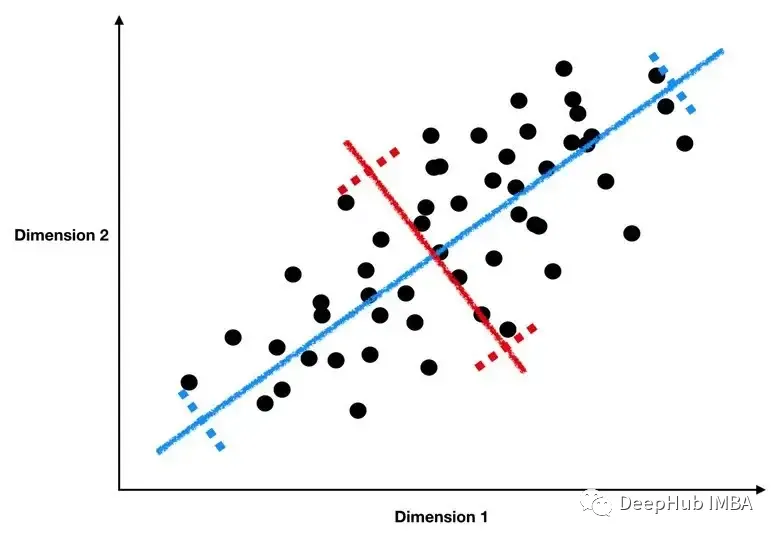
主成分分析 (PCA):PCA 是一种统计方法,可识别一组不相关的变量,将原始变量进行线性组合,称为主成分。
第一个主成分解释了数据中最大的方差,然后每个后续成分解释主键变少。PCA 经常用作机器学习算法的数据预处理步骤,因为它有助于降低数据复杂性并提高模型性能。
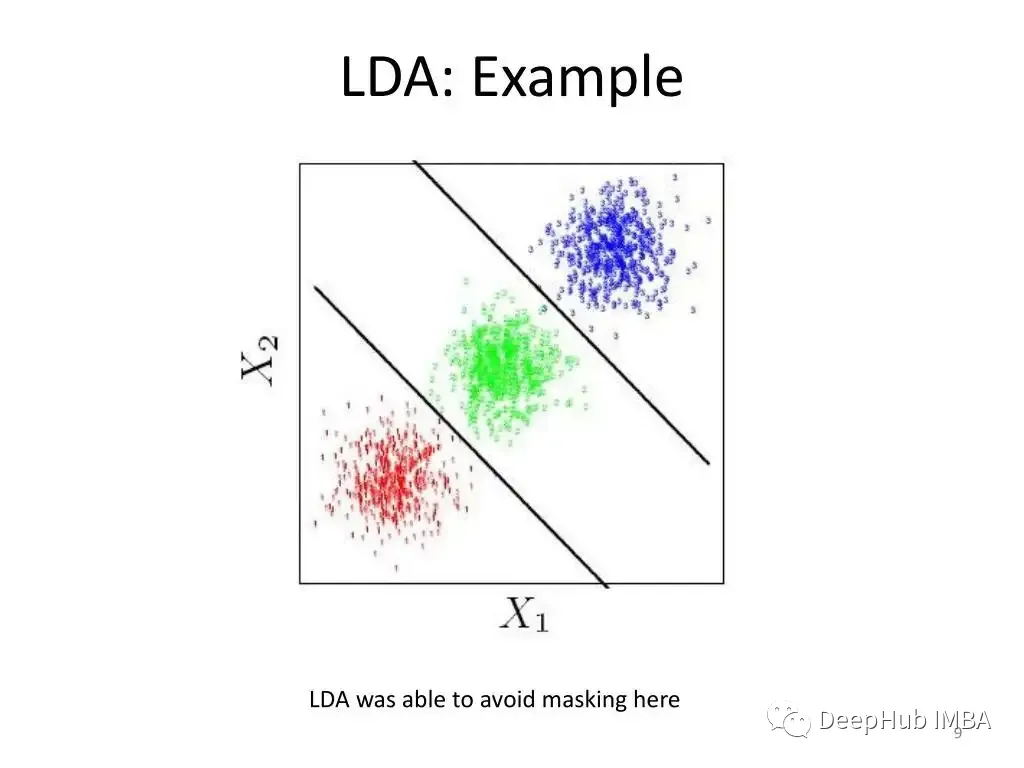
LDA(线性判别分析):LDA是一种用于分类工作的统计工具。它的工作原理是确定数据属性的线性组合,最大限度地分离不同类别。为了提高模型性能,LDA经常与其他分类技术(如逻辑回归或支持向量机)结合使用。
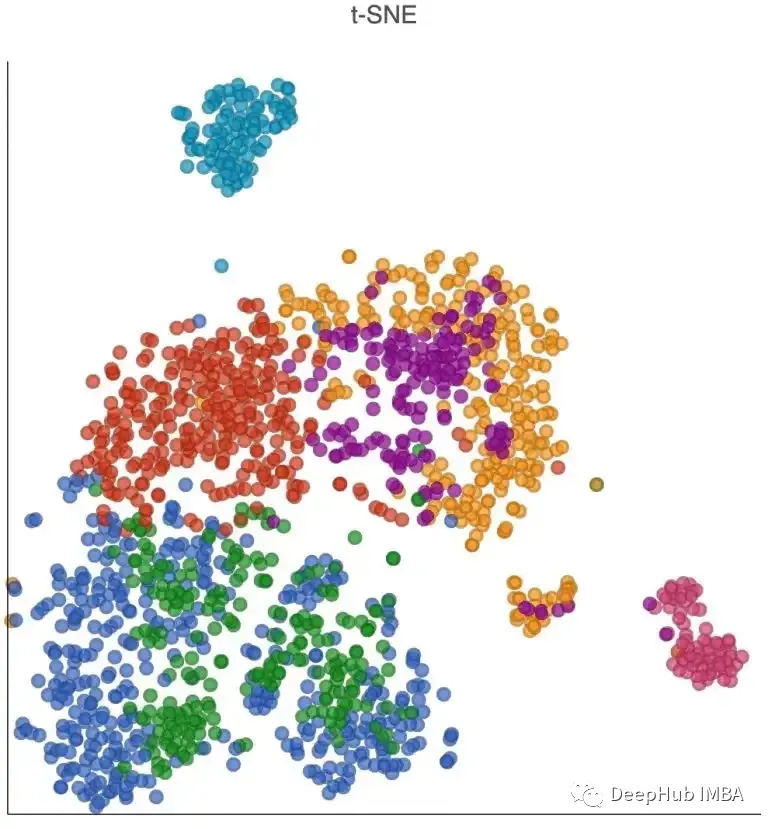
t-SNE: t-分布随机邻居嵌入(t-SNE)是一种非线性降维方法,特别适用于显示高维数据集。它保留数据的局部结构来,也就是说在原始空间中靠近的点在低维空间中也会靠近。t-SNE经常用于数据可视化,因为它可以帮助识别数据中的模式和关系。
独立分量分析(Independent Component Analysis) ICA实际上也是对数据在原有特征空间中做的一个线性变换。相对于PCA这种降秩操作,ICA并不是通过在不同方向上方差的大小,即数据在该方向上的分散程度来判断那些是主要成分,那些是不需要到特征。而ICA并没有设定一个所谓主要成分和次要成分的概念,ICA认为所有的成分同等重要,而我们的目标并非将重要特征提取出来,而是找到一个线性变换,使得变换后的结果具有最强的独立性。PCA中的不相关太弱,我们希望数据的各阶统计量都能利用,即我们利用大于2的统计量来表征。而ICA并不要求特征是正交的。如下图所示:
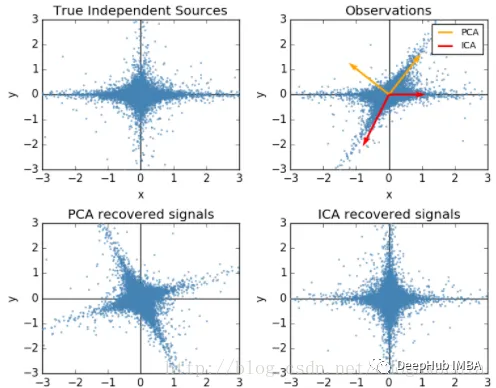
还有许多其他技术可以用于降维,包括多维缩放、自编码器等。技术的选择将取决于数据的具体特征和分析的目标。
特征选择?
在数据集中选择一个特征子集(也称为预测因子或自变量)用于机器学习模型的过程被称为特征选择。特征选择的目的是发现对预测目标变量(也称为响应变量或因变量)最相关和最重要的特征。
使用特征选择有很多优点:
- 改进的模型可解释性:通过降低模型中的特征量,可以更容易地掌握和解释变量和模型预测之间的关系。
- 降低过拟合的危险:当一个模型包含太多特征时,它更有可能过拟合,这意味着它在训练数据上表现良好,但在新的未知数据上表现不佳。通过选择最相关特征的子集,可以帮助限制过拟合的风险。
- 改进模型性能:通过从模型中删除不相关或多余的特征,可以提高模型的性能和准确性。
有许多可用的特征选择方法:
- 过滤方法:这些方法基于相关或相互信息等统计测量来选择特征。
- 包装器方法:这些方法利用机器学习算法来评估各种特征子集的性能,并选择最佳的一个。
- 嵌入方法:这些方法将特征选择作为机器学习算法训练过程的一部分。
所使用的特征选择方法将由数据的质量和研究的目标决定。为了为模型选择最优的特征子集,通常是尝试各种方法并比较结果。
降维与特征选择的区别
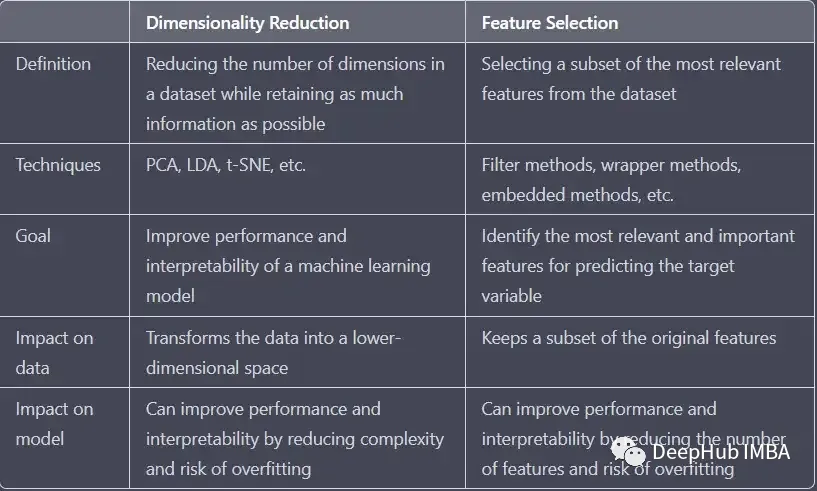
特征选择从数据集中选择最重要特征的子集,特征选择不会改变原始特征的含义和数值,只是对原始特征进行筛选。而降维将数据转换为低维空间,会改变原始特征中特征的含义和数值,可以理解为低维的特征映射。这两种策略都可以用来提高机器学习模型的性能和可解释性,但它们的运作方式是截然不同的。
https://avoid.overfit.cn/post/080bfade8cd046d5ad0523311d3b86ce
作者:Ankit Sanjyal
