
导语
云原生时代下,又一次掀起了 "Infrastructure as Code" 和 "DevOps" 运动的浪潮,当前已经不再局限于基础设施,而是万物皆可代码化,例如(排名不分先后):
- 架构即代码(Architecture as Code)
- 配置即代码(Configuration as Code)
- 环境即代码(Environment as Code)
- 基础设施即代码(Infrastructure as Code)
- 策略即代码(Policy as Code)
- 项目即代码(Project as Code)
- 安全即代码(Security as Code)
- ...
其中,安全即代码(Security as Code)从字面上看有点宽泛,但将其视为将安全操作自动地插入到软件生产的每个领域是非常有必要的。例如在开发与测试过程中,可能需要与其他系统交互,其中难免存在凭据和敏感信息的管理。同样的,在配置即代码(Configuration as Code)中,用户名、密码、API 令牌和 TLS 证书等,这些信息是非常常见的存在,但是这些包含对用户、用户组或实体进行身份验证和授权的机密数据,不应该被其他人知道或看到。
Secret Management
那么在 IaC 基础设施平台或者 GitOps 运维平台,在享受着声明式配置带来的便利的我们,该如何保证敏感信息的安全呢?答案就是:保证 Secret 安全的关键在于管理它们的方式。接下来我们一起来看下,在云原生领域推荐的几种敏感信息管理方案。
SealedSecret
SealedSecret 是一个管理 Kubernetes Secret 的方案,将 Secret 加密到 SealedSecret 资源中,它可以安全存储,即使在公共存储库中也是如此。SealedSecret 只能由目标集群中运行的控制器解密,其他任何人(包括原作者)都无法从 SealedSecret 中获得原始 Secret。
原理
SealedSecret 通过以下流程,完成加解密:
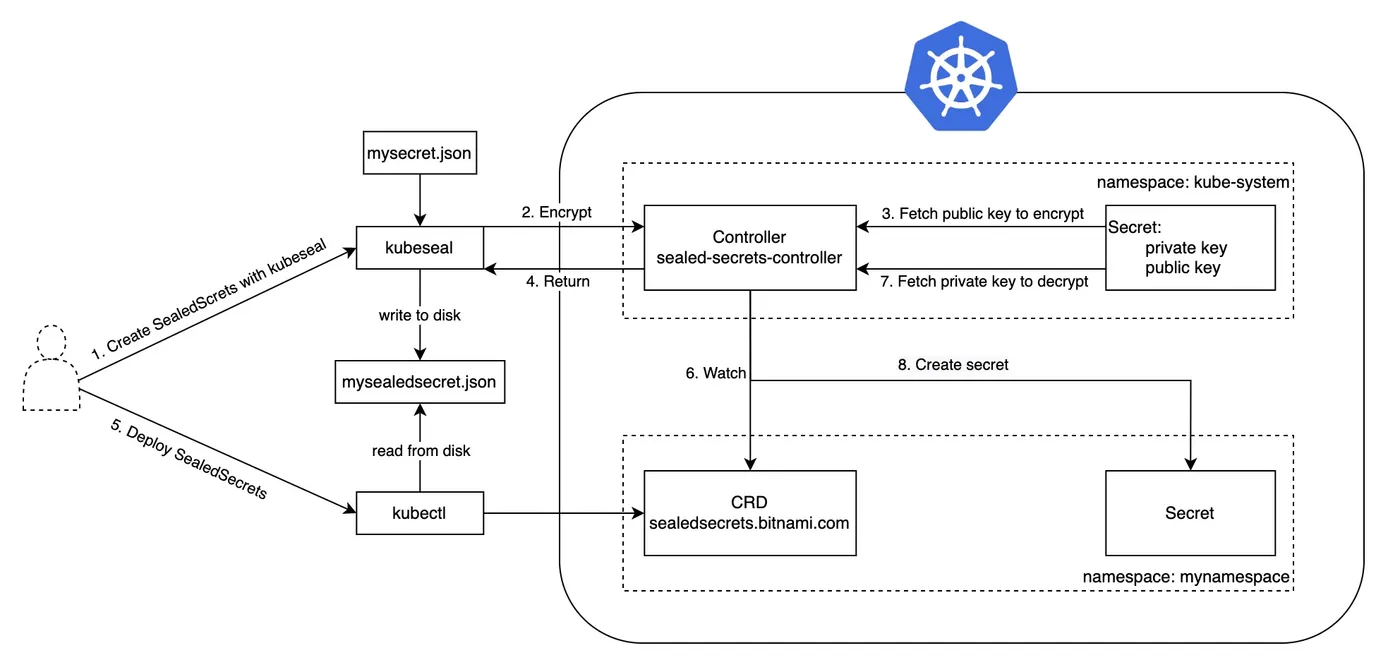
加密
- 用户使用 kubeseal 加密 mysecret.json
- sealed-secrets-controller 获取公钥
- 使用公钥加密,结果写入本地文件 mysealedsecret.json
解密
- 用户下发 SealedSecret 资源(mysealedsecret.json)
- sealed-secrets-controller 发现新对象,获取私钥
- 使用私钥解密,创建 k8s Secret 资源
小结
每个 SealedSecret 都使用其自己的随机非对称密钥加密,该密钥特定于 SealedSecret 名称和 Namespace。将加密数据复制粘贴到另一个 Secret 或另一个 Namespace 中将不起作用。
- ✅ 设置和使用简单
- ✅ Secret 文件统一管理
- ❎ 人工管理公钥,加密文件公开
- ❎ 不能在 Secret 之外使用(例如 ConfigMap)
Helm Secrets
Helm Secrets 是 Helm 的一个插件,能够利用 Helm 模板化 Secrets 资源。基于两种后端:
实现敏感信息管理,本质上是一个工具组合。
原理
Helm Secrets 是用 shell 脚本编写,使用的各个组件是需要用户提前安装,下面以 sops + gpg 为例,简要说明工作原理。
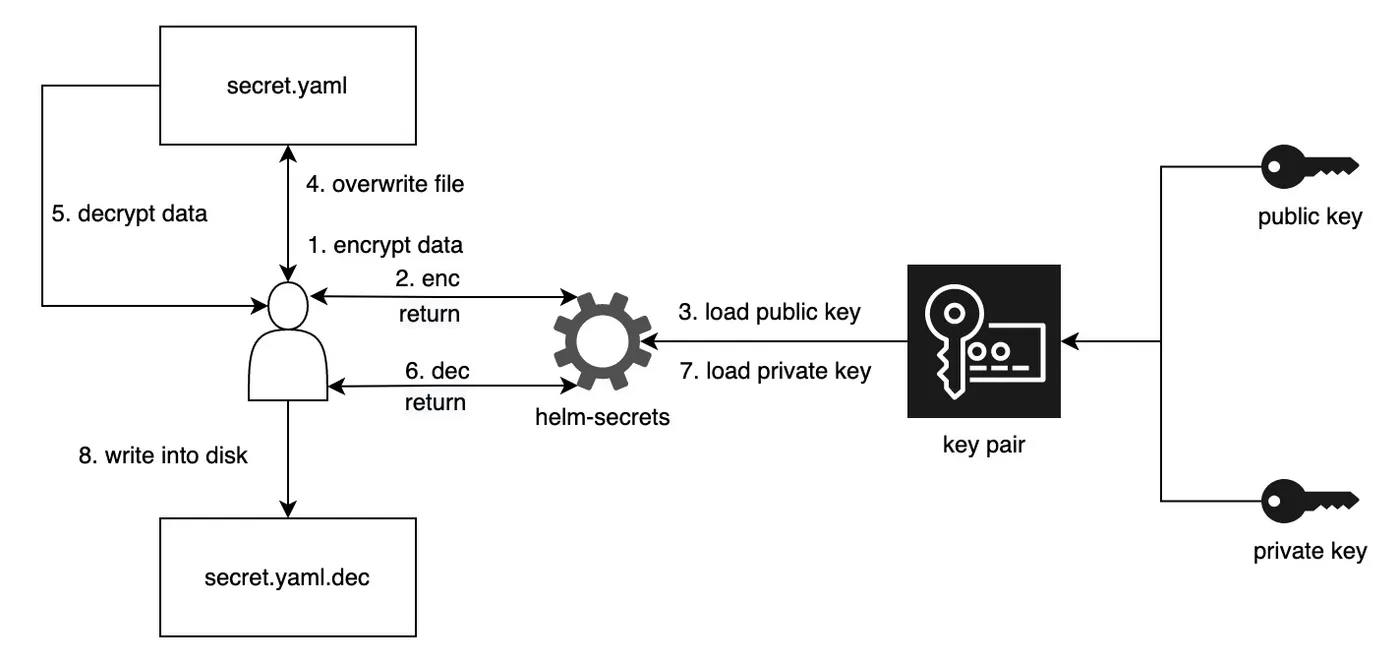
加密
- 用户通过
helm secrets enc命令触发 gpg 加密 secret.yaml - gpg 读取本地公钥
- 使用公钥加密,结果写入覆盖源文件 secret.yaml
解密
- 用户通过
helm secrets dec命令触发 gpg 解密 secret.yaml - gpg 读取本地私钥
- 使用私钥解密,结果写入到新文件 secret.yaml.dec
小结
Helm Secrets 支持多种加密方式,接除了 k8s Secret 的绑定关系,但是使用复杂,体感不太友好。
- ✅ 支持多种后端和加密方式
- ✅ Secret 文件统一管理
- ❎ 配置复杂
- ❎ 人工管理公钥,加密文件公开
External Secrets Operator
External Secrets Operator(ESO)是一个 Kubernetes Operator,它支持 AWS Secrets Manager、HashiCorp Vault、Google Secrets Manager、Azure Key Vault 等多种外部 Secret 管理系统。Operator 从外部 API 读取信息并自动将值注入 Kubernetes Secret。
ESO 的目标是将来自外部 API 的机密信息同步到 Kubernetes。ESO 是自定义 API 资源的集合:
- SecretStore:将身份验证/访问的关注点与工作负载所需的实际 Secret 和配置分开;
- ExternalSecret:声明要获取的数据。它引用了一个知道如何访问该数据的 SecretStore;
- ClusterSecretStore:是一个全局的、集群范围的 SecretStore,可以从所有命名空间中引用;
它们为外部 API 提供了一个用户友好的抽象,帮助用户存储 Secret 并管理它的生命周期。
原理
ESO 按照以下列方式同步 ExternalSecrets:
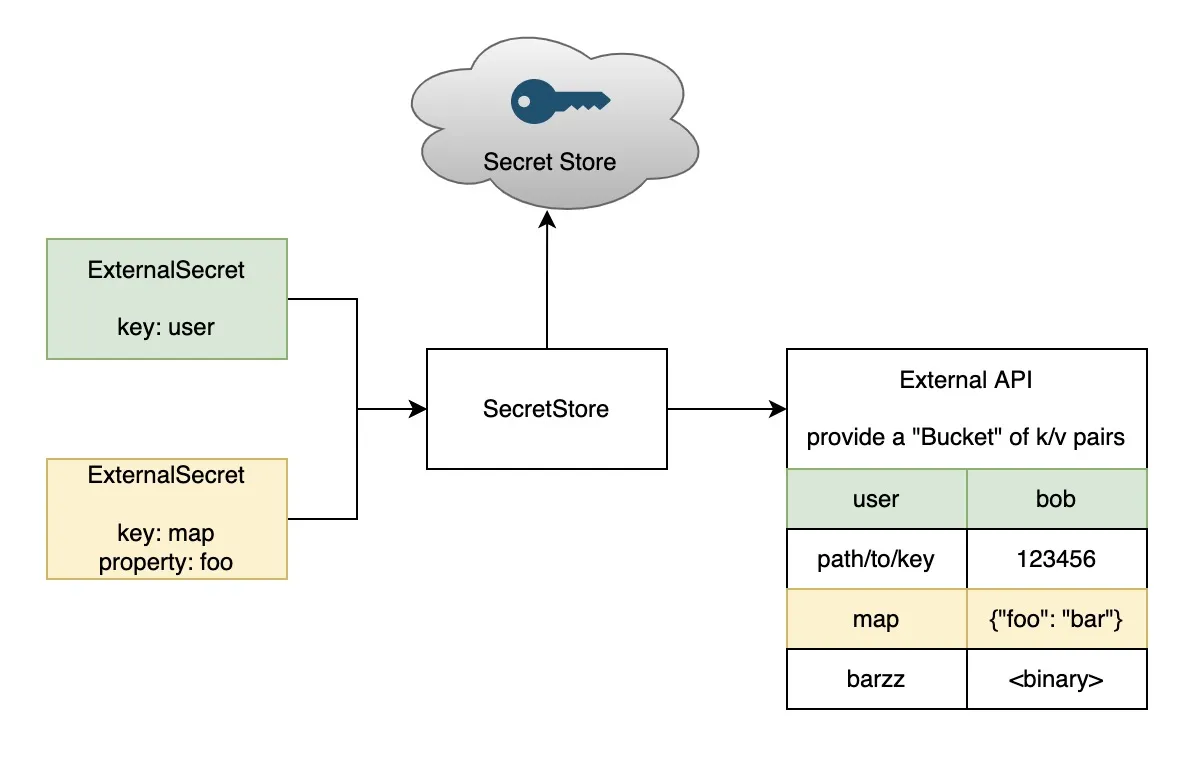
- 使用
spec.secretStoreRef来查找合适的SecretStore。如果不存在或spec.controller字段不匹配,将丢弃不再处理。 - 使用
SecretStore.spec的指定凭据实例化外部 API 客户端。 - 根据
ExternalSecret的要求获取敏感信息,如果有必要,将对敏感信息解码。 - 根据
ExternalSecret.target.template提供的模板创建Kind=Secret资源。可以使用来自外部 API 的敏感信息对Secret.data进行模板化。 - ESO 确保敏感信息与外部 API 保持同步。
小结
ESO 相对 SealedSecret,拓展了外部敏感信息管理系统的支持,但依旧是 k8s Secret 的管理方案。
- ✅ 支持多种外部 Secret 管理系统
- ✅ 敏感信息中心化管理,获取灵活
- ❎ 身份认证暴露
- ❎ 仅用于 Secret 资源
Secret Store CSI Driver
Secrets Store CSI Driver 通过容器存储接口 (CSI) 卷将 Secret 存储与 Kubernetes 集成。允许 Kubernetes 将外部机密存储中的多个 Secret、密钥和证书作为卷挂载到其 Pod 中。卷挂载成功后,其中的数据将被挂载到容器的文件系统中。
原理
Secret Store CSI Driver 管理敏感信息的原理下图所示:
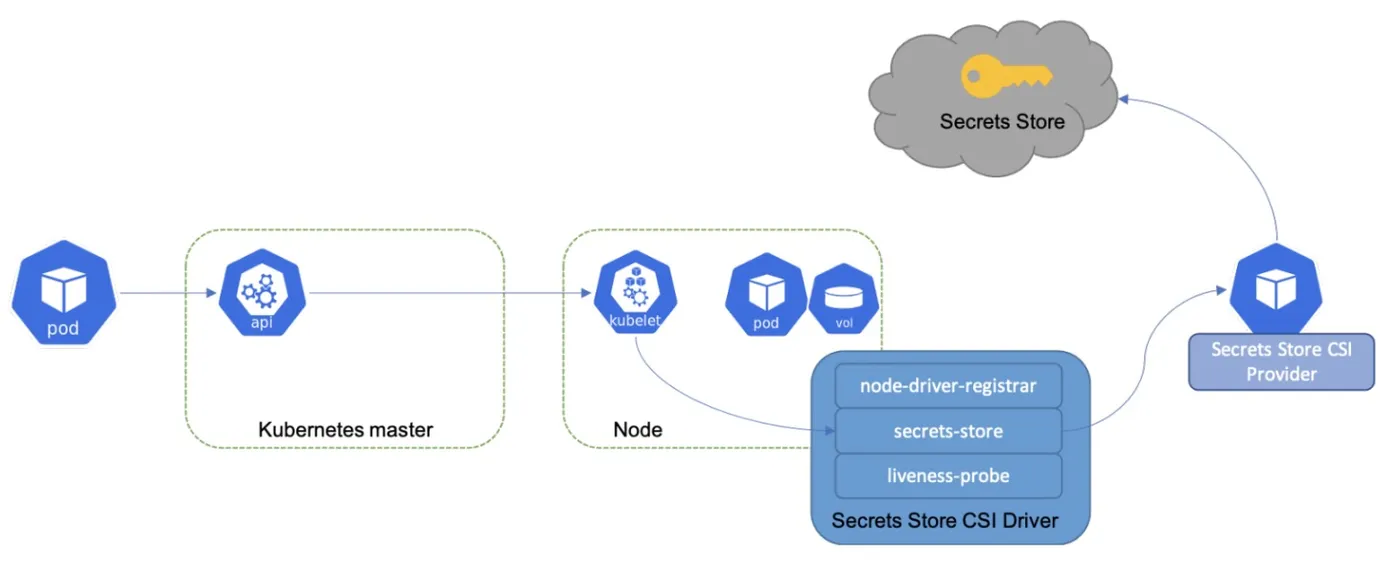
- 在 Pod 首次启动或重启时,Secrets Store CSI Driver 使用 gRPC 与 Provider 通信
- 从 SecretProviderClass 自定义资源中指定的外部 Secrets Store 检索敏感信息内容
- 将卷作为 tmpfs 挂载到 Pod 中,并将敏感信息写入该卷
- 在 Pod 被删除时,会清理并删除相应的卷
小结
Secret Store CSI Driver 与 ESO 方案类似,但挂卷不局限于 k8s Secret 资源,可扩展性更强。
- ✅ 支持多种 Provider
- ✅ 敏感信息中心化管理,获取灵活
- ❎ 身份认证暴露
- ❎ 卷挂载方式,应用需要增加文件读写相关逻辑
Secret as Code
根据以上各种解决方案的分析和总结,当前对于敏感信息管理基本可以分为两大类:
- 敏感信息加密
- 敏感信息托管
敏感信息加密
如果使用加解密的方案,那么有以下几个问题需要思考:
Q1:公私钥管理
如果加解密行为完全本地化,也就是使用了纯客户端方案,那么密钥管理就在本地存储,用户负责密钥管理;如果采用独立的加解密服务,密钥一般是该服务签发,用户只需要使用该服务提供的密钥管理能力即可。但同时也衍生另一个问题,就是如何管理访问该服务的身份认证信息,这也同样是敏感信息的管控。
Q2:解密行为触发
不论采用本地加解密还是独立的加解密服务,用户都是按需解密,因此这个行为是按需驱动;借用 GitOps 的概念,也就是 Push(“推”模式),而不是 Pull(“拉”模式)。
小结
如果采用加解密方案,建议使用独立的加解密服务,本地加解密更适用于产品的入门指南,以最小的代价获得最优的用户体验。而且在数据安全领域,永远有更专业的负责人和团队在提供支持;同时,对于产品化的演进,中心化管理也是必经之路。这里介绍一个 Google 开源的项目:go-cloud,它能让 Go 应用的开发在任何云提供商组合上无缝部署云应用程序。其中 secrets 包以可移植的方式提供对密钥管理服务的访问。
以下是使用 HashiCorp Vault 的 Secret Engine 加解密能力的代码片段(初始化+加密+解密):
初始化:
import (
"context"
"gocloud.dev/secrets"
_ "gocloud.dev/secrets/hashivault"
)
keeper, err := secrets.OpenKeeper(ctx, "hashivault://mykey")
if err != nil {
return err
}
defer keeper.Close()加密:
plainText := []byte("Secrets secrets...")
cipherText, err := keeper.Encrypt(ctx, plainText)
if err != nil {
return err
}解密 :
var cipherText []byte // obtained from elsewhere and random-looking
plainText, err := keeper.Decrypt(ctx, cipherText)
if err != nil {
return err
}敏感信息托管
如果使用托管的方案,同样的,也有几个问题需要思考:
Q1:托管服务的身份验证信息管理
托管服务负责保存敏感信息的原始数据,可以认为它就是一种数据库,形如各大云厂商提供的存储服务,例如:Azure Key Vault、AWS Secrets Manager 等,或者是 Gitlab Secret,都是可以安全存储敏感信息的服务。这些服务,无一例外,均需要身份验证,才可以使用。因此,托管服务的身份认证信息管理是首个要解决的问题。
Q2:敏感信息的引用格式
各个提供存取数据托管服务,也都会提供各自的存取方式。对于 IaC 基础平台或者 GitOps 运维系统来说,预先存入的敏感信息,提供一种真正 User-Friendly 敏感信息引用格式,避免大量的填入参数和晦涩难懂的组织形式,是以用户为核心的平台必须慎之又慎的事情。
Q3:敏感信息的取回
存入托管服务的敏感信息可以很方便,可以是 UI,也就是命令行。但是对于敏感信息的取回,无需人工介入是首要条件。各种托管服务的无一例外会提供自己的一套存取 API,或者是某种语言的 SDK。但哪怕只是通过 REST 接口对接主流云厂商的托管服务,都是一件耗时耗力的任务。
小结
如果采用托管服务,可以考虑在平台侧提供默认的托管服务,同时保持开放性,陆续支持其他主流云厂商的 Secret Manager。对接多个托管服务,可以参考 vals 项目,它是一个开源的管理敏感信息配置的框架,同时支持多种后端服务,例如:Vault、AWS Secrets Manager、GCP Secrets Manager、Azure Key Vault、EnvSubst、GitLab Secrets 等。并且针对不同的后端,它的引用格式在设计上始终遵循 URI 风格。
以下是借助 HashiCorp Vault 的托管能力,取回敏感信息的代码片段:
import "github.com/variantdev/vals"
secretsToCache := 256 // how many secrets to keep in LRU cache
runtime, err := vals.New(secretsToCache)
if err != nil {
return nil, err
}
valsRendered, err := runtime.Eval(map[string]interface{}{
"inline": map[string]interface{}{
"foo": "ref+vault://secret/foo?proto=http&&host=127.0.0.1:8200#/foo",
"bar": map[string]interface{}{
"baz": "ref+vault://secret/bar?address=http://127.0.0.1:8200#/bar",
},
},
})总结
在 Anthos architecture foundations and principles 一文中提到:“行业普遍接受的最佳实践是将敏感信息排除在源码之外,并通过文件、环境变量或使用配置拉取方法将秘密注入应用程序”。因此更推荐使用敏感信息托管服务,但仍然需要明确一点,并不存在一个能够解决所有问题的万能方案。任何方案的技术选型,背后都有着不同业务需求。因此基于场景基于需求,设计一个适合的方案,才是“最好”。
参考链接
- How to keep your Kubernetes secrets secure in Git
- https://github.com/bitnami-labs/sealed-secrets
- https://github.com/jkroepke/helm-secrets
- https://github.com/external-secrets/external-secrets
- Managing Kubernetes Secrets with the External Secrets Operator
- https://github.com/kubernetes-sigs/secrets-store-csi-driver
- https://secrets-store-csi-driver.sigs.k8s.io/
- GitOps and Secret Management with Kubernetes CSI-Secret-Store on Azure
- https://gocloud.dev/howto/secrets/






