
本节书摘来自华章社区《Python数据科学实践指南》一书中的第2章,第2.1节应当掌握的基础知识,作者纪路,更多章节内容可以访问云栖社区“华章社区”公众号查看
2.1 应当掌握的基础知识
本节会介绍一些学习Python前应当掌握的基础知识,这一部分内容在所有的编程语言学习中基本上都是类似的,Python当然也遵守这些通用的规则,熟悉这些内容的读者可以跳过这一节。
2.1.1 基础数据类型
首先,需要明确的是,在Python中,所有的元素都是“对象”。“对象”是计算机科学中的一个术语,本书以后的章节会对其进行介绍,现在读者只需要将对象等同于“东西”就好了。既然是一种东西,那么就要对其进行分类,所有对象都要归属于某个“类型”,比如猫属于动物,电视属于电器,床属于家具等。从这个比喻来看,对象是一个具体的事物,而类型则是一个抽象的分类,并且同一类型的东西总是有很多相似之处,比如动物需要吃东西,可以自由移动,或者趴在你的键盘上妨碍你打字(开玩笑的)。虽然本章并不打算介绍“面向对象”,但还是想强调一下“对象”是Python程序处理的核心事物,而且每个对象都有它所归属的类型,最终会由类型决定Python程序可以对这个对象做什么。
Python有如下5种基本的数据类型。
None:这个类型表示什么都没有,这是一个特殊的类型,并且也仅有None这一个对象。
int:表示整数的类型,比如1、2、3、4这样的数字就是int型,当然,负数–1、–2、
–3、–4等也都在int的范围之内,范围等同于数学定义中的整数。
float:代表浮点数,比如1.2,4.5或–72.1,当所要表达的数字过大或过小时可能会用科学计数法来表示,比如1.6E11代表1.6×1011这样的大数。而且1.0或–2.0这样的数也叫作浮点数,虽然它们的值与去掉小数点及后面的0之后的值看起来是相等的,但是它们是不同的类型,Python程序可以对它们做的事情也不一样。比如下面这一小段程序:
jilu:~:% python
Python 2.7.9 (v2.7.9:648dcafa7e5f, Dec 10 2014, 10:10:46)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> 2 == 2.0
True
>>> 2 is 2.0
False
>>> type(2)
<type 'int'>
>>> type(2.0)
<type 'float'>
>>> bool:表示布尔类型的值,可能有的读者听说过布尔值只有两个,非0即1,在Python中使用False代表0,True代表1,上面的一小段代码试图判断2与2.0之间值的大小时,Python程序的结果是True,而在判断2是不是2.0时返回的却是False。
str:代表字符串类型,比如“Hello World”就是一个str类型。严格来说,在Python 2中还有一个unicode类型几乎与str类型没有任何区别。并且str类型也不是原子类型,而是由多个字符组成的序列类型。实际上str类型并不是基础数据类型,可实际上几乎没有程序能够完全不使用字符串类型的对象(即使是第1章中的示例程序,也用到了字符串类型的对象,那个时候读者也许还不知道什么是对象,就已经知道“Hello World”是字符串了),所以这里将str划为基础数据类型。
现在,我们已经介绍了Python的5个基本类型,接下来就让我们对它们做一些事情。
2.1.2 变量和赋值
在Python中我们可以随意为对象起一个名字,甚至起好几个名字,比如下面的语句:
>>> USD_to_CNY = 6.4855
>>> dollar_rate = USD_to_CNY
>>> dollar_rate = USD_to_CNY = 6.4855第一条语句用于将字面量为6.4855的浮点型对象赋值给USD_to_CNY变量;第二条语句是通过变量USD_to_CNY将6.4855传递给了另外一个变量dollar_rate;第三条语句则是前两条的合体。这里需要强调的是,在Python里所有的赋值操作都是起一个别名,对象还是最原始的对象,这种方式叫作引用传递。Python中有一个id()方法,可以将某个对象在Python内部的唯一编号打印出来,为了证明这一点,一起来看一下下面的代码及输出:
>>> id(6.4855)
4302308792
>>> dollar_rate = USD_to_CNY = 6.4855
>>> id(dollar_rate)
4302308792
>>> id(USD_to_CNY)
4302308792
>>> id(6.4855)
可以看到无论是原始的变量还是它的两个别名,它们的对象ID都是相同的。如果我们为一个变量重新赋值,那么与这个变量对应的对象ID就会改变,比如:
>>> dollar_rate = 5.5
>>> id(dollar_rate)
4302308816虽然,变量仅仅是一个名字,但是想起一个好的名字并不容易。真正的程序员在工作中无时无刻不面临着如何给某个对象找一个简单直白的名字,如果起了一个有误导性质的名字,结果很可能是灾难性的。比如,一个粗心的程序员将美元汇率(USD)写成了欧元汇率(EUR),那么这家公司可能会因为给顾客兑换更多的人民币而破产。Python的书写规范(EPE8)中,详细地规定了该如何书写名称,本书仅做一些必要的约定:名称应该是能表达实际含义的名词,由字母、数字及下划线组成,但不能以数字开头。还要注意的是,不要使用Python的保留字,因为这些单词是程序得以顺利执行的基础,它们有一些特定的含义,以下是Python 2.7中的保留字:
and del from not while
as elif global or with
assert else if pass yield
break except import print
class exec in raise
continue finally is return
def for lambda try
关于赋值,最后还有一点需要说明,即Python支持多重赋值,如果读者有过C/C++编程的经验,可能对下面的语句不会陌生:
x = 1
y = 2
z = x
x = y
y = z
在比较有历史的编程语言里,要交换两个变量的值只能通过一个中间变量来实现,而在Python中可以方便地写成:
>>> x = 1
>>> y = 2
>>> x, y = y, x在Python中这种赋值方式称为列解包,后这将会在讲解序列类型时再次提及序列解包。
2.1.3 操作符及表达式
Python中有一系列的操作符,操作符可用来连接两个对象的符号,比如“+”号操作符连接两个数字就可以组成一个表达式,而且表达式的值也是对象,下面列出了Python的全部操作符:
算术操作符: +、-、、*、/、//、%
位操作符: <<、>>、&、|、^、~
比较操作符: <、>、<=、>=、==、!=
逻辑操作符: and、or、not
算术操作符:用来进行算术操作。值得注意的是,Python中的算术操作符是自动重载的,对于int类型的两个对象,“+”代表求和。而对于str类型的两个对象,“+”就会变成连接两个字符串,比如:
"abc" + "dfe"
abcdef
对于该符号,本章后面讲解字符串时会做进一步讲解。
位操作符:Python的位操作符是进行位运算的,比如将一个整数右移的计算“1234 >> 1”,因为本书并不会涉及位运算,感兴趣的读者可以自己找一些资料来学习。
比较操作符:这个操作符就很好理解了,不过值得注意的是,比较操作符也是经过重载的,在比较字符串的类型时,是按照字母的字典顺序进行比较的,比如“a”< “b”。含有比较操作符的表达式,其表达式的值是布尔型,比较条件成立时为True ,不成立时为False。
逻辑操作符:and表示操作符两侧的值(表达式的值或对象的值)全部等同于True时,结果就是True。or只需要操作符两侧的值有一个为True就为True 。not就如字面意思一样,会逆转Ture和False的值,比如not True的结果是False,反之亦然。
最后,需要注意的是,编程与数学计算一样,操作符是有优先级的,比如号就要优先于+运算,实际的处理办法也与数学中的相同,可以使用圆括号()来将想要优先运算的部分括起来。比如(1 + 2)3就会先计算加法再计算乘法。
2.1.4 文本编辑器
使用Python的交互式命令行是非常便捷的编程方式,但是当需要编写的程序比较多时,程序员应使用更好的工具来管理代码。为简便起见,本章暂时还不会介绍IDE(Integrated Development Environment,集成开发环境),刚入门编程的读者最好还是从普通的纯文本编辑器开始入手。
可能有不少读者常用的编辑文本的软件是Office World、Windows记事本,或者Mac上的pages、备忘录,又或者是跨平台的印象笔记等。这些软件可以叫作文本编辑器,但是却不能叫作纯文本编辑器。因为这些软件为了方便排版,除了实际显示的文本之外,还有很多特殊的隐藏字符用来表示格式。任何代码文件都应当以纯文本的方式来保存,所以这里推荐两款适用于编程的纯文本编辑器—Sublime Text 3和Notepad++。
- Sublime Text 3
Sublime Text 3是首选,这是一款免费的、跨平台的纯文本编辑软件,在Mac OS X、Windows、Linux里都有对应的版本,图2-1是Sublime Text 3运行时的截图。
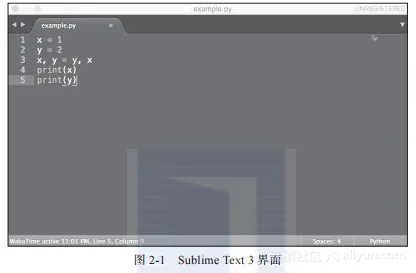
从图2-1中可以看到,Python代码的不同部分被标注成了不同的颜色,这是因为我将文件保存成example.py的文件了。“.py”是Python程序的扩展名,正确的Python程序必须以.py结尾,这样编辑器和Python解释器才能够正确识别。
- Notepad++
Notepad++是一款专门为Windows设计的纯文本编辑器,同样也是免费的,而且有一批忠实的用户在使用,有兴趣的读者可以去了解一下,图2-2是Notepad++的软件界面。
以上两个软件的功能很相似,都能够满足我们目前的需求,安装方式也与其他应用程序的安装方式一致,这里就不再赘述了。再提醒一次,使用Windows的用户一定不要使用Windows记事本打开Python程序文件,因为记事本会向纯文本文件每一行的末尾插入一个Windows特有的标记,平时看不见,但它会导致程序运行失败。
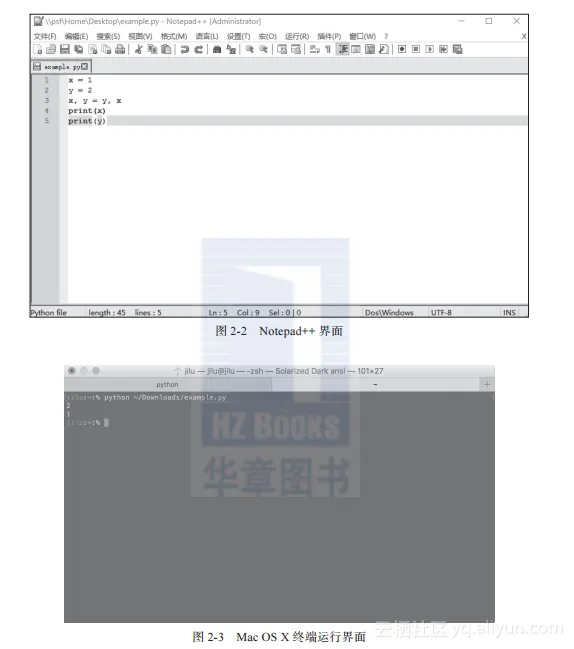
在安装编辑器之后,输入适当的Python代码,保存为以“.py”结尾的Python程序文件之后,就可以通过在命令行中输入“python+程序文件路径”的方式运行了,在Mac OS X中的截图如图2-3所示。
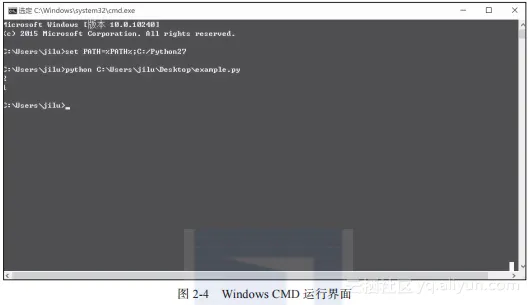
在Windows中的截图如图2-4所示。
通常,Python程序文件的头部会添加两行特殊的字符串,如代码清单2-1所示。
代码清单2-1:
example.py
# ! /usr/bin/python
# -*- coding: utf-8 -*-
x = 1
y = 2
x, y = y, x
print(x)
print(y)其中第一行在Windows系统当中没有意义,这是专门给Python代码在Mac OS X或Linux上运行的用户使用的。第二行对于非英文用户是比较关键的,它说明了程序文件是以utf-8编码保存的,中文和其他非ASCII字符的文字需要以这种方式保存在Python程序中。另外由于Python shell只能输入ASCII字符,所以通过编写Python程序文件也可以实现对中文的处理,比如代码清单2-2。
代码清单2-2:
hello.py
# ! /usr/bin/python
# -*- coding: utf-8 -*-
print("你好,世界")
在Mac OS X终端上执行之后的结果是:
jilu:~:% python ~/Downloads/hello.py
你好,世界Windows命令行执行的命令是“python C:UsersjiluDesktophello.py”,在本书以后的章节里,如果提到运行Python程序,则表示是在终端或命令行中使用python命令调用代码清单,我会直接给出代码清单和运行结果,而省略运行的步骤。
这里还有一些小技巧可以帮助读者快速地输入代码清单的存储路径,即无论在何种操作系统下,都可以通过鼠标拖曳代码清单的文件到命令行里,命令行中会自动打出该文件的路径,之后就只需要再补充python命令即可。

