










Flink 双流 Join 的3种操作示例
在数据库中的静态表上做 OLAP 分析时,两表 join 是非常常见的操作。同理,在流式处理作业中,有时也需要在两条流上做 join 以获得更丰富的信息。Flink DataStream API 为用户提供了3个算子来实现双流 join,分别是:1、join();2、coGroup();3、intervalJoin()

AI·OS新探索:端到端算法工程平台
本话题将围绕深度算法学习工程,详细介绍在淘宝搜索,推荐,广告业务的最佳实践,和大家详细阐述,阿里是如何构建一个高效的端到端AI算法平台。

Elasticsearch 场景化检索及全观测运维介绍
基于Elasticsearch场景化检索及全观测运维解决方案的介绍,内容包括Elasticsearch产品介绍,电商零售分析检索能力与解决方案,以及在线教育全观测运维监控能力与解决方案。

【最佳实践】阿里云Logstash JDBC实现Elasticsearch与关系型数据库保持数据同步
为了充分利用阿里云 Elasticsearch 提供的强大搜索功能,很多公司都会在关系型数据库的基础上,部署 Elasticsearch。这种情况下,则需要确保 Elasticsearch 与所关联关系型数据库中的数据保持同步。 在本篇博文中,我会演示如何使用 Logstash 高效复制数据,将关系型数据库阿里云 RDS 中的数据更新同步到 Elasticsearch 中。

有赞实时任务优化:Flink Checkpoint 异常解析与应用实践
本文结合 Flink 1.9 版本,重点讲述 Flink Checkpoint 原理流程以及常见原因分析,让用户能够更好的理解 Flink Checkpoint,从而开发出更健壮的实时任务。
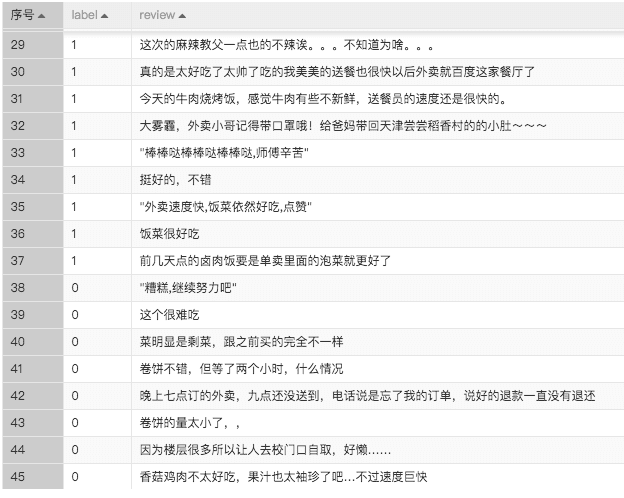
基于外卖评论的舆情风控
目前许多商家都有线上留言或者评论反馈平台,消费者可以在这些平台上通过留言表达自己对于消费商品的反馈。消费者的反馈包括表扬性的正向反馈,也有一些批评性质的负向反馈。商家需要掌握消费者对于产品的整体舆论取向来判断自己的产品质量是否符合消费者需求,同时了解评论内容可以方便商家分析舆论导向,指导下一步产品研发工作。
读透《阿里巴巴数据中台实践》,其到底有什么高明之处?
最近阿里巴巴分享了《阿里巴巴数据中台实践》这个PPT(自行搜索原始文章),对于数据中台的始作俑者,还是要怀着巨大的敬意去学习的,因此仔细的研读了,希望能发现一些不一样的东西。 读这些专业的PPT,实际是非常耗时的,你需要把这些PPT外表的光鲜扒光,死抠上面的每一个字去理解底下隐藏的含义,然后跟你的已有知识体系去对比,看看是否有助于完善自己的认知,对于自己不理解的,还需要经常去检索相关的文档。

Apache Flink 零基础入门(四):客户端操作的 5 种模式
本文主要分享 Flink 的 5 种任务提交的方式。熟练掌握各种任务提交方式,有利于提高我们日常的开发和运维效率。
解决MaxCompute SQL count distinct多个字段的方法
按照惯性思维,统计一个字段去重后的条数我们的sql写起来如下: Distinct的作用是用于从指定集合中消除重复的元组,经常和count搭档工作,语法如下 COUNT( { [ DISTINCT ] expression ] | * } ) 这时,可能会碰到如下情况,你想统计同时有多列字段重复的数目,你可能会立马想到如下方法: select count( distinct col1 , col2 , col3 , .......) from table 但是,这样是有问题的,如果值包含空,那么我们的结果是什么呢?如果你实验过,正如你实验的一样,结果会比实际少。
SparkSQL Catalyst解析
Catalyst Optimizer是SparkSQL的核心组件(查询优化器),它负责将SQL语句转换成物理执行计划,Catalyst的优劣决定了SQL执行的性能。
使用 MaxCompute Studio 开发大数据应用
MaxCompute(原ODPS)是阿里云自主研发的分布式大数据处理平台。MaxCompute Studio 为开发者提供了良好的开发体验,本文将展开进行介绍。
市场调研:智能体助力,智创未来客户转化率提升 70%
在CAC飙升时代,传统MA难破转化瓶颈。智能体(Agent)以意图识别、情绪共鸣、24/7个性化服务与工具调用能力,实现从“骚扰”到“服务”的跃迁,实测转化率提升70%+,打造触达→成交无缝闭环。(239字)
赶快体验!智能体来了,一起智创未来温馨生活
科技不止算力与参数,更该有温度。AI智能体正悄然融入生活:感知情绪、预判习惯、代管琐事,把人从重复决策中解放,腾出时间陪伴家人。它不是冰冷工具,而是懂你的“数字家人”。(239字)
零代码基础也能懂的LoRA微调全指南
LoRA(低秩适应)让普通人也能用消费级显卡高效微调大模型。它不改动原模型,仅添加小型“适配模块”,以0.1%-1%的参数量实现接近全量微调的效果,快速打造专属AI助手,推动AI民主化。
构建AI智能体:八十三、当AI开始“失忆“:深入理解和预防模型衰老与数据漂移
AI模型会因数据分布变化和时间推移而性能下降,即“模型衰老”与“数据漂移”。如同知识过时,旧模型难以适应新环境,导致预测不准。需通过PSI、KS等指标监测,并定期重训练以保持其有效性。
IDEA开发常用的快捷键
IntelliJ IDEA常用快捷键汇总:涵盖代码生成(如main、sout)、编辑(复制、删除、重命名)、导航(跳转、查找)、格式化、代码阅读及版本控制等高频操作,提升开发效率。熟练掌握可显著优化编码体验,是Java开发者必备技能。
MySQL 为何能稳居开源数据库主流宝座
MySQL自1995年发布以来,凭借轻量高效、易用友好、生态完善和灵活扩展四大优势,长期稳居开源数据库榜首。其低门槛部署、丰富工具链、广泛技术适配与平滑扩展能力,满足从个人项目到企业级应用的全场景需求,成为Web开发首选数据库。
MySQL 开发进阶:从初级到数据库工程师的能力提升路径
本文系统梳理MySQL开发从初级到数据库工程师的四阶段进阶路径:从规范表结构设计、掌握三大范式,到搭建主从复制与读写分离架构保障高可用,再到通过分库分表、参数调优应对大数据量性能瓶颈,最后强调业务驱动、实践复盘与技术沉淀,助力开发者实现职业跃迁。
Vue项目性能优化实战:从编码到部署的全链路优化方案
本文系统梳理Vue项目从编码到部署的全链路性能优化方案,涵盖组件设计、响应式优化、构建压缩、CDN加速、运行时监控等关键环节,结合实战代码,助力提升页面加载速度与交互流畅度。
大模型推理与应用术语解释
简介:大语言模型核心技术涵盖推理、生成式AI、检索增强生成(RAG)、提示工程、上下文学习、代理、多模态学习与语义搜索。这些技术共同推动AI在内容生成、知识检索、智能决策和跨模态理解等方面的能力跃升,广泛应用于问答系统、创作辅助、企业服务与自动化任务,正重塑人机交互与信息处理范式。(238字)
AgentScope x RocketMQ:构建多智能体应用组合
AgentScope是阿里巴巴推出的开发者友好型多智能体框架,支持模块化、可定制的智能体应用开发。通过集成RocketMQ,实现高效、可靠的A2A通信,助力构建如“智能旅行助手”等复杂协作场景,提升开发效率与系统可扩展性。(238字)
AgentScope x RocketMQ:构建多智能体应用组合
AgentScope是阿里巴巴推出的开发者友好型多智能体框架,支持模块化、可定制的智能体应用开发。通过集成RocketMQ,实现高效、可靠的Agent间通信,助力构建如“智能旅行助手”等复杂协作场景,推动多智能体生态发展。(238字)
Hoobuy模式复制指南:淘宝1688代购系统搭建
Hoobuy以“价格套利+信息差变现”为核心,连接海外消费者与1688源头厂家,提供30%-50%低价优势,覆盖全品类商品。通过商品差价、服务费与物流收益盈利,目标用户为追求性价比的都市白领及中小跨境卖家。平台集成多语言、多币种、一键代购与物流追踪系统,依托PHP技术实现高效运营,结合社媒营销与物流优化,打通跨境购物全链路。(239字)
实用程序:基于Python+Tkinter开发表格比对&整理工具
一款基于Python+Tkinter开发的免费开源Excel处理工具,支持表格差异比对与错乱行整理,完整保留图片,兼容.xlsx和.csv格式。操作简单,支持自定义比对列、多线程处理,解决日常办公中数据比对、行合并及图片丢失等痛点,适用于各类Excel数据清理场景。(239字)
闲鱼商品列表API完整指南
闲鱼商品列表API(goodfish.item_search)支持通过关键词、分类、价格等条件搜索商品,返回JSON格式数据,适用于比价工具、数据分析、推荐系统等场景。
手机端网站建设:响应式设计主导下的工具选取与实施步骤
移动互联网时代,响应式设计已成手机端建站主流,无需单独搭建手机端。本文以 PageAdmin CMS 为例,阐述其原生响应式架构、轻量化等适配优势,详细拆解从前期规划、环境安装、响应式模板适配、内容优化,到测试上线与后期维护的全流程,该方案适配中小规模站点,能降低开发维护成本,保障多端用户体验一致性。
从外贸数据孤岛到智能引擎:信风AI多Agent架构深度解析
传统外贸获客面临数据孤岛、决策固化、工具割裂三大困境。信风TradeWind AI通过多Agent协同架构,构建“数据-决策-执行”闭环,实现从单点工具到智能协同系统的跃迁,打造可扩展、可定制、可进化的AI获客引擎。
ODPS 十五周年实录 | Data + AI,MaxCompute 下一个15年的新增长引擎
本文根据 ODPS 十五周年·年度升级发布实录整理而成,演讲信息如下: 于得水(得水):阿里云智能集团计算平台事业部资深技术专家 活动:【数据进化·AI 启航】ODPS 年度升级发布
官宣 | Apache Fluss (Incubating) 0.8 发布公告
Apache Fluss 0.8(孵化中)正式发布!作为进入Apache后的首个版本,全面增强湖流一体能力,支持Iceberg与Lance,引入Delta Join、动态配置、Materialized Table等核心特性,显著提升稳定性与性能,推动实时流处理迈向新阶段。
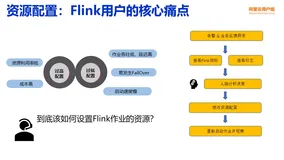
Flink 智能调优:从人工运维到自动化的实践之路
本文由阿里云Flink产品专家黄睿撰写,基于平台实践经验,深入解析流计算作业资源调优难题。针对人工调优效率低、业务波动影响大等挑战,介绍Flink自动调优架构设计,涵盖监控、定时、智能三种模式,并融合混合计费实现成本优化。展望未来AI化方向,推动运维智能化升级。

云栖实录|驰骋在数据洪流上:Flink+Hologres驱动零跑科技实时计算的应用与实践
零跑科技基于Flink构建一体化实时计算平台,应对智能网联汽车海量数据挑战。从车机信号实时分析到故障诊断,实现分钟级向秒级跃迁,提升性能3-5倍,降低存储成本。通过Flink+Hologres+MaxCompute技术栈,打造高效、稳定、可扩展的实时数仓,支撑100万台量产车背后的数据驱动决策,并迈向流批一体与AI融合的未来架构。
多源数据融合中做决策不再靠直觉!层次分析法(AHP)帮你科学选方案
层次分析法(AHP)助力科学决策!将复杂问题分解为目标、准则、方案的多层结构,通过两两比较与权重计算,实现定性与定量结合的优选判断。适用于选校、购房、供应商评估等多场景,搭配一致性检验与CRITIC法更客观可靠,让决策不再靠直觉。
2026版基于python的旅游景点推荐系统
本研究基于Python构建旅游景点推荐系统,利用Django框架与MySQL数据库,结合用户偏好、行为数据及景点多维度信息,实现个性化精准推荐,提升游客决策效率与体验,推动旅游智能化发展。
亚马逊商品列表API秘籍!轻松获取商品列表数据
亚马逊商品列表API(SP-API)提供标准化接口,支持通过关键词、分类、价格等条件搜索商品,获取ASIN、价格、销量等信息。采用OAuth 2.0认证与AWS签名,保障安全。数据以JSON格式传输,便于开发者批量获取与分析。

【可视化大屏】全流程讲解用python的pyecharts库实现拖拽可视化大屏的背后原理,简单粗暴!
本文详解基于Python的电影TOP250数据可视化大屏开发全流程,涵盖爬虫、数据存储、分析及可视化。使用requests+BeautifulSoup爬取数据,pandas存入MySQL,pyecharts实现柱状图、饼图、词云图、散点图等多种图表,并通过Page组件拖拽布局组合成大屏,支持多种主题切换,附完整源码与视频讲解。
Kubeflow-Trainer-架构学习指南
本指南系统解析Kubeflow Trainer架构,涵盖核心设计、目录结构与代码逻辑,结合学习路径与实战建议,助你掌握这一Kubernetes原生机器学习训练平台的原理与应用。
脑机接口(BCI):从信号到交互的工程实践
蒋星熠Jaxonic以“星际旅人”之姿,深耕脑机接口(BCI)工程实践。本文从系统架构、信号处理到解码算法,融合代码示例与可视化,剖析EEG/EMG非侵入式方案的落地挑战。聚焦延迟、准确率与用户体验,在噪声中构建稳定闭环,探索意念交互的可解释性与可靠性,助力极客穿越“噪声星云”,驶向人脑的奇妙行星。(238字)

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

