









Java 基于 DDD 分层架构实战从基础到精通最新实操全流程指南
本文详解基于Java的领域驱动设计(DDD)分层架构实战,结合Spring Boot 3.x、Spring Data JPA 3.x等最新技术栈,通过电商订单系统案例展示如何构建清晰、可维护的微服务架构。内容涵盖项目结构设计、各层实现细节及关键技术点,助力开发者掌握DDD在复杂业务系统中的应用。
AI 发展 && MCP
AI发展——计算机视觉、ChatGPT、Sora、DeepSeek、生成式AI。什么是MCP,Prompt、LLM、Function Call、Agent、MCP是什么,各自区别;MCP如何工作,MCP架构、MCP Server工作原理,Cursor如何使用MCP,自定义MCP Server

Pandas数据合并:10种高效连接技巧与常见问题
在数据分析中,数据合并是常见且关键的步骤。本文针对合并来自多个来源的数据集时可能遇到的问题,如列丢失、重复记录等,提供系统解决方案。基于对超1000个复杂数据集的分析经验,总结了10种关键技术,涵盖Pandas库中`merge`和`join`函数的使用方法。内容包括基本合并、左连接、右连接、外连接、基于索引连接、多键合并、数据拼接、交叉连接、后缀管理和合并验证等场景。通过实际案例与技术原理解析,帮助用户高效准确地完成数据整合任务,提升数据分析效率。

ClickHouse 应用剖析:设计理念、机制与实践
ClickHouse 是一款高性能的列式数据库管理系统,主要用于实时的大数据分析场景。它由俄罗斯 Yandex 公司开源于 2016 年,在网页日志分析、物联网监控、广告计费等领域有广泛应用。ClickHouse 通过列式存储、向量化执行和分布式架构,实现对海量数据的快速查询分析。本文将介绍 ClickHouse 的设计理念,以及在实际使用中如何处理数据删除更新、冷热数据分离等问题,并提供常见配置的调优建议和异常问题的处理方法。
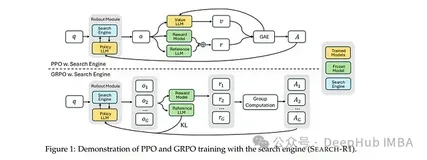
SEARCH-R1: 基于强化学习的大型语言模型多轮搜索与推理框架
SEARCH-R1是一种创新的强化学习框架,使大型语言模型(LLM)具备多轮搜索与推理能力。它通过强化学习自主生成查询并优化基于检索结果的推理,无需人工标注数据。相比传统RAG或工具使用方法,SEARCH-R1显著提升问答性能,在多个数据集上实现26%以上的相对性能提升。其核心优势在于强化学习与搜索的深度融合、交错式多轮推理机制及令牌级损失屏蔽技术,推动了LLM在复杂推理和实时知识获取方面的边界。尽管存在奖励函数设计简化等局限性,SEARCH-R1为构建更智能的交互系统提供了重要参考。
Figma桌面客户端下载教程+协作设计入门,小白也能变大神
Figma 是全球领先的云端UI/UX设计工具,支持多人实时协作、矢量图形编辑与原型交互设计。其核心优势包括跨平台同步、团队协作(支持50+成员同时编辑)和丰富的资源生态(集成2000+免费插件)。Figma无需安装,通过浏览器访问官网即可使用。硬件要求最低为4GB内存和5Mbps宽带,推荐配置为8GB+内存和50Mbps+宽带。用户可通过创建团队空间邀请成员,支持邮箱邀请和链接分享。Figma还提供详细的官方学习资源,帮助用户掌握核心功能。
淘宝买家订单列表、订单详情、订单物流 API 接口全攻略
淘宝订单相关API接口是电商自动化的核心工具,提供订单数据管理和物流追踪功能。开发者可通过HTTP协议调用,支持Python、Java等语言,响应JSON格式数据。主要功能包括:订单列表查询、订单详情获取和物流轨迹追踪。申请流程:注册账号(c0b.cc/R4rbK2),创建应用并生成App Key,申请所需接口权限如taobao.trades.sold.get、taobao.trade.fullinfo.get等。

[python 技巧] 快速掌握Streamlit: python快速原型开发工具
本文旨在快速上手python的streamlit库,包括安装,输入数据,绘制图表,基础控件,进度条,免费部署。
DataWorks:新一代 Data+AI 数据开发与数据治理平台演进
本文介绍了阿里云 DataWorks 在 DA 数智大会 2024 上的最新进展,包括新一代智能数据开发平台 DataWorks Data Studio、全新升级的 DataWorks Copilot 智能助手、数据资产治理、全面云原生转型以及更开放的开发者体验。这些更新旨在提升数据开发和治理的效率,助力企业实现数据价值最大化和智能化转型。
前端大模型入门:Transformer.js 和 Xenova-引领浏览器端的机器学习变革
除了调用API接口使用Transformer技术,你是否想过在浏览器中运行大模型?Xenova团队推出的Transformer.js,基于JavaScript,让开发者能在浏览器中本地加载和执行预训练模型,无需依赖服务器。该库利用WebAssembly和WebGPU技术,大幅提升性能,尤其适合隐私保护、离线应用和低延迟交互场景。无论是NLP任务还是实时文本生成,Transformer.js都提供了强大支持,成为构建浏览器AI应用的核心工具。
大数据时代的数据质量与数据治理策略
在大数据时代,高质量数据对驱动企业决策和创新至关重要。然而,数据量的爆炸式增长带来了数据质量挑战,如准确性、完整性和时效性问题。本文探讨了数据质量的定义、重要性及评估方法,并提出数据治理策略,包括建立治理体系、数据质量管理流程和生命周期管理。通过使用Apache Nifi等工具进行数据质量监控和问题修复,结合元数据管理和数据集成工具,企业可以提升数据质量,释放数据价值。数据治理需要全员参与和持续优化,以应对数据质量挑战并推动企业发展。
阿里巴巴的通义千问大模型
阿里巴巴通义千问是基于Transformer的大型语言模型,预训练于多样化数据集,支持18亿至720亿参数规模。在多模态英文任务中表现出色,且具备多语言对话及图片文本识别能力。可应用于搜索引擎、问答系统和对话交互,提供智能体验。然而,模型在逻辑题和指令理解上存在不足,需在特定领域进行优化。
如何实现AI检测与反检测原理
AI检测器用于识别AI生成的文本,如ChatGPT,通过困惑度和爆发性指标评估文本。低困惑度和低爆发性可能指示AI创作。OpenAI正研发AI文本水印系统,但尚处早期阶段。现有检测器对长文本较准确,但非100%可靠,最高准确率约84%。工具如AIUNDETECT和AI Humanizer提供AI检测解决方案,适用于学生、研究人员和内容创作者。
如何为Kafka加上账号密码(一)
一直以来,我们公司内网的Kafka集群都是在裸奔,只要知道端口号,任何人都能连上集群操作一番。直到有个主题莫名消失,才引起我们的警觉,是时候该考虑为它添加一套认证策略了。

大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。

腾讯看点基于 Flink 构建万亿数据量下的实时数仓及实时查询系统
腾讯看点基于 Flink 构建实时数仓以及实时数据查询系统,亚秒级的响应多维条件查询请求。
gig:自带负载均衡和降级功能的高可用RPC解决方案
gig基于对latency的负反馈控制,实现了坏节点屏蔽、服务预热、异构集群负载均衡、自动降级等功能,大大提高了阿里搜索线上服务的稳定性。
实战解析:淘宝商品评论item_review接口
本文详解2025年淘宝开放平台taobao.item.review.get接口合规调用方法,涵盖权限申请、参数配置、HMAC-SHA1签名生成及Java原生代码实现,无需第三方SDK,可快速集成至数据采集系统,稳定获取商品评论详情。
英伟达谷歌都在用的(开源特征存储平台Feast)-架构学习指南
欢迎来到Feast的世界!这是一个开源的生产级机器学习特征存储系统,专为解决特征数据高效管理与服务而设计。本指南将带你从零掌握其架构、核心概念与实战技巧,助你像架构师一样思考,像工匠一样编码,轻松应对训练与推理的一致性挑战。
构建AI智能体:十二、给词语绘制地图:Embedding如何构建机器的认知空间
Embedding是一种将词语、图像等信息转化为低维稠密向量的技术,使计算机能捕捉语义关系。不同于传统One-Hot编码,Embedding通过空间距离表达语义相似性,如“国王-男人+女人≈王后”,广泛应用于NLP、推荐系统与大模型中,是AI理解世界的基石。
小红书API接口文档:笔记详情数据开发手册
小红书笔记详情API可获取指定笔记的标题、正文、互动数据及多媒体资源,支持字段筛选与评论加载。通过note_id和access_token发起GET/POST请求,配合签名验证,广泛用于内容分析与营销优化。
基于python的个人财务记账系统
本研究探讨了基于Python的个人财务记账系统的设计与实现。随着经济快速发展,个人财务管理日益重要,传统手工记账方式效率低且易出错,而现有商业软件功能复杂、缺乏个性化。Python凭借其简洁语法和强大库支持,适用于开发高效、易用的记账系统。系统结合Pyecharts实现数据可视化,利用MySQL进行数据存储,具备自动分类、统计分析、财务报表生成等功能,帮助用户清晰掌握财务状况,合理规划收支,提升财务管理效率。研究具有重要的现实意义和应用前景。
JAVA 八股文全网最详尽整理包含各类核心考点助你高效学习 jAVA 八股文赶紧收藏
本文整理了Java核心技术内容,涵盖Java基础、多线程、JVM、集合框架等八股文知识点,包含面向对象特性、线程创建与通信、运行时数据区、垃圾回收算法及常用集合类对比,附有代码示例与学习资料下载链接,适合Java开发者系统学习与面试准备。
Post-Training on PAI (1):一文览尽开源强化学习框架在PAI平台的应用
Post-Training(即模型后训练)作为大模型落地的重要一环,能显著优化模型性能,适配特定领域需求。相比于 Pre-Training(即模型预训练),Post-Training 阶段对计算资源和数据资源需求更小,更易迭代,因此备受推崇。近期,我们将体系化地分享基于阿里云人工智能平台 PAI 在强化学习、模型蒸馏、数据预处理、SFT等方向的技术实践,旨在清晰地展现 PAI 在 Post-Training 各个环节的产品能力和使用方法,欢迎大家随时交流探讨。

RAG系统文本分块优化指南:9种实用策略让检索精度翻倍
本文深入探讨了RAG系统中的九种文本分块策略。固定大小分块简单高效,但可能破坏语义完整性;基于句子和语义的分块保留上下文,适合语义任务;递归与滑动窗口分块灵活控制大小;层次化和主题分块适用于结构化内容;特定模态分块处理多媒体文档;智能代理分块则通过大语言模型实现动态优化。开发者需根据文档类型、需求及资源选择合适策略,以提升RAG系统的性能和用户体验。作者Cornellius Yudha Wijaya详细分析了各策略的技术特点与应用场景。

大型多模态推理模型技术演进综述:从模块化架构到原生推理能力的综合分析
该研究系统梳理了大型多模态推理模型(LMRMs)的技术发展,从早期模块化架构到统一的语言中心框架,提出原生LMRMs(N-LMRMs)的前沿概念。论文划分三个技术演进阶段及一个前瞻性范式,深入探讨关键挑战与评估基准,为构建复杂动态环境中的稳健AI系统提供理论框架。未来方向聚焦全模态泛化、深度推理与智能体行为,推动跨模态融合与自主交互能力的发展。
Ray Flow Insight:让分布式系统调试不再"黑盒"
作为Ray社区的积极贡献者,我们希望将这些实践中沉淀的技术能力回馈给社区,推动Ray生态在实际场景中的应用深度和广度。因此,2024年底我们做了激活AntRay开源社区的决策,AntRay会始终保持与官方Ray版本强同步(即AntRay会紧随Ray官方社区版本而发布),内部Feature亦会加速推向AntRay以开源研发模式及时反哺内部业务,同时会将社区关注的Feature提交至Ray官方社区,实现内外部引擎双向价值流动。后续我们会以系列文章形式同步蚂蚁推向开源的新特性,本文将重点介绍:Ray Flow Insight —— 让分布式系统调试不再"黑盒"。
重磅!2025年中科院预警期刊名单正式发布!
中国科学院文献情报中心发布的《国际期刊预警名单》旨在防范学术不端与不当出版行为,保护科研生态良性发展。2025年版本聚焦两大问题:学术不端(如引用操纵、论文工厂)和不利于中国学术成果国际化传播的行为(如中国作者占比过高或APC费用不合理)。预警名单动态调整,发布时点从年底改为年初,便于科研人员及时调整投稿策略。被列入预警名单的期刊可能影响职称评审及科研经费认可,建议优先选择中科院分区表推荐期刊,警惕“快速代发”陷阱,并关注期刊官网声明。未来科研生态将更注重规范化与原创性,推动高质量学术发表。维护健康的学术环境对提升中国科研全球影响力至关重要。
阿里万相重磅开源,人工智能平台PAI一键部署教程来啦
阿里云视频生成大模型万相2.1(Wan)重磅开源!Wan2.1 在处理复杂运动、还原真实物理规律、提升影视质感以及优化指令遵循方面具有显著的优势,轻松实现高质量的视频生成。同时,万相还支持业内领先的中英文文字特效生成,满足广告、短视频等领域的创意需求。阿里云人工智能平台 PAI-Model Gallery 现已经支持一键部署阿里万相重磅开源的4个模型,可获得您的专属阿里万相服务。
使用PHP接入纯真IP库:实现IP地址地理位置查询
本文介绍了如何使用PHP接入纯真IP库(QQWry),实现IP地址的地理位置查询。纯真IP库是一个轻量级的IP数据库,数据格式简单,查询速度快,适合Web应用。首先,下载并放置`QQWry.dat`文件到项目目录。接着,通过编写PHP类解析该文件,实现IP查询功能。最后,提供了一个完整的案例演示,展示如何查询IP地址对应的国家和地区信息。该工具适用于用户地理位置分析、访问日志分析和风控系统等场景,具有轻量级、查询速度快、数据更新方便等优点。
产品经理-需求层次理论 - AxureMost
需求层次理论由马斯洛提出,将人类需求分为五个层次:生理、安全、社交、尊重和自我实现。该理论在产品设计中广泛应用,指导设计师创造满足用户深层次需求的产品。通过确保基本功能、强化安全、促进社交、提供个性化选项及支持自我实现,产品不仅能提升功能性,还能增强用户的心理满足感和忠诚度。
探秘写歌词的技巧和方法:让你的文字唱出旋律,妙笔生词AI智能写歌词软件
在音乐世界里,歌词是触动人心的灵魂。本文介绍如何掌握写歌词的技巧,包括灵感捕捉、结构布局、语言运用等,并推荐《妙笔生词智能写歌词软件》作为创作助手,助你轻松创作动人心弦的歌词。
如何从0部署一个大模型RAG应用
本文介绍了如何从零开始部署一套RAG应用,并将其集成到移动端,如钉钉群聊中。应用场景包括客服系统、智能助手、教育辅导和医疗咨询等。通过阿里云PAI和AppFlow,您可以轻松部署大模型RAG应用,并实现智能化的问答服务。具体步骤包括准备向量检索库、训练私有模型、部署RAG对话应用、创建钉钉应用及配置机器人等。

轻松抓取:用 requests 库处理企业招聘信息中的联系方式
本文详细介绍如何利用Python的`requests`库结合代理IP技术,突破Boss直聘的登录验证与反爬虫机制,抓取企业招聘信息中的联系方式。文章首先阐述了Boss直聘数据抓取面临的挑战,随后介绍了代理IP轮换、登录会话保持及请求头伪装等关键技术。通过一个完整的示例代码,展示了从配置代理、模拟登录到解析HTML获取联系方式的具体步骤。此方法不仅适用于Boss直聘,还可扩展至其他需登录权限的网站抓取任务。
TimeMOE: 使用稀疏模型实现更大更好的时间序列预测
TimeMOE是一种新型的时间序列预测基础模型,通过稀疏混合专家(MOE)设计,在提高模型能力的同时降低了计算成本。它可以在多种时间尺度上进行预测,并且经过大规模预训练,具备出色的泛化能力。TimeMOE不仅在准确性上超越了现有模型,还在计算效率和灵活性方面表现出色,适用于各种预测任务。该模型已扩展至数十亿参数,展现了时间序列领域的缩放定律。研究结果显示,TimeMOE在多个基准测试中显著优于其他模型,特别是在零样本学习场景下。

生信分析代码之前还好好的,怎么就报错了 Error in Ops. data. frame(guide_loc, panel_loc) :'==' only defined for equally-sized data frames
执行 `DimPlot` 函数时遇到错误 `;Error in Ops. data. frame(g guides_loc, panel_loc) : '==' only defined for equally-sized data frames`。解决方案和办法
VQ-VAE:矢量量化变分自编码器,离散化特征学习模型
VQ-VAE 是变分自编码器(VAE)的一种改进。这些模型可以用来学习有效的表示。本文将深入研究 VQ-VAE 之前,不过,在这之前我们先讨论一些概率基础和 VAE 架构。
Fama-French模型,特别是三因子模型(Fama-French Three-Factor Model)
Fama-French模型,特别是三因子模型(Fama-French Three-Factor Model)
阿里云人工智能平台PAI论文入选OSDI '24
阿里云人工智能平台PAI的论文《Llumnix: Dynamic Scheduling for Large Language Model Serving》被OSDI '24录用。论文通过对大语言模型(LLM)推理请求的动态调度,大幅提升了推理服务质量和性价比。
android studio开发时提示 TLS 握手错误解决办法
在Windows环境下遇到TLS协议版本不支持的错误,Gradle构建失败。解决方案是在build.gradle.kts中设置系统属性`https.protocols`为`TLSv1.2`,而非遵循误导信息设置为TLSv1.1。
案例:批量区域识别内容重命名,批量识别扫描PDF区域内容识别重命名,批量识别图片区域内容重命名图片修改图片名字,批量识别图片区域文字并重命名,批量图片部分识别内容重命文件,PDF区域内容提取重命名
该内容介绍了如何使用区域识别重命名软件高效整理图片,例如将图片按时间及内容重命名,适用于简历、单据等识别。文中提供了软件下载链接(百度云盘和腾讯网盘),并列出软件使用的几个关键条件,包括文字清晰、文件名长度限制等。示例展示了银行单据和公司工作单据的识别情况。文章还提及OCR技术在图片文字识别中的应用,强调了识别率、误识率和用户友好性等评估指标。如有类似需求,读者可留言或下载软件测试,并提供图片以获取定制的识别方案。

爬虫技术升级:如何结合DrissionPage和Auth代理插件实现数据采集
本文介绍了在Python中使用DrissionPage库和Auth代理Chrome插件抓取163新闻网站数据的方法。针对许多爬虫框架不支持代理认证的问题,文章提出了通过代码生成包含认证信息的Chrome插件来配置代理。示例代码展示了如何创建插件并利用DrissionPage进行网页自动化,成功访问需要代理的网站并打印页面标题。该方法有效解决了代理认证难题,提高了爬虫的效率和安全性,适用于各种需要代理认证的网页数据采集。
归一化技术比较研究:Batch Norm, Layer Norm, Group Norm
本文将使用合成数据集对三种归一化技术进行比较,并在每种配置下分别训练模型。记录训练损失,并比较模型的性能。
Paimon 与 Spark 的集成(二):查询优化
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
