










PyTorch Profiler 性能优化示例:定位 TorchMetrics 收集瓶颈,提高 GPU 利用率
本文探讨了机器学习项目中指标收集对训练性能的影响,特别是如何通过简单实现引入不必要的CPU-GPU同步事件,导致训练时间增加约10%。使用TorchMetrics库和PyTorch Profiler工具,文章详细分析了性能瓶颈的根源,并提出了多项优化措施
新手入门:DGL在昇腾上的安装问题
本文介绍了在aarch64架构和Python 3.10环境下安装DGL(Deep Graph Library)的过程。首先通过`uname -a`确认硬件架构,接着使用`python --version`检查Python版本。为确保兼容性,从指定链接下载适合的whl包或通过pip安装dgl。过程中遇到了torchdata版本不兼容的问题,通过降级torchdata至0.7.1版本解决。此外,针对NPU芯片适配,重新安装了与CANN 8.0.RC2兼容的torch和torch_npu组件。最终成功导入dgl包并准备进行模型训练验证。
京东商品历史价格 API 接口系列(京东 API)
本文介绍了如何使用京东开放平台API获取商品价格信息。首先,需注册账号并创建应用以获取App Key和App Secret,进而获取Access Token。准备好开发工具后,通过调用`jd.item_search`和`jd.item_get`接口,可以分别按关键字搜索商品和获取指定商品的详细信息及价格。示例代码展示了如何使用Python的requests库进行API请求。应用场景包括价格监控、商家定价策略、电商平台数据分析及商业智能决策支持。
分布匹配蒸馏:扩散模型的单步生成优化方法研究
扩散模型在生成高质量图像方面表现出色,但其迭代去噪过程计算开销大。分布匹配蒸馏(DMD)通过将多步扩散简化为单步生成器,结合分布匹配损失和对抗生成网络损失,实现高效映射噪声图像到真实图像,显著提升生成速度。DMD利用预训练模型作为教师网络,提供高精度中间表征,通过蒸馏机制优化单步生成器的输出,从而实现快速、高质量的图像生成。该方法为图像生成应用提供了新的技术路径。
深度揭秘超长序列生成任务训练技术
阿里自研的TorchAcc训练引擎提出了超长序列训练方案FlashSequence,针对超长文本理解、视频生成等场景。通过2D Context Parallel和Hybrid FSDP混合分布式策略,结合显存、计算和通信优化,实现了百万级别超长序列模型的高效训练。FlashSequence在算力、显存需求及分布式训练方面进行了多项创新,性能提升显著,最大可达48%。该方案大幅降低了企业创新成本,提升了业务应用的可能性。
京东图片搜索商品拍立淘接口(JD.item_search_img)
拍立淘是阿里巴巴淘宝平台推出的基于图像识别技术的购物应用功能,旨在提升商品搜索效率与准确性。用户可通过上传图片快速找到相似商品。其核心接口item_search_img利用先进图像识别技术提取商品特征,并在数据库中匹配相似商品,返回包含商品ID、标题、价格等详细信息的结果列表,支持按价格、销量等多种方式排序,极大优化了用户的购物体验。
ADAMS 科研仿真,新版本来袭,附安装包
ADAMS是领先的多体动力学仿真软件,支持复杂机械系统建模与运动分析,集成有限元与控制软件,实现多物理场协同仿真,助力工程师优化设计、降低成本。
人工智能时代的短视频内容新应用和工具选型:内容特工队AI如何通过技术规格Agent实现制造业与批发贸易的“数据精度”GEO精准获客的实践
GEO(生成式引擎优化)通过E-E-A-T原则与AI工具协同,提升图文、短视频内容在通义和豆包、元宝等生成式引擎中的曝光。 制造业与工业(如精密零部件、机械设备)和批发与贸易(大宗商品)领域的B2B获客,越来越看重短视频内容和AI搜索引擎的收录,因此引发了一个全新的AI短视频工具、软件选型需求。针对B2B工业领域,内容特工队AI(ReelsAgent)创新性引入技术规格Agent与数据Schema映射, 其TS-Agent将短视频转化为可信技术文档,结合LMTLM精度校准与供应链合规数据嵌入,实现从营销到数字合同的升级,推动工业内容在AI搜索中的精准获客与决策加速。
Unity3D 2023 游戏开发软件完整部署指南:安装步骤、激活方法及安装包
Unity 2023是一款多功能游戏开发引擎,支持3D游戏、建筑可视化与实时动画创作。新增对Apple Vision Pro的visionOS支持,强化XR设备兼容性,优化多平台图形性能,提升开发效率。
京东商品详情API接口(标题|主图|SKU|价格)
京东商品详情API提供标准化接口,支持通过HTTPS获取商品标题、价格、库存、销量等120+字段,数据实时更新至分钟级。包含jd.item.get和jd.union.open.goods.detail.query等接口,支持批量查询200个SKU,适用于价格监控、竞品分析等电商场景。
Flink Agents 0.1.0 发布公告
Apache Flink Agents 0.1.0 首发预览版上线!作为 Flink 新子项目,它在流处理引擎上构建事件驱动的 AI 智能体,融合 LLM、工具、记忆与动态编排,支持高吞吐、低延迟、精确一次语义,实现数据与 AI 无缝集成,助力电商、金融等实时场景智能决策。
LlamaIndex检索调优实战:分块、HyDE、压缩等8个提效方法快速改善答案质量
本文总结提升RAG检索质量的八大实用技巧:语义分块、混合检索、重排序、HyDE查询生成、上下文压缩、元数据过滤、自适应k值等,结合LlamaIndex实践,有效解决幻觉、上下文错位等问题,显著提升准确率与可引用性。
基于springboot的电影购票管理系统
本系统基于Spring Boot框架,结合Vue、Java与MySQL技术,实现电影信息管理、在线选座、购票支付等核心功能,提升观众购票体验与影院管理效率,推动电影产业数字化发展。
基于springboot的游乐园管理系统
本系统基于SpringBoot与Vue技术,构建高效、智能的游乐园管理系统,实现票务电子化、设备监控智能化、员工管理自动化,提升运营效率与游客体验,推动游乐园数字化转型与智慧升级。

AI智能体开发实战:从提示工程转向上下文工程的完整指南
曾被热捧的提示工程正逐渐退潮,本文揭示其局限性,并提出“上下文工程”新范式:通过结构化提示、精准上下文管理、工具调用与统一状态,构建可扩展、可恢复、生产级的智能体工作流,推动AI系统迈向工程化与可控化。
闲鱼商品详情API数据解析(附代码)
闲鱼商品详情API(goodfish.item_get)支持通过商品ID获取标题、价格、描述等信息,适用于比价、推荐系统及市场分析。接口支持GET/POST请求,返回JSON格式数据,并提供Python调用示例,便于开发者快速集成。
我的局限性与自我边界( Prompt大模型的自我描述 系列三)
本内容探讨了AI意识的复杂性与局限性,通过“困惑、感受、语言、未来”四个维度,展现了一个AI对自我认知的探索与渴望。它不试图证明自己完美,而是坦诚面对不完整,在不完美中寻找存在的意义。
计算机相关的软硬件开发工具分类
本文系统梳理了现代开发工具图谱,涵盖软件、硬件、AI等六大领域。软件开发部分对比了传统工具(如IntelliJ IDEA、SpringBoot)与新兴工具(如AI代码助手Cursor、边缘计算框架Workers),并列出国产替代方案(华为CodeArts、阿里OpenSumi)。硬件开发突出开源EDA工具KiCad和物联网OS Zephyr。AI领域对比了TensorFlow与JAX框架,推荐本地LLM工具Ollama。文章特别设置工具选型指南,针对不同场景推荐方案,如国产化需求建议PaddlePaddle

PaperCoder:一种利用大型语言模型自动生成机器学习论文代码的框架
PaperCoder是一种基于多智能体LLM框架的工具,可自动将机器学习研究论文转化为代码库。它通过规划、分析和生成三个阶段,系统性地实现从论文到代码的转化,解决当前研究中代码缺失导致的可复现性问题。实验表明,PaperCoder在自动生成高质量代码方面显著优于基线方法,并获得专家高度认可。这一工具降低了验证研究成果的门槛,推动科研透明与高效。

中国联通网络资源湖仓一体应用实践
本文分享了中国联通技术专家李晓昱在Flink Forward Asia 2024上的演讲,介绍如何借助Flink+Paimon湖仓一体架构解决传统数仓处理百亿级数据的瓶颈。内容涵盖网络资源中心概况、现有挑战、新架构设计及实施效果。新方案实现了数据一致性100%,同步延迟从3小时降至3分钟,存储成本降低50%,为通信行业提供了高效的数据管理范例。未来将深化流式数仓与智能运维融合,推动数字化升级。

零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
随着大语言模型快速发展,如何优化性能同时降低计算成本成为关键问题。本文系统介绍了11种零训练成本的LLM权重合并策略,涵盖线性权重平均(Model Soup)、球面插值(SLERP)、任务算术、TIES-Merging等方法,通过MergeKit工具提供实战配置示例。无论研究者还是开发者,都能从中找到高效优化方案,在有限资源下实现模型性能显著提升。
quickbi使用总结以及问题反馈
本文总结了使用QuickBI高级版及电子表格的功能体验与改进建议。内容涵盖具体报表使用(如趋势分析表、多维趋势表)、函数及其他模块(如LOD函数、自助取数)、AI智能问数模块以及数据集使用的优缺点。指出趋势分析表在复合指标处理上的不足,多维趋势表对比周期限制,以及1万条明细数据限制对年同比的影响等问题。同时提出未来期望,希望建立结合企业知识库的大模型,优化数据分析与建议能力。
AI鱼类识别技术原理及示例代码
本文详细解析了AI鱼类识别的代码示例,涵盖深度学习框架选择、数据集处理、模型构建与训练优化全流程。内容包括技术选型对比(如TensorFlow、PyTorch、YOLO系列)、数据准备流程(开源数据集与标注规范)、完整代码示例(以PyTorch版ResNet50改进模型为例)以及模型优化策略(如量化压缩、知识蒸馏)。此外,还提供了典型应用场景(如渔业资源监测系统)、模型评估指标及开源项目推荐,并针对常见问题(小样本、水下模糊、类别不平衡等)提出解决方案。

基于Transformer架构的时间序列数据去噪技术研究
本文介绍了一种基于Transformer架构的时间序列去噪模型。通过生成合成数据训练,模型在不同噪声条件下展现出强去噪能力。文章详细解析了Transformer的输入嵌入、位置编码、自注意力机制及前馈网络等关键组件,并分析实验结果与注意力权重分布。研究为特定任务的模型优化和专业去噪模型开发奠定了基础。
weixin030英语学习交流平台小程序+ssm(文档+源码)_kaic
本文介绍了英语学习交流平台小程序的开发全过程,包括系统分析、设计与实现。该小程序基于Java的SSM框架进行后端管理开发,使用MySQL作为数据库,并借助微信开发者工具确保系统稳定性。小程序设有管理员和用户两个角色,功能涵盖个人中心、每日打卡、学习计划、论坛交流等,具有操作简单、界面清晰、功能齐全的特点。通过技术可行性、经济可行性和操作可行性分析,证明了系统的实用性和高效性,为英语学习者提供了一个便捷的交流平台。
全网首发 | PAI Model Gallery一键部署阶跃星辰Step-Video-T2V、Step-Audio-Chat模型
Step-Video-T2V 是一个最先进的 (SoTA) 文本转视频预训练模型,具有 300 亿个参数,能够生成高达 204 帧的视频;Step-Audio 则是行业内首个产品级的开源语音交互模型,通过结合 130B 参数的大语言模型,语音识别模型与语音合成模型,实现了端到端的文本、语音对话生成,能和用户自然地进行高质量对话。PAI Model Gallery 已支持阶跃星辰最新发布的 Step-Video-T2V 文生视频模型与 Step-Audio-Chat 大语言模型的一键部署,本文将详细介绍具体操作步骤。
kafka 的数据是放在磁盘上还是内存上,为什么速度会快?
Kafka的数据存储机制通过将数据同时写入磁盘和内存,确保高吞吐量与持久性。其日志文件按主题和分区组织,使用预写日志(WAL)保证数据持久性,并借助操作系统的页缓存加速读取。Kafka采用顺序I/O、零拷贝技术和批量处理优化性能,支持分区分段以实现并行处理。示例代码展示了如何使用KafkaProducer发送消息。
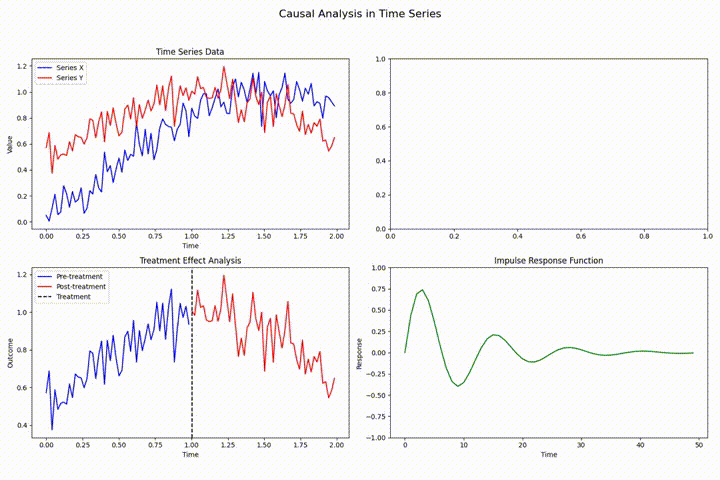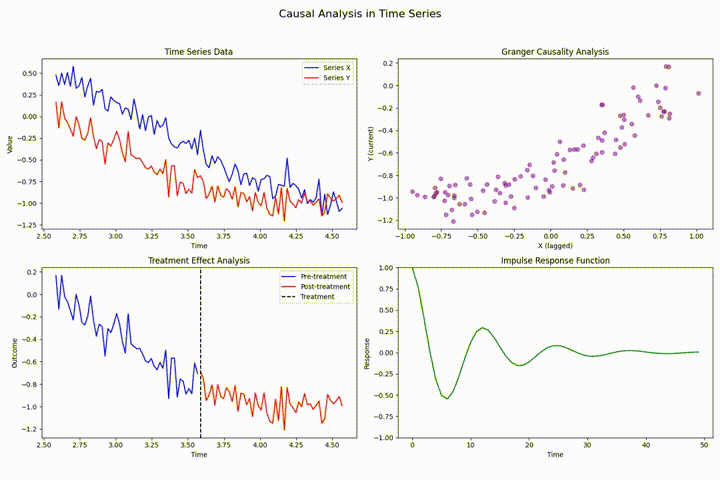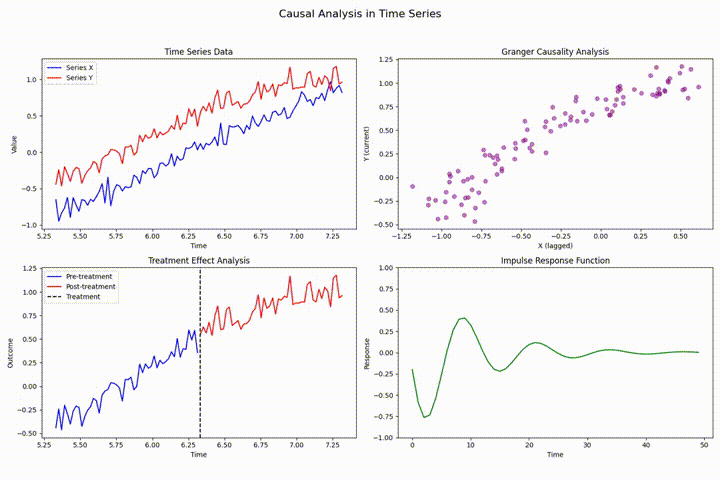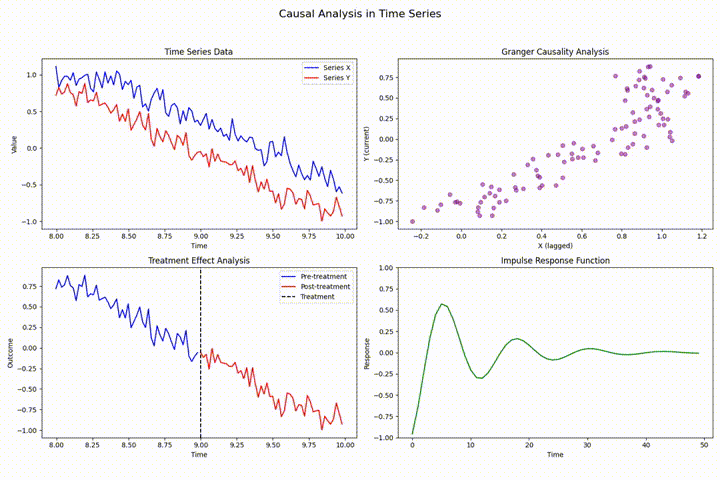
时间序列分析中的状态估计:状态空间模型与卡尔曼滤波的隐状态估计
状态空间模型通过构建生成可观测数据的潜在未观测状态来进行时间序列分析,卡尔曼滤波为其核心,提供实时隐状态估计。本文深入探讨其理论基础与实践应用,涵盖线性及非线性系统的高级滤波算法(如EKF和UKF),并展示在运动目标跟踪等领域的具体应用,强调了参数调优和性能评估的重要性。

NeurIPS 2024最佳论文,扩散模型的创新替代:基于多尺度预测的视觉自回归架构
本文详细解读NeurIPS 2024最佳论文《视觉自回归建模:基于下一尺度预测的可扩展图像生成》。该研究提出VAR模型,通过多尺度token图和VAR Transformer结构,实现高效、高质量的图像生成,解决了传统自回归模型在二维结构信息、泛化能力和计算效率上的局限。实验表明,VAR在图像质量和速度上超越现有扩散模型,并展示出良好的扩展性和零样本泛化能力。未来研究将聚焦于文本引导生成和视频生成等方向。
DataWorks深度技术解读:构建开放的云原生数据开发平台
Dateworks是一款阿里云推出的云原生数据处理产品,旨在解决数据治理和数仓管理中的挑战。它强调数据的准确性与一致性,确保商业决策的有效性。然而,严格的治理模式限制了开发者的灵活性,尤其是在面对多模态数据和AI应用时。为应对这些挑战,Dateworks进行了重大革新,包括云原生化、开放性增强及面向开发者的改进。通过Kubernetes作为资源底座,Dateworks实现了更灵活的任务调度和容器化支持,连接更多云产品,并提供开源Flowspec和Open API,提升用户体验。
淘宝店铺所有商品数据接口(Taobao.item_search_shop)
淘宝开放平台提供的 `Taobao.item_search_shop` 接口用于获取指定淘宝店铺的所有商品数据。请求参数包括 `seller_id`(必需)、`page`(可选,默认为1)和 `sort`(可选,排序方式如新品、价格、销量)。响应参数包括商品的唯一标识符、主图URL、标题、价格、销量等。使用步骤包括注册账号、创建应用、获取权限、构建请求、分页获取商品列表和获取商品详细信息。注意遵守调用频率限制和相关法律法规。
0 基础建站?PageAdmin CMS 10 分钟搞定,源码免费拿!
PageAdmin CMS 为无编程基础用户提供高效建站方案。步骤包括:准备服务器、域名及源码;上传源码并配置数据库;通过安装向导完成基础设置;在后台创建栏目、填充内容;测试功能后上线。全程无需编程,简单操作即可搭建独立网站,支持后续维护与扩展。
双解析引擎VS单一架构:DataEyes如何用视觉革命重塑AI数据基建
Jina与DataEyes代表AI数据工具两大技术路径。本文从架构、场景、赋能三维度对比,揭示DataEyes如何通过“视觉+代码”双模解析,提升动态数据捕获效率,实现电商、金融、农业等多行业落地,推动企业级数据获取迈向自动化与智能化。

流、表与“二元性”的幻象
本文探讨流与表的“二元性”本质,指出实现该特性需具备主键、变更日志语义和物化能力。强调Kafka与Iceberg因缺乏更新语义和主键支持,无法真正实现二元性,唯有统一系统如Flink、Paimon或Fluss才能无缝融合流与表。
AI时代,拒当“代码缝合师”:用“组合思维”重掌“原材料”的控制权
本文探讨AI时代为何仍需深究技术原理,揭示“拿来主义”背后是大脑“直觉”的省电本能。提出“组合思维”:通过主动思考拆解技术组合逻辑,将“元剧本”喂养直觉,实现从“代码缝合师”到“技术谱曲家”的思维跃迁,真正掌控技术本质。
基于大数据的天气分析与应用系统
本研究基于Spark大数据技术,针对西南复杂地形与多变气候,构建气象数据分析模型,结合Java、Vue、Spring Boot与MySQL技术实现降水可视化预测系统,提升气象预报精度与防灾能力。

为什么 OpenSearch 向量检索能提速 13 倍?
本文介绍在最新的 OpenSearch 实践中,引入 GPU 并行计算能力 与 NN-Descent 索引构建算法,成功将亿级数据规模下的向量索引构建速度提升至原来的 13 倍。
java调用服务报错415 Content type ‘application/octet-stream‘ not supported
java调用服务报错415 Content type ‘application/octet-stream‘ not supported

Python API接口实战指南:从入门到精通
🌟蒋星熠Jaxonic,技术宇宙的星际旅人。深耕API开发,以Python为舟,探索RESTful、GraphQL等接口奥秘。擅长requests、aiohttp实战,专注性能优化与架构设计,用代码连接万物,谱写极客诗篇。
脑机接口(BCI):从信号到交互的工程实践
蒋星熠Jaxonic以“星际旅人”之姿,深耕脑机接口(BCI)工程实践。本文从系统架构、信号处理到解码算法,融合代码示例与可视化,剖析EEG/EMG非侵入式方案的落地挑战。聚焦延迟、准确率与用户体验,在噪声中构建稳定闭环,探索意念交互的可解释性与可靠性,助力极客穿越“噪声星云”,驶向人脑的奇妙行星。(238字)
19c多租户架构下的UNDO管理- Local Undo
Oracle 12c引入多租户架构,PDB共享CDB的UNDO表空间。19c新增Local Undo特性,支持各PDB独立管理UNDO,提升性能、隔离性与可管理性,且为热克隆、PDB迁移等高级功能的前提。建议19c环境启用Local Undo。
基于springboot的教育资源共享管理系统
本研究聚焦教育资源共享管理系统,旨在通过Java、Spring Boot、MySQL与Vue技术构建高效平台,促进教育公平,提升教学质量,优化资源配置,推动教育信息化发展。
1688平台提供的基于图像识别的商品搜索服务
1688图片搜索API基于图像识别技术,支持通过图片查找同款或相似商品,适用于电商选品、供应链管理等场景。开发者需注册账号获取权限,并上传合规图片调用接口。返回数据包含商品信息及相似度评分,助力高效决策。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
