一.引言
parquet 文件常见与 Flink、Spark、Hive、Streamin、MapReduce 等大数据场景,通过列式存储和元数据存储的方式实现了高效的数据存储与检索,下面介绍 Flink 场景下如何读取 Parquet。Parquet 相关知识可以参考:Spark - 一文搞懂 parquet。

 编辑
编辑
二.Parquet Read By Scala
1.依赖准备与环境初始化
import org.apache.hadoop.fs.FileSystem import org.apache.flink.formats.parquet.ParquetRowInputFormat import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ import org.apache.parquet.hadoop.ParquetFileReader import org.apache.parquet.schema.PrimitiveType.PrimitiveTypeName import org.apache.parquet.schema.Type.Repetition import org.apache.parquet.schema.{MessageType, PrimitiveType, Type}

Flink 读取 parquet 除了正常 Flink 环境相关依赖外,还需要加载单独的 Parquet 组件:
<dependency> <groupId>org.apache.parquet</groupId> <artifactId>parquet-avro</artifactId> <version>1.10.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-parquet_2.12</artifactId> <version>1.9.0</version> </dependency>

本文基于 Flink-1.13.1 + scala-2.12.8 + hadoop-2.6.0 的运行环境,不同版本下可能需要更换上述 parquet 相关依赖。下面初始化 Flink ExecutionEnvironment,因为流式处理的原因,这里初始化环境类型为 Stream:
val env = StreamExecutionEnvironment.getExecutionEnvironment

2.推断 Schem 读取 Parquet
parquet 通过列式存储数据,所以需要 schema 标定每一列的数据类型与名称,与 Spark 类似, Flink 也可以通过 Parquet 文件推断其对应 schema 并读取 Parquet。
def readParquetWithInferSchema(env: StreamExecutionEnvironment): Unit = { val filePath = "./test.parquet" val configuration = new org.apache.hadoop.conf.Configuration(true) val parquetFileReader = ParquetFileReader.readFooter(configuration, new org.apache.hadoop.fs.Path(filePath)) val schema: MessageType = parquetFileReader.getFileMetaData.getSchema println(s"Schema: $schema") val hdfs: FileSystem = org.apache.hadoop.fs.FileSystem.get(configuration) val rowData = env.readFile(new ParquetRowInputFormat(new org.apache.flink.core.fs.Path(filePath), schema), filePath).setParallelism(1) rowData.map(row => { val source = row.getField(1) val flag = row.getField(35) source + "\t" + flag }).setParallelism(1).print() }

通过 parquetFileReader 获取元数据 MetaData 并获取 parquet 对应 schema,最终通过 env.readFile 方法指定 InputFormat 为 ParquetRowInputFormat 读取 parquet 文件,先看一下打印出来的 schema 形式:
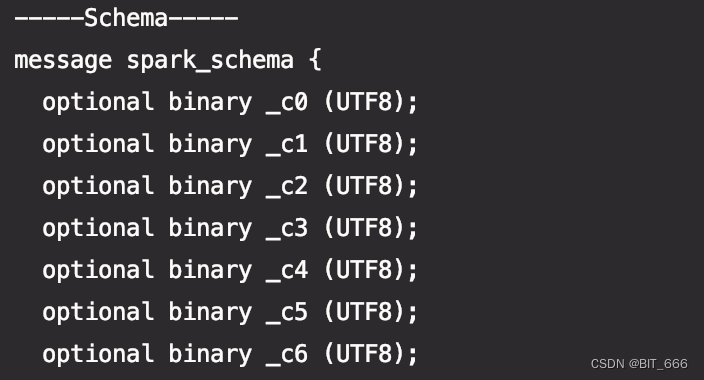
 编辑
编辑
由于读取的 parquet 为 SparkSession 生成,所以列名采用了 Spark 的默认形式 _c1,_c2 ...
env.execute("ReadParquet")

调用执行方法运行上述 print demo 打印最终结果。
Tips:
这里的 Row 类型为 org.apache.flink.types.Row 而不再是 org.apache.spark.sql.Row,获取元素的方法也不再是 row.getString 或其他,而是采用 getFiled 传入 position 或者 列名 得到,索引从 0 开始。
 编辑
编辑
3.指定 schema 读取 Parquet
除了 infer 推理得到 schema 外,读取也支持自定义 schema,与 spark 类似,这里也提供了 PrimitiveType 指定每一列的数据类型,并合并为 MessageType 得到最终的 schema。
def readParquetWithAssignSchema(env: StreamExecutionEnvironment): Unit = { val filePath = "./test.parquet" val id = new PrimitiveType(Repetition.OPTIONAL, PrimitiveTypeName.BINARY, "_c0") val source = new PrimitiveType(Repetition.OPTIONAL, PrimitiveTypeName.BINARY, "_c1") val flag = new PrimitiveType(Repetition.OPTIONAL, PrimitiveTypeName.BINARY, "_c35") val typeArray = Array(id, source, flag) val typeListAsJava = java.util.Arrays.asList(typeArray: _*).asInstanceOf[java.util.List[Type]] val schema = new MessageType("schema", typeListAsJava) println(schema) val rowData = env.readFile(new ParquetRowInputFormat(new org.apache.flink.core.fs.Path(filePath), schema), filePath).setParallelism(1) rowData.map(row => { val source = row.getField(1) val flag = row.getField(2) source + "\t" + flag }).setParallelism(1).print() }

上面读取的 test.parquet 有 40+ col,这里只读取第 1,2,35 列,所以单独指定 id,source,flag 三列生成 PrimitiveType 并添加至 MessageType 形成 schema,由于 MessageType 为 Java 参数,所以需要通过 asList + asInstance 进行转化,看一下当前的 schema 情况:
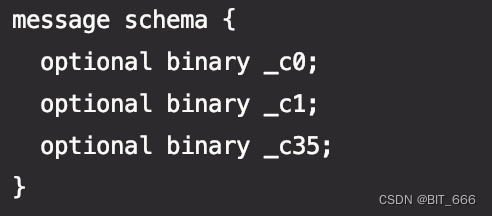
 编辑
编辑
env.execute("ReadParquet")

调用执行方法执行上述 print 逻辑即可。
Tips:
这里列名给出了 _c0, _c1,_c35,但是读取是 position 索引只能选取 0,1,2,因为 schema 数量决定了读取 Row 的列数,而 schema 的列名决定了读取的内容,在该 schema 基础下读取 getField(35) 会报数组越界 java.lang.ArrayIndexOutOfBoundsException:

 编辑
编辑
三. Parquet Read By Java
java 读取与 scala 大同小异,主要差别是 map 变为 MapFunction,这里直接贴完整函数方法:
import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.formats.parquet.ParquetRowInputFormat; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.types.Row; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.parquet.hadoop.ParquetFileReader; import org.apache.parquet.hadoop.metadata.ParquetMetadata; import org.apache.parquet.schema.MessageType; /** * @title: ReadParquetByJava * @Author DDD * @Date: 2022/7/21 8:36 上午 * @Version 1.0 */ public class ReadParquetByJava { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String path = "./test.parquet"; Configuration configuration = new org.apache.hadoop.conf.Configuration(true); FileSystem hdfs = org.apache.hadoop.fs.FileSystem.get(configuration); ParquetMetadata parquetFileReader = ParquetFileReader.readFooter(configuration, new org.apache.hadoop.fs.Path(path)); MessageType schema = parquetFileReader.getFileMetaData().getSchema(); System.out.println("-----Schema-----"); System.out.println(schema); env.readFile(new ParquetRowInputFormat(new org.apache.flink.core.fs.Path(path), schema), path) .setParallelism(1) .map(new MapFunction<Row, String>() { @Override public String map(Row row) throws Exception { try { String source = String.valueOf(row.getField(1)); String flag = String.valueOf(row.getField(35)); return source + "\t" + flag; } catch (Exception e) { e.printStackTrace(); return null; } } }).print(); env.execute("ReadParquetByJava"); } }

四.总结
Parquet 通过其列式存储与空间压缩应用于多种大数据场景,上面给出了 parquet 文件转 DataStream 的两种方式,同理也可以使用 DataSet 加载为静态数据,上面两个方法都给出了 hdfs: FileSystem 变量但都没有使用,下面说下使用场景:
一般分布式任务读取时对应的 parquet 文件不是一个而是多个,所以需要从目标目录中找出第一个合法的 parquet 文件供 ParquetFileReader 解析对应的 schema,hdfs 的任务就是通过目标路径获取第一个合法文件使用。
def getFirstFilePath(hdfsPath: String, hdfs: FileSystem): String = { val files = hdfs.listFiles(new org.apache.hadoop.fs.Path(hdfsPath), false) var flag = true var firstFile = "" while (flag) { if (files.hasNext) { firstFile = files.next().getPath.getName if (!firstFile.equalsIgnoreCase(s"_SUCCESS") && !firstFile.startsWith(".") && firstFile.endsWith(".parquet")) { flag = false } } else { flag = false } } hdfsPath + "/" + firstFile }

合法的判断需要三个条件:
A.不包含 _SUCCESS
B.不以 '.' 开头
C.以 '.parquet' 结尾


