这次我们分享数据挖掘领域中较为经典的一个算法 AdaBoost,首先请看本次分享的目录梗概:
- 数据集简介
- AdaBoost算法简介
- AdaBoost算法实例解析
- 代码展示
- 参考文献
一、数据集简介
数据集地址:http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scen
该数据集共包括Indian Pines、Salinas、Pavia Centre and University、Cuprite、Kennedy Space Center以及Bostwana六个数据集,每个数据集都有对应的简单介绍以及对应的下载地址,接下来我们将重点使用第一个数据集,即印第安松树。
Indian Pine 是由 AVIRIS 传感器在印第安纳州拍摄的。这个数据的大小是145*145,有224个波段,其中有效波段200个。这个数据一共有16个农作物类别。

高光谱遥感场景
数据收集人员:M Graña, MA Veganzons, B Ayerdi
在这些数据集中你可以找到一些公开可用的高光谱场景信息。所有的这些地球观测图像都是从飞机或者卫星上拍摄的。
你也可以找到更多关于高光谱传感器和遥感的信息。
印第安松树
这一场景是由AVIRIS传感器在印第安纳州西北部的印度松树试验场上采集的,该数据集像素大小为145 145,光谱反射带为224,且波长范围在0.4-2.510^(-6)米。该场景只是更大场景中的一个子集。印第安松树景观包含2/3的农业、1/3的森林或其他天然多年生植被。有两条主要的双车道公路,一条铁路,以及一些低密度住房,其他建筑结构和较小的道路。由于拍摄现场是在6月份出现的一些作物,玉米、大豆都处于生长的早期阶段,其覆盖率不到5%。可用的基本真理背指定为16类,并不是所有的都相互排斥。我们还通过去除覆盖吸水区域的带数将带树减少到200:[104-108],[150-163],220。印度松树的数据可通过 Pursue's univeristy MultiSpec 的网站进行获取。

印度松树场景的基本分类及各自的样本编号
二、AdaBoost算法简介
1. 基本介绍
AdaBoost,其全称为Adaptive Boosting,中文翻译为自适应增强,简单来说,它是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确以及上次的总体分类的准确率来确定每个样本的权值。将修改过权值的新的数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。
AdaBoost的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
2. 算法介绍
我们来将AdaBoost的迭代算法分为3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权重:1/N;
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去;
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率较小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
AdaBoost算法示意图

Boosting是将弱的模型整合成强的模型的方法,核心思想是逐个训练模型,使当前的模型尝试纠正前面模型的错误。Boosting的方法有许多,著名的方法包括AdaBoost(Adaptive Boosting)和Gradient Boosting。
当前模型纠正错误的方法是更加关注前面模型的错误,这样的过程导致新的模型越来越关注困难的训练数据,这是AdaBoost的核心思想。
AdaBoost逐个训练模型的思想类似梯度下降。不同的是,梯度下降算法尝试通过查找最优的参数来使损失函数的值最小,而AdaBoost则是通过添加新的模型来提升模型的效果。当所有的模型训练完成之后,AdaBoost会使用类似bagging的方式来整合所有结果,只是不同的模型根据它们在带权训练数据的预测结果时拥有不同的权重。
Boosting逐个训练模型的缺点是无法并行,当前模型只有在前面的模型训练完成之后才能开始训练。
三、AdaBoost算法实例解析
我们知道,AdaBoost算法是基于错误来提升分类器的性能的,我们来总结一下AdaBoost的运行过程,请看:
- 训练数据中的每个样本,并赋予其一个权重(构成向量D)。一开始,这些权重都初始化成 相等的值;
- 在训练数据上训练出一个弱分类器,并计算该分类器的错误率,基于这些错误率计算弱分类器的权重值α,为从所有弱分类器中得到最终的分类结果;
错误率计算公式:

权重值计算公式:
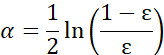
- 在同一数据集上再次训练弱分类器,重新调整每个样本的权重,对权重向量D进行更新,其中正确分类的样本的权重将会降低,而错分样本的权重将会提高。
请看权值更新的计算公式:

- 计算出D之后,AdaBoost开始进入下一轮迭代,计算α值,更新权重向量D,AdaBoost算法将不断重复训练和权重调整的过程,直到训练错误率为0或者弱分类器的数目达到用户指定值为止。
请看算法示例:给定如下图所示的训练样本,弱分类器采用平行于坐标轴的直线,我们将通过AdaBoost算法来实现强分类的过程。

我们来对上述数据做下简单的解释:我们根据样本点X和Y的对应关系,将这10个训练数据分为两类,为了方便小伙伴们更直观的去看,我们通过matplotlib将其展示出来,请看图示:
我们来看一下上述展示初始值的代码:
# -*- coding: utf-8 -*-
"""
@author: 石璞东(微信公众号:hahaCoder)
@software: PyCharm
@file: adaboost_matplotlib.py
@time: 2020/11/12 9:28 上午
"""
import matplotlib.markers as mmarkers
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
def mscatter(x, y, ax=None, m=None, **kw):
if not ax: ax = plt.gca()
sc = ax.scatter(x, y, **kw)
if (m is not None) and (len(m) == len(x)):
paths = []
for marker in m:
if isinstance(marker, mmarkers.MarkerStyle):
marker_obj = marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path = marker_obj.get_path().transformed(
marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
return sc
N = 10 # 假设有10个点
x = [1, 2, 3, 4, 6, 6, 7, 8, 9, 10]
y = [5, 2, 1, 6, 8, 5, 9, 7, 8, 2]
c = [1, 1, -1, -1, 1, -1, 1, 1 , -1, -1] # 有2个类别,标签分别是1,-1
m = {1: 'o', -1: '+'}
cm = list(map(lambda x: m[x], c)) # 将相应的标签改为对应的marker
fig, ax = plt.subplots()
scatter = mscatter(x, y, c=c, m=cm, ax=ax, cmap=plt.cm.RdYlBu)
# 添加坐标点注释信息
plt.annotate('(1,5)', xy=(2,2), xytext=(1.1,5.1))
plt.annotate('(2,2)', xy=(2,2), xytext=(2.1,2.1))
plt.annotate('(6,8)', xy=(2,2), xytext=(6.1,8.1))
plt.annotate('(7,9)', xy=(2,2), xytext=(7.1,9.1))
plt.annotate('(8,7)', xy=(2,2), xytext=(8.1,7.1))
plt.annotate('(3,1)', xy=(2,2), xytext=(3.1,1.1),color="r")
plt.annotate('(4,6)', xy=(2,2), xytext=(4.1,6.1),color="r")
plt.annotate('(6,5)', xy=(2,2), xytext=(6.1,5.1),color="r")
plt.annotate('(9,8)', xy=(2,2), xytext=(9.1,8.1),color="r")
plt.annotate('(10,2)', xy=(2,2), xytext=(10.1,2.1),color="r")
# 修改默认坐标轴的刻度信息
plt.xticks(list(range(-1,12)))
plt.yticks(list(range(-1,12)))
plt.xlim(0,11)
plt.ylim(0,11)
# 添加注释信息
plt.xlabel(xlabel="样本点X")
plt.ylabel(ylabel="样本点Y")
plt.title("Adaboost算法讲解--初始值分布")
plt.show()图中用"+"表示类别"-1",用"蓝色的小点"表示类别"1",提前说明一下,本例中我们使用水平或者垂直的直线作为分类器。下图中是我们在本例中使用的三个分类器,请看:
1. 初始化:
首先需要初始化训练样本数据的权值分布,每一个训练样本最开始时都被赋予相同的权值:wi=1/N,其中N表示训练数据总数,在本例中,N=10,故我们可以得到训练样本初始化之后的权值分布情况,请看下表:

2. 第一次迭代
我们将初始化的权值分布记为D1(10个数据,每个数据的权值皆初始化为0.1),即D1=[0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1]。
- 当阈值取2.5时,误差率为0.3(x1<2.5时取1,x1>2.5时取-1,则5、7、8分错,误差率为0.3)
- 当阈值取6.5时,(x2<6.5时取-1,x2>6.5时取1,则1、2、9分错,误差率为0.3)
- 当阈值取8.5时,误差率为0.3(x1<8.5时取1,x1>8.5时取-1,则3、4、6分错,误差率为0.3)
可以看到,无论阈值取2.5还是8.5,总会分错3个样本,故我们可以任意取其中一个阈值作为我们第一次迭代之后的分类器。

我们知道,在选中上述分类器的情况下,样本点5、7、8会被分错,我们来看一下关于误差率、权重值的计算(在上述内容中我们已经给出了计算公式,故这里不再赘述):
我们可以得出结论,被分错样本的权值之和会影响误差率e1,误差率e1会影响基本分类器在最终分类器所占的权重值α,请看经过第一次迭代分类之后的数据分布情况(图中绿色的点表示第一次迭代之后错分的点,即(6,8)、(7,9)、(8,7)):

请看代码:
import matplotlib.markers as mmarkers
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
def mscatter(x, y, ax=None, m=None, **kw):
if not ax: ax = plt.gca()
sc = ax.scatter(x, y, **kw)
if (m is not None) and (len(m) == len(x)):
paths = []
for marker in m:
if isinstance(marker, mmarkers.MarkerStyle):
marker_obj = marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path = marker_obj.get_path().transformed(
marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
return sc
N = 10 # 假设有10个点
x = [1, 2, 3, 4, 6, 6, 7, 8, 9, 10]
y = [5, 2, 1, 6, 8, 5, 9, 7, 8, 2]
c = [1, 1, -1, -1, 1, -1, 1, 1 , -1, -1] # 有2个类别,标签分别是1,-1
m = {1: 'o', -1: '+'}
cm = list(map(lambda x: m[x], c)) # 将相应的标签改为对应的marker
fig, ax = plt.subplots()
scatter = mscatter(x, y, c=c, m=cm, ax=ax, cmap=plt.cm.RdYlBu)
# 添加坐标点注释信息
plt.annotate('(1,5)', xy=(2,2), xytext=(1.1,5.1))
plt.annotate('(2,2)', xy=(2,2), xytext=(2.1,2.1))
plt.annotate('(6,8)', xy=(7,10), xytext=(6.1,8.1),color="green",weight="bold")
plt.annotate('(7,9)', xy=(2,2), xytext=(7.1,9.1),color="green",weight="bold")
plt.annotate('(8,7)', xy=(2,2), xytext=(8.1,7.1),color="green",weight="bold")
plt.annotate('(3,1)', xy=(2,2), xytext=(3.1,1.1),color="r")
plt.annotate('(4,6)', xy=(2,2), xytext=(4.1,6.1),color="r")
plt.annotate('(6,5)', xy=(2,2), xytext=(6.1,5.1),color="r")
plt.annotate('(9,8)', xy=(2,2), xytext=(9.1,8.1),color="r")
plt.annotate('(10,2)', xy=(2,2), xytext=(10.1,2.1),color="r")
# 第一次迭代之后所产生的分类器1
x1 = [2.5,2.5]
y1= [0,11]
plt.plot(x1,y1,label="分类器1")
# 修改默认坐标轴的刻度信息
plt.xticks(list(range(-1,12)))
plt.yticks(list(range(-1,12)))
plt.xlim(0,11)
plt.ylim(0,11)
# 添加注释信息
plt.xlabel(xlabel="样本点X")
plt.ylabel(ylabel="样本点Y")
plt.title("Adaboost算法讲解--第一次迭代")
plt.show()我们更新完训练样本数据的权值分布之后,可以将其用在我们第二轮的迭代中。关于正确分类的样本1、2、3、4、6、7、8(共7个)的权值更新如下所示:

故在第一轮迭代之后,我们可以得到各个样本数据最新的权值分布,我们将第一次迭代之后的权值分布记为D2,则D2=[1/14,1/14,1/14,1/14,1/6,1/14,1/6,1/6,1/14,1/14]
观察上述数据,经过第一轮迭代之后,由于5、7、8被分类器1分错,故它们的权值由0.1增大到1/6;其他7个数据均被正确分类,故其权值由0.1减小到1/14,请看下图的权值分布变换情况:
故我们可以得第一个分类函数:f1(x)= α1H1(x) = 0.4236H1(x)。此时,组合一个基本分类器sign(f1(x))作为强分类器在训练数据集上有3个误分类点(即5、7、8),此时强分类器的训练错误为:0.3。
3. 第二次迭代
在权值分布D2的情况下,我们再取三个弱分类器h1、h2、h3中误差率最小的分类器作为第二个基本分类器H2(x):
- 当取弱分类器h1=X1=2.5时,此时被错分的样本点为5、7、8 :误差率e=1/6+1/6+1/6=3/6=1/2;
- 当取弱分类器h2=X1=8.5时,此时被错分的样本点为3 、4、6:误差率e=1/14+1/14+1/14=3/14;
- 当取弱分类器h3=X2=6.5时,此时被错分的样本点为1、2、9:误差率e=1/14+1/14+1/14=3/14;
因此,我们选取当前最小的分类器h2作为第二个基本分类器H2(x),我们知道H2(x)分类器将样本点3、4、6分错了,从D2的权值分布中,我们知道,D2(3) = 1/14、D2(4) = 1/14、D2(6) = 1/14,故可得H2(x)在训练数据集上的误差率:

这样,第2轮迭代后,最后得到各个样本数据新的权值分布: D3=[1/22,1/22,1/6,1/6,7/66,1/6,7/66,7/66,1/22,1/22]。
请看经过第二次迭代分类之后的数据分布情况(图中橙色的点表示第二次迭代之后错分的点,即(3,1)、(4,6)、(6,5)):
请看代码:
# -*- coding: utf-8 -*-
"""
@author: 石璞东(微信公众号:hahaCoder)
@software: PyCharm
@file: adaboost_matplotlib.py
@time: 2020/11/12 9:28 上午
"""
import matplotlib.markers as mmarkers
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
def mscatter(x, y, ax=None, m=None, **kw):
if not ax: ax = plt.gca()
sc = ax.scatter(x, y, **kw)
if (m is not None) and (len(m) == len(x)):
paths = []
for marker in m:
if isinstance(marker, mmarkers.MarkerStyle):
marker_obj = marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path = marker_obj.get_path().transformed(
marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
return sc
N = 10 # 假设有10个点
x = [1, 2, 3, 4, 6, 6, 7, 8, 9, 10]
y = [5, 2, 1, 6, 8, 5, 9, 7, 8, 2]
c = [1, 1, -1, -1, 1, -1, 1, 1 , -1, -1] # 有2个类别,标签分别是1,-1
m = {1: 'o', -1: '+'}
cm = list(map(lambda x: m[x], c)) # 将相应的标签改为对应的marker
fig, ax = plt.subplots()
scatter = mscatter(x, y, c=c, m=cm, ax=ax, cmap=plt.cm.RdYlBu)
# 添加坐标点注释信息
plt.annotate('(1,5)', xy=(2,2), xytext=(1.1,5.1))
plt.annotate('(2,2)', xy=(2,2), xytext=(2.1,2.1))
# 第一次分类器分类错误的样本点
plt.annotate('(6,8)', xy=(7,10), xytext=(6.1,8.1),color="green",weight="bold")
plt.annotate('(7,9)', xy=(2,2), xytext=(7.1,9.1),color="green",weight="bold")
plt.annotate('(8,7)', xy=(2,2), xytext=(8.1,7.1),color="green",weight="bold")
# 第二次分类器分类错误的样本点
plt.annotate('(3,1)', xy=(2,2), xytext=(3.1,1.1),color="orange",weight="bold")
plt.annotate('(4,6)', xy=(2,2), xytext=(4.1,6.1),color="orange",weight="bold")
plt.annotate('(6,5)', xy=(2,2), xytext=(6.1,5.1),color="orange",weight="bold")
plt.annotate('(9,8)', xy=(2,2), xytext=(9.1,8.1))
plt.annotate('(10,2)', xy=(2,2), xytext=(10.1,2.1))
# 第一次迭代之后所产生的分类器1
x1 = [2.5,2.5]
y1= [0,11]
plt.plot(x1,y1,label="分类器1")
# 第二次迭代之后产生的分类器2
x2 = [8.5,8.5]
plt.plot(x2,y1,label="分类器2")
# 修改默认坐标轴的刻度信息
plt.xticks(list(range(-1,12)))
plt.yticks(list(range(-1,12)))
plt.xlim(0,11)
plt.ylim(0,11)
# 添加注释信息
plt.xlabel(xlabel="样本点X")
plt.ylabel(ylabel="样本点Y")
plt.title("Adaboost算法讲解--第二次迭代")
plt.show()下表给出了权值分布的变换情况:

可得分类函数:f2(x)=0.4236H1(x) + 0.6496H2(x)。此时,组合两个基本分类器sign(f2(x))作为强分类器在训练数据集上有3个误分类点(即3、4、6),此时强分类器的训练错误为:0.3。
3. 第三次迭代
我们挑选出上述表格中的关键内容,为了方便小伙伴们更清晰直观的查看内容,我们做了下图中所示的处理,请看:

在权值分布D3的情况下,再取三个弱分类器h1、h2和h3中误差率最小的分类器作为第3个基本分类器H3(x):
- 当取弱分类器h1=X1=2.5时,此时被错分的样本点为5、7、8:误差率e=7/66+7/66+7/66=7/22;
- 当取弱分类器h2=X1=8.5时,此时被错分的样本点为3、4、6:误差率e=1/6+1/6+1/6=1/2=0.5;
- 当取弱分类器h3=X2=6.5时,此时被错分的样本点为1、2、9:误差率e=1/22+1/22+1/22=3/22;
因此,取当前最小的分类器h3作为第3个基本分类器H3(x):
这样,第3轮迭代后,得到各个样本数据新的权值分布为: D4=[1/6,1/6,11/114,11/114,7/114,11/114,7/114,7/114,1/6,1/38]。
请看经过第三次迭代分类之后的数据分布情况(图中粉色的点表示第三次迭代之后错分的点,即(1,5)、(2,2)、(9,8)):

请看代码:
# -*- coding: utf-8 -*-
"""
@author: 石璞东(微信公众号:hahaCoder)
@software: PyCharm
@file: adaboost_matplotlib.py
@time: 2020/11/12 9:28 上午
"""
import matplotlib.markers as mmarkers
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
def mscatter(x, y, ax=None, m=None, **kw):
if not ax: ax = plt.gca()
sc = ax.scatter(x, y, **kw)
if (m is not None) and (len(m) == len(x)):
paths = []
for marker in m:
if isinstance(marker, mmarkers.MarkerStyle):
marker_obj = marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path = marker_obj.get_path().transformed(
marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
return sc
N = 10 # 假设有10个点
x = [1, 2, 3, 4, 6, 6, 7, 8, 9, 10]
y = [5, 2, 1, 6, 8, 5, 9, 7, 8, 2]
c = [1, 1, -1, -1, 1, -1, 1, 1 , -1, -1] # 有2个类别,标签分别是1,-1
m = {1: 'o', -1: '+'}
cm = list(map(lambda x: m[x], c)) # 将相应的标签改为对应的marker
fig, ax = plt.subplots()
scatter = mscatter(x, y, c=c, m=cm, ax=ax, cmap=plt.cm.RdYlBu)
# 添加坐标点注释信息
# 第一次分类器分类错误的样本点
plt.annotate('(6,8)', xy=(7,10), xytext=(6.1,8.1),color="green",weight="bold")
plt.annotate('(7,9)', xy=(2,2), xytext=(7.1,9.1),color="green",weight="bold")
plt.annotate('(8,7)', xy=(2,2), xytext=(8.1,7.1),color="green",weight="bold")
# 第二次分类器分类错误的样本点
plt.annotate('(3,1)', xy=(2,2), xytext=(3.1,1.1),color="orange",weight="bold")
plt.annotate('(4,6)', xy=(2,2), xytext=(4.1,6.1),color="orange",weight="bold")
plt.annotate('(6,5)', xy=(2,2), xytext=(6.1,5.1),color="orange",weight="bold")
# 第三次分类器分类错误的样本点
plt.annotate('(1,5)', xy=(2,2), xytext=(1.1,5.1),color="#FF3333",weight="bold")
plt.annotate('(2,2)', xy=(2,2), xytext=(2.1,2.1),color="#FF3333",weight="bold")
plt.annotate('(9,8)', xy=(2,2), xytext=(9.1,8.1),color="#FF3333",weight="bold")
plt.annotate('(10,2)', xy=(2,2), xytext=(10.1,2.1))
# 第一次迭代之后所产生的分类器1
x1 = [2.5,2.5]
y1= [0,11]
plt.plot(x1,y1,label="分类器1")
# 第二次迭代之后产生的分类器2
x2 = [8.5,8.5]
plt.plot(x2,y1,label="分类器2")
# 第二次迭代之后产生的分类器2
x3 = [0,11]
y3 = [6.5,6.5]
plt.plot(x3,y3,label="分类器3")
# 显示图例
plt.legend()
# 修改默认坐标轴的刻度信息
plt.xticks(list(range(-1,12)))
plt.yticks(list(range(-1,12)))
plt.xlim(0,11)
plt.ylim(0,11)
# 添加注释信息
plt.xlabel(xlabel="样本点X")
plt.ylabel(ylabel="样本点Y")
plt.title("Adaboost算法讲解--第三次迭代")
plt.show()下表给出了权值分布的变换情况:

可得分类函数:f3(x)=0.4236H1(x) + 0.6496H2(x)+0.9229H3(x)。此时,组合三个基本分类器sign(f3(x))作为强分类器,在训练数据集上有0个误分类点。至此,整个训练过程结束。
整合所有分类器,可得最终的强分类器为:

四、代码展示
我们用了较大的篇幅介绍了AdaBoost算法,在最后一部分内容中,我们将结合我们第一部分介绍的数据集,来完成高光谱的一个分类算法。
首先,我们下载对应的数据集,并根据自己的喜好保存在对应的文件夹内:

接下来我们读入数据集并统计各类像元数,请看代码:
def pre_process(f1_name, f2_name, f1_str, f2_str,):
# 处理数据:返回训练数据、测试数据
# f1_name,f2_name:特征mat数据,标签mat数据,f1_str,f2_str:数据的字典键名
x_data = scio.loadmat(f1_name)[f1_str] #读取数据
y_data = scio.loadmat(f2_name)[f2_str]
# 统计各类像元数
cls = len(np.unique(y_data))
cls_count = {}
for i in range(y_data.shape[0]):
for j in range(y_data.shape[1]):
if y_data[i][j] in [x for x in range(cls)]:
if y_data[i][j] not in cls_count:
cls_count[y_data[i][j]] = 0
cls_count[y_data[i][j]] += 1
need_label = np.zeros([y_data.shape[0], y_data.shape[1]])
print(need_label.shape)
print(cls_count)我们在控制台查看一下cls_count对象的具体信息:

首先,数据集大小为145*145像素,这一点我们在第一部分关于数据集的介绍中已经说明;其次,打印的信息是17个类别及其对应每类的样本数,细心的小伙伴会发现,官网告诉我们只有16种类别,我们细心观察控制台打印的cls_count信息,其中类别0对应了10776个样本,所以在数据的预处理过程中,我们必须除掉0这个非分类的类别,把其他所有需要分类的元素提取出来。
# 除掉 0 这个非分类的类,把所有需要分类的元素提取出来
for i in range(y_data.shape[0]):
for j in range(y_data.shape[1]):
if y_data[i][j] != 0:
need_label[i][j] = y_data[i][j]接下来,我们划分测试集(所占比例为30%)与训练集:
# 划分训练集、测试集(test_size=0.3,分层抽样)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=8, stratify=y)
return x_train, x_test, y_train, y_test完成数据的预处理之后,我们来定义本例中超参数搜索的函数(我们使用随机搜索),请看代码:
def tuning_params(param_grid, model):
# 参数调节:返回最佳参数、最佳分数
# param_grid,参数字典; model,调参模型;
grid_search = RandomizedSearchCV(model, param_grid, scoring='accuracy')
grid_search.fit(x_train, y_train)
print('bes2 t_params:', grid_search.best_params_)
print('best_score:', grid_search.best_score_)接下来,我们通过混淆矩阵来对每次的迭代分类结果进行精度评估,请看代码:
def plot_confusion_matrix(cm, labels_name, title):
# 混淆矩阵图像
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] # 归一化
plt.imshow(cm, interpolation='nearest') # 在特定的窗口上显示图像
plt.title(title) # 图像标题
plt.colorbar()
num_local = np.array(range(len(labels_name)))
plt.xticks(num_local, labels_name, rotation=90) # 将标签印在x轴坐标上
plt.yticks(num_local, labels_name) # 将标签印在y轴坐标上
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()最后,我们在训练集上进行训练,请看代码:
model = AdaBoostClassifier(base_estimator=DecisionTreeClassifier())
model.fit(x_train,y_train)写完代码之后,我们来控制台看两个比较重要的信息:
- 随机搜索帮助我们找到的最优参数和拟合分数

- 混淆矩阵

我们来对上述控制台打印出的混淆矩阵做一下简单的解释:每一行的数目之和是对应该类别的真实数量,比如第一行8+1+5=14表示我们经我们预测之后Alfalfa的数量为14,而官网告诉我们真实数量为46,根据控制台信息,我们最好的拟合分数只有66.76%,看来我们的训练过程还是不够牛逼呀!
对角线代表预测模型是正确的,而其他的位置代表预测错误,这样的一个混淆矩阵能够很快的帮助我们分析每个类别的误分类情况,从而帮助我们分析调整。
为了达到更高的拟合分数,我们来调整一下对应的参数,请看代码:
- 方案一
model=AdaBoostClassifier(base_estimator=DecisionTreeClassifier(min_samples_split=37,min_samples_leaf=6,max_depth=9))
params={'n_estimators':range(40,120,5)}
tuning_params(params,model)- 方案二
model=AdaBoostClassifier(base_estimator=DecisionTreeClassifier(min_samples_split=37,min_samples_leaf=6,max_depth=9),n_estimators=60)
model.fit(x_train, y_train)
y_pre = model.predict(x_test)我在我的小mac上跑最后两个优化方案的时候,等了得有10几分钟都没跑出来,我生气了,所以直接关掉了,哈哈,小伙伴们谁跑出来了记得私信我一下哟!
最后,我们再来看直观的看一下绘制出的混淆矩阵:
以上就是我们本次基于AdaBoost的高光谱分类算法的所有内容,小伙伴们看明白了吗?获取更多咨询,请关注微信公众号hahaCoder或浏览器搜索关键词石璞东。
