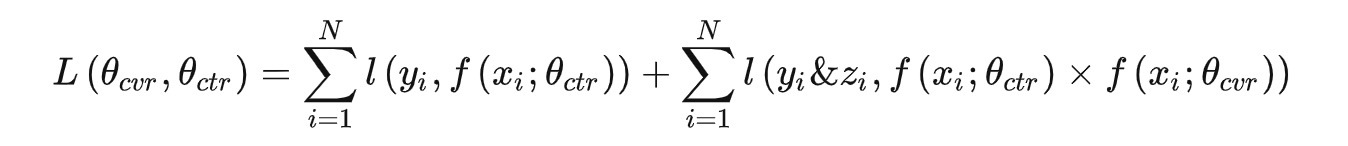多任务学习背景
目前工业中使用的推荐算法已不只局限在单目标(ctr)任务上,还需要关注后续的转化链路,如是否评论、收藏、加购、购买、观看时长等目标。
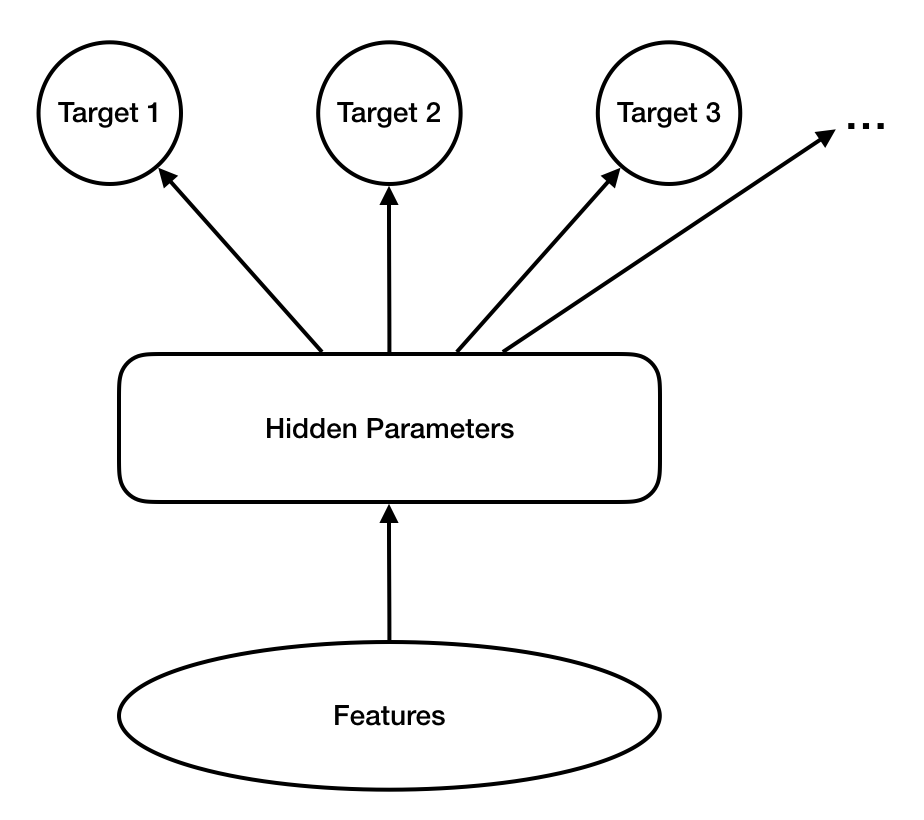
常见的多目标优化模型是从每个优化目标单独的模型网络出发,通过让这些网络在底层共享参数,实现各目标相关模型的适当程度的独立性和相关性。这类的模型框架可以用上图的结构来概括。不论底层如何共享参数,这些网络在最后几层都要伸出一些独立分支来预测各个目标的最终值。此类网络的概率模型可以用下述公式描述:

其中l,m 为目标,x为样本特征,H为模型。这里做了各目标独立的假设。
DBMTL介绍
DBMTL(Deep Bayesian Multi-Target Learning)的一个出发点就是解决上述问题。事实上套用简单的贝叶斯公式,概率模型可以写成:

如下图所示,DBMTL与传统MTL结构(认为各目标独立)最主要差别在于构建了target node之间的贝叶斯网络,显式建模了目标间可能存在的因果关系。因为在实际业务中,用户的很多行为往往存在明显的序列先后依赖关系,例如在信息流场景,用户要先点进图文详情页,才会进行后续的浏览/评论/转发/收藏 等操作。DBMTL在模型结构中体现了这些关系,因此,往往能学到更好的结果。

下图是DBMTL模型的具体实现。网络包含输入层、共享embedding层、共享层,区别层和贝叶斯层。

- 共享embedding层是一个共享的lookup table,为各个target训练所共享。
- 共享层和分离层是一般的multilayer perceptron (MLP),分别建模各目标的共享/区别表示。
- Bayesian层是DBMTL中最重要的部分。它实现了如下的概率模型:

其对应的log-likelihood损失函数为:
实际应用中,对不同目标调权仍有着较大的现实作用。当对目标赋予不同权重时,相当于把损失函数重新表达为:
在网络的贝叶斯层中,函数f1, f2, f3 被实现为全连接的MLP,以学习目标间的隐含因果关系。他们把函数输入变量的embedding级联作为输入,并输入一个表示函数输出变量的embedding。每一个目标的embedding最后再经过一层MLP以输出最终目标的概率。
代码实现
基于EasyRec推荐算法框架,我们实现了DBMTL算法,具体实现可移步至github:EasyRec-DBMTL。
EasyRec介绍:EasyRec是阿里云计算平台机器学习PAI团队开源的大规模分布式推荐算法框架,EasyRec 正如其名字一样,简单易用,集成了诸多优秀前沿的推荐系统论文思想,并且在实际工业落地中取得优良效果的特征工程方法,集成训练、评估、部署,与阿里云产品无缝衔接,可以借助 EasyRec 在短时间内搭建起一套前沿的推荐系统。作为阿里云的拳头产品,现已稳定服务于数百个企业客户。
模型前馈网络
def build_predict_graph(self):
"""Forward function.
Returns:
self._prediction_dict: Prediction result of two tasks.
"""
# 此处从共享embedding层后的tensor(self._features)开始,省略其生成逻辑
# shared layer
if self._model_config.HasField('bottom_dnn'):
bottom_dnn = dnn.DNN(
self._model_config.bottom_dnn,
self._l2_reg,
name='bottom_dnn',
is_training=self._is_training)
bottom_fea = bottom_dnn(self._features)
else:
bottom_fea = self._features
# MMOE block
if self._model_config.HasField('expert_dnn'):
mmoe_layer = mmoe.MMOE(
self._model_config.expert_dnn,
l2_reg=self._l2_reg,
num_task=self._task_num,
num_expert=self._model_config.num_expert)
task_input_list = mmoe_layer(bottom_fea)
else:
task_input_list = [bottom_fea] * self._task_num
tower_features = {}
# specific layer
for i, task_tower_cfg in enumerate(self._model_config.task_towers):
tower_name = task_tower_cfg.tower_name
if task_tower_cfg.HasField('dnn'):
tower_dnn = dnn.DNN(
task_tower_cfg.dnn,
self._l2_reg,
name=tower_name + '/dnn',
is_training=self._is_training)
tower_fea = tower_dnn(task_input_list[i])
tower_features[tower_name] = tower_fea
else:
tower_features[tower_name] = task_input_list[i]
tower_outputs = {}
relation_features = {}
# bayesian network
for task_tower_cfg in self._model_config.task_towers:
tower_name = task_tower_cfg.tower_name
relation_dnn = dnn.DNN(
task_tower_cfg.relation_dnn,
self._l2_reg,
name=tower_name + '/relation_dnn',
is_training=self._is_training)
tower_inputs = [tower_features[tower_name]]
for relation_tower_name in task_tower_cfg.relation_tower_names:
tower_inputs.append(relation_features[relation_tower_name])
relation_input = tf.concat(
tower_inputs, axis=-1, name=tower_name + '/relation_input')
relation_fea = relation_dnn(relation_input)
relation_features[tower_name] = relation_fea
output_logits = tf.layers.dense(
relation_fea,
task_tower_cfg.num_class,
kernel_regularizer=self._l2_reg,
name=tower_name + '/output')
tower_outputs[tower_name] = output_logits
self._add_to_prediction_dict(tower_outputs)
Loss计算
def build(loss_type, label, pred, loss_weight=1.0, num_class=1, **kwargs):
if loss_type == LossType.CLASSIFICATION:
if num_class == 1:
return tf.losses.sigmoid_cross_entropy(
label, logits=pred, weights=loss_weight, **kwargs)
else:
return tf.losses.sparse_softmax_cross_entropy(
labels=label, logits=pred, weights=loss_weight, **kwargs)
elif loss_type == LossType.CROSS_ENTROPY_LOSS:
return tf.losses.log_loss(label, pred, weights=loss_weight, **kwargs)
elif loss_type in [LossType.L2_LOSS, LossType.SIGMOID_L2_LOSS]:
logging.info('%s is used' % LossType.Name(loss_type))
return tf.losses.mean_squared_error(
labels=label, predictions=pred, weights=loss_weight, **kwargs)
elif loss_type == LossType.PAIR_WISE_LOSS:
return pairwise_loss(pred, label)
else:
raise ValueError('unsupported loss type: %s' % LossType.Name(loss_type))
def _build_loss_impl(self,
loss_type,
label_name,
loss_weight=1.0,
num_class=1,
suffix=''):
loss_dict = {}
if loss_type == LossType.CLASSIFICATION:
loss_name = 'cross_entropy_loss' + suffix
pred = self._prediction_dict['logits' + suffix]
elif loss_type in [LossType.L2_LOSS, LossType.SIGMOID_L2_LOSS]:
loss_name = 'l2_loss' + suffix
pred = self._prediction_dict['y' + suffix]
else:
raise ValueError('invalid loss type: %s' % LossType.Name(loss_type))
loss_dict[loss_name] = build(loss_type,
self._labels[label_name],
pred,
loss_weight, num_class)
return loss_dict
def build_loss_graph(self):
"""Build loss graph for multi task model."""
for task_tower_cfg in self._task_towers:
tower_name = task_tower_cfg.tower_name
loss_weight = task_tower_cfg.weight * self._sample_weight
if hasattr(task_tower_cfg, 'task_space_indicator_label') and \
task_tower_cfg.HasField('task_space_indicator_label'):
in_task_space = tf.to_float(
self._labels[task_tower_cfg.task_space_indicator_label] > 0)
loss_weight = loss_weight * (
task_tower_cfg.in_task_space_weight * in_task_space +
task_tower_cfg.out_task_space_weight * (1 - in_task_space))
# EasyRec框架会自动对self._loss_dict中的loss进行加和。
self._loss_dict.update(
self._build_loss_impl(
task_tower_cfg.loss_type,
label_name=self._label_name_dict[tower_name],
loss_weight=loss_weight,
num_class=task_tower_cfg.num_class,
suffix='_%s' % tower_name))
return self._loss_dict
应用
由于其卓越的算法效果,DBMTL在PAI上被大量使用。
以某直播推荐业务为例,该场景有is_click, is_view, view_costtime, is_on_mic, on_mic_duration多个目标,其中is_click, is_view, is_on_mic为二分类任务,view_costtime, on_mic_duration为预测时长的回归任务。用户行为的依赖关系为:
- is_click=> is_view
- is_click+is_view=> view_costtime
- is_click=> is_on_mic
- is_click+is_on_mic => on_mic_duration
因此配置如下:
dbmtl {
bottom_dnn {
hidden_units: [512, 256]
}
task_towers {
tower_name: "is_click"
label_name: "is_click"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "is_view"
label_name: "is_view"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "view_costtime"
label_name: "view_costtime"
loss_type: L2_LOSS
metrics_set: {
mean_squared_error {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click", "is_view"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "is_on_mic"
label_name: "is_on_mic"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "on_mic_duration"
label_name: "on_mic_duration"
loss_type: L2_LOSS
metrics_set: {
mean_squared_error {}
}
dnn {
hidden_units: [128, 96, 64]
}
relation_tower_names: ["is_click", "is_on_mic"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
l2_regularization: 1e-6
}
embedding_regularization: 5e-6
}
值得一提的是,DBMTL模型上线后,相比GBDT+FM(围观单目标)线上围观率提升18%,上麦率提升14%。
参考文献
注:本文图片及公式均引用自论文:DBMTL论文
若有收获,就点个赞吧