作者:柏锐
在关系型数据库的查询中join是一个十分常见的操作,通过将几个表关联起来,用户可以在遵守数据库设计范式的前提下高效获得信息。在分析类查询中,大表之间(或大表与小表)的 Join 通常使用 Hash Join 实现,这通常也是查询的性能瓶颈之一,因此如何优化join的查询性能也是计算引擎的重点。
Runtime Filter介绍
基本原理
Runtime Filter是[4]中提到的在数据库中广泛使用的一种优化技术,其基本原理是通过在join的probe端提前过滤掉那些不会命中join的输入数据来大幅减少join中的数据传输和计算,从而减少整体的执行时间。例如对于下面这条语句的原始执行计划如下,其中sales是一个事实表, items是一个纬度表:
SELECT*FROMsalesJOINitemsONsales.item_id=items.idWHEREitems.price>100

如上图左半部分所示,在进行join运算的时候不仅需要把全量的sales数据传输到join算子里去,而且每一行sales数据都需要进行join运算(包括算哈希值、比较运算等)。这里如果items.price > 100的选择率比较高,比如达到50%,那么sales表中的大部分数据是肯定不会被join上,如果提前进行过滤掉,可以减少数据的传输和计算的开销。
上图的右半部分则是加入了runtime filter之后的执行计划,从图中可以看到在进行join的build端拉取数据的过程中新增了一个RuntimeFilterBuilder的一个算子,这个算子的作用就是在运行的过程中收集build端的信息形成runtime filter,并且发送到probe端的scan节点中去,让probe端的节点可以在scan就减少输入的数据,从而实现性能的提升。
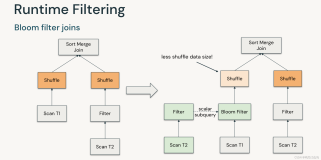
Runtime Filter对Join Reorder的影响
在当前的大多数系统中runtime filter所需要的算子都是在优化器的CBO阶段之后插入进物理执行计划的,使用的是一种基于规则的优化方法。然而在[3]中指出如果将runtime filter对执行计划所带来的影响在CBO阶段纳入考虑,则能更进一步地优化执行计划。如下图是一个例子:

在这个例子中图(a)是一个原始的查询,需要对k,mk和t三个表进行join。图(b)是在不考虑runtime filter的情况下进行CBO得到的物理执行计划。图(c)是在(b)的基础上通过基于规则的方式将runtime filter加入到物理执行计划中去。图(d)则是将runtime filter放在CBO阶段中得到的物理执行计划,我们可以看到图(d)得到的最优的物理执行计划的最终cost小于图(c)得到的计划。
然而如果直接将runtime filter加入到CBO中去,则会引起优化器的搜索空间的指数级增长。这是由于现有的优化器的CBO阶段大多基于动态规划的算法,如果将runtime filter放入CBO中,则子计划的最优解依赖于查询计划中父节点下推的filter的组合和runtime filter应用到的表的方式,这种组合将会引起搜索空间的爆炸。[3]证明了对于星型查询和雪花查询(即通过主键和外键将纬度表和事实表关联起来进行join的查询),某些join顺序在加入runtime filter之后是等价的,从而保证了优化器在CBO阶段搜索空间的线性增长。
PolarDB-X中的Runtime Filter
PolarDB-X作为一个HTAP数据库,在满足高性能的oltp场景的同时,也能实现对海量数据的高性能的分析场景。为满足客户大数据分析的需求,我们也在自研的MPP引擎中实现了Runtime Filter。其基本原理与上述基本相同,但是我们针对分布式数据库的场景也做了一些专门的优化。
Runtime Filter类型的选择
在PolarDB-X中我们选择使用bloom filter来过滤我们的数据。bloom filter有着诸多的优点:
- 类型无关:这一特性降低了我们处理多种类型的实现复杂度
- 空间复杂度低:能够提高传输效率和内存开销
- 时间复杂度低:这一时间复杂度既包括生成bloom filter的开销,也指检查是否存在的时间开销,较低的时间复杂度保证了不会引入过多的开销
当然在其他的系统中也会包含一些其他种类的过滤器,比如在Spark SQL中如果碰到过滤的是分区列且build端的数据较小,则会选择使用全量的输入数据进行动态分区的剪裁;而如果查询的数据格式是parquet或者orc这样的带索引的格式,则会生成min/max这样简单的过滤器来过滤。但这些过滤器大都针对特定场景,不够通用。
Runtime Filter生成的代价估算
Runtime Filter的生成、传输和检查会引入额外的开销,如果不加节制地滥用,不但不会提升性能,反而会导致性能的下降。由于代价估算和实现的复杂性,大多数开源系统中都只支持在broadcast join中实现Runtime Filter,比如Trino(原Presto)中就是这样的。这个做法的好处是实现简单,现有系统的改动较小,但同时也会失去很多优化的机会。
在PolarDB-X中我们将Runtime Filter的生成规则与优化器的统计信息有效地结合,通过多个纬度的数据来决定是否需要生成Runtime Filter:
- probe端的数据量的大小。如果probe端的数据量过小,即便被过滤很多的数据,其性能提升也无法弥补bloom filter的额外开销,此时我们会放弃生成bloom filter。
- bloom filter的大小。bloom filter的大小由输入的数量和fpp(错误率)决定,并和输入的数量成正比。当bloom filter太大,不仅会增大网络传输的数据,也会增大内存占用,因此我们将bloom filter的大小限制在一定范围内。
- 过滤比例。当生成的bloom filter的过滤比例太小时,将其下推到join的probe端不仅不会起到任何的效果,而且精确的过滤比例的计算是一个比较复杂的过程,这里我们使用一个近似的公式来估算过滤性:1-buildNdv*(1+fpp)/probeNdv。只有当过滤比大于一定阀值时我们才会生成runtime filter。
Runtime Filter的执行
PolarDB-X中的MPP引擎是一个为交互式分析而生的分布式的计算引擎,与Spark、Flink等不同的地方在于采用push的执行模型。这个模型的好处在于中间数据不用落盘,极大地减小了计算过程中等待的延迟,但也增加了Runtime Filter这一特性开发的复杂度。与大部分的开源计算引擎不同,PolarDB-X中的Runtime Filter不仅仅支持broadcast join,也同样支持其他各种分布式 join算法。我们仍然使用上面的一个SQL语句举例子:
SELECT*FROMsalesJOINitemsONsales.item_id=items.idWHEREitems.price>100
在开启了runtime filter之后的物理执行逻辑如下所示:

如图所示,build端会将生成的bloom filter发送到coordinator,coordinator在等待各个partition的bloom filter都发送完成之后进行一次merge操作,将合并好的bloom filter发送到FilterExec算子中去,从而实现过滤效果。通过coordinator合并之后的bloom filter的大小与单个的partition的bloom filter的大小一样大,但为每个probe端只传输一次,极大地减少了数据的传输。同时FilterExec在等待bloom filter的过程中并不会阻塞住,而是通过异步的方式接收bloom filter,从而尽量减少 bloom filter生成给延迟带来的影响。
为了进一步减少数据的传输,我们通过实现udf的方式将bloom filter下推到DN层,在DN端进行数据的过滤,从而大幅减少网络的开销。如下图所示,PolarDB-X会将bloom filter进一步下推至DN,减少了从DN拉取的数据量,从而减少了网络传输和数据解析的开销。

效果评估
我们对比了Runtime Filter在 TPCH 100G的数据集上的效果,其结果如下所示:

我们可以看到对于耗时较长的大查询,如Q9和Q21我们都取得了2~3倍的性能提升,而对于其他中型的查询也有1倍的性能提升,总体的性能提升在20%左右。
参考文献
- Bloom filter
- Dynamic Filtering in Trino
- Bitvector-aware Query Optimization for Decision Support Queries, SIGMOD 2020
- Query Evaluation Techinques for Large Databases
【相关阅读】