
本文作者 阿里云智能 资深技术专家 陈颖达
引言
阿里巴巴双11史上作业数最多,但人工干预最少的一次双11技术保障: 从动态并发调整带来的单日10亿计算节点的节省,到数据智能编排带来的高级基线单个作业数十个小时执行时间的缩短,再到全新Bubble执行模式在百万作业获取的30%以上的性能提升。 本文为大家介绍,在2020年阿里巴巴集团双11海量作业数目与突变的数据特性面前,阿里云MaxCompute 新一代 DAG 2.0 执行引擎,通过其自适应的动态执行能力和新架构上的全新计算模式,如何为双11大促数据的及时产出提供自动化保障。
1. 挑战与背景
作为阿里巴巴集团技术的练兵场,双11对于阿里核心计算平台的分布式执行调度框架而言,无疑是面对海量大规模作业时,稳定性与可扩展性方面的最好检验。今天平台上每天调度执行着超过千万的分布式作业,2020双11期间(11月1号到11月11号),作业总数超过了1.5亿,单日作业数峰值超过1600万,单日处理数据量超过1.7EB。而另一方面,如同鲁肃所言,"双 11 的「变态」, 最终会变成未来的「常态」":以计算平台每日调度执行的分布式作业数为例,每年双11的作业数,相比去年同期,都以50%以上的速度在增长,而每年双11的峰值,终究会成为来年的日常状态。
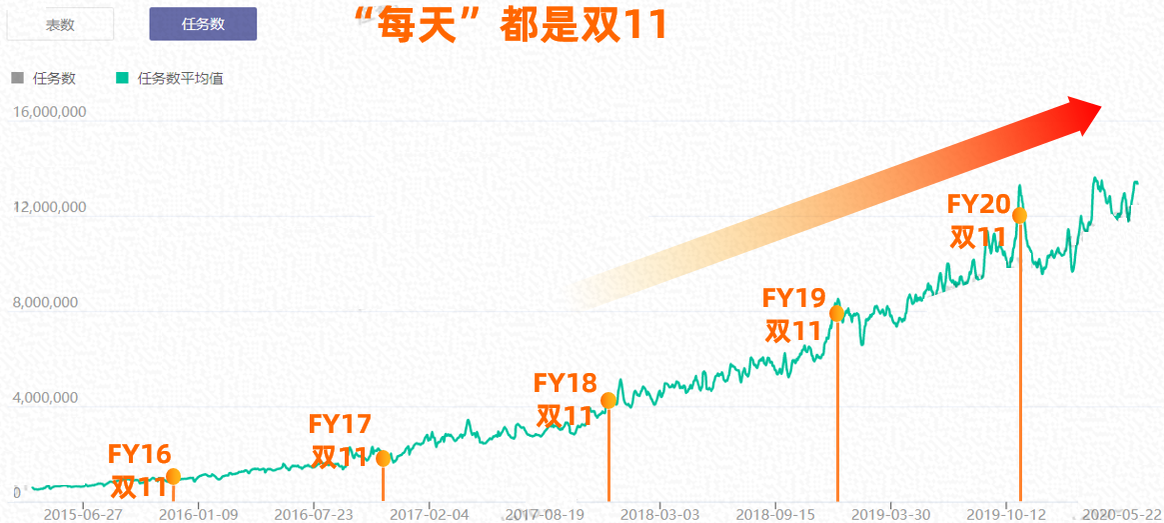
Fig. 1 每天分布作业数目
与此同时,稳定性是基石,但并不是全部。在大量的作业数目和海量数据量的背后,是作业运行模式和数据分布特点的日益多样化。尤其是在大促期间,数据的分布的变化更加剧烈。在每日千万级作业的这个量级上,尤其是面对今年"双截棍式双11"的延长大促模式,人肉运维和人工保障早已无法支撑整个大促期间,以亿为单位来计算的分布式作业。在这方面,作为MaxCompute(ODPS) 和PAI等多个计算引擎重要底座的调度执行框架,早早已经开始思考,怎样从"手拉肩扛"的人肉保障,升级到到由依赖平台自身动态能力,来针对各种规模和不同数据特点作业进行动态的自适应调优,确保即便在双11数据洪峰下,同样能减少人工干预的介入,准时准点完成数据的产出。
在这样的大背景下,DAG 2.0项目,对计算平台的核心调度执行引擎,实现了架构的更新换代。使得分布式执行引擎具备更加完善的自适应能力,以及对于上层多种计算模式的灵活支持。从2019开始亮相FY20双11后,在FY21(2020年), DAG 2.0执行引擎为上层计算平台提供了更多动态执行的能力,以及对新计算模式的支持。这些工作在刚刚过去的2020年双11中,得到了很好的检验,并为整个大促期间数据的及时稳定产出,起了保驾护航的重要作用。
2. 自适应的动态执行:"不一样"的双11
对于分布式作业而言,提交的执行计划本身的质量,很大程度上取决于引擎优化器对于作业数据特点的预判。而实际线上数据本身特性的复杂多变,以及处理逻辑的多样化,对优化器的预判准确性,会带来很大的影响。在双11大促期间的数据特性,包括数据量以及数据的分布,相比平常会有许多的不同。这使得平日的一些对重点作业的针对性调优,在"不一样"的双11数据前,其有效性会大打折扣,甚至可能起反作用。除了在大促期间对这些作业进行人肉保障以外,系统的解决方案,是将一些执行计划上的优化选择时机,从作业提交前,推迟到作业运行期间:根据实时收集的数据统计分布,来进行执行计划的动态调整。DAG 2.0引擎所提供的动态计划调整与执行能力,为解决这些挑战提供了必要的技术支持。
这里我们选择了一部分基于DAG 2.0执行引擎实现的,并在2020双11期间起关键作用的动态自适应执行的相关功能,与大家分享。
2.1 Adaptive Shuffle: 智能数据编排,解决数据倾斜
数据倾斜一直都是分布式系统中的一个痛点,虽然在整个数据处理链路中,包括存储,优化器,计算引擎运行时等各个组件,都会尽可能避免倾斜的产生,但是数据本身的分布特性,有着其自身不可改变的客观特点。而在双11大促期间,数据倾斜的场景更是随处可见。例如在商品维度,爆款单品的销量以及对应的商品数据将发生严重倾斜;而在时间维度,双11凌晨0点的成交量无疑也是倾斜的,等等等等。
由于数据倾斜带来的单个计算节点处理数据成百上千倍的增长,对应的是作业运行时间由于单点长尾,而被相应的拉长,严重情况下造成多大数个小时,甚至数十个小时的延迟。这对于需要保障产出时间SLA的重点基线作业,是无法接受的。尤其是在双11大促期间,数据分布特点的变化带来的倾斜,对于平台更是巨大的挑战。在过去往往通过人肉保障,杀作业修改SQL脚本重跑等方式来确保作业的及时完成,但是本质上的解决方法,还是需要系统本身,能够通过实时数据特性的统计,自适应的做出灵活的动态数据编排方案。在DAG 2.0框架上实现的Adapative Shuffle,通过探索对Shuffle数据进行自适应数据编排,能在不引入文件碎片的前提下,系统解决动态分区写入场景上的数据倾斜问题。今年的双11,也是Adaptive Shuffle在今年全面线上打开后,接受的一个重要检验。

Fig. 2(a) 数据倾斜造成运行时间的延长

Fig. 2(b) 基于Adaptive Shuffle的数据智能重排,避免数据倾斜
双11效果:DAG 2.0执行引擎对于数据倾斜的智能检测,通过Adaptive Shuffle 自动调度多计算节点来处理倾斜分区,在双11期间覆盖线上所有动态分区作业,双11高峰当天超过13万个分布式作业生效。其中在重点基线上,有效消除数据倾斜最高达到550倍,等效于将(无人工干预时)本需要运行59个小时的作业,自适应调整到在6分钟内完成。而在普通作业上,消除数据倾斜最高数千倍。有效实现了长尾的智能规避消除,保障大促期间基线作业的及时产出。

1<倾斜比<2
31%
2<倾斜比<5
5<倾斜比<10
20%
10%
11%
1%
10<倾斜比<100
8%
100<倾斜比<1000
倾斜比>1000
30%
Fig. 3 双11当天,Adaptive Shuffle生效的13万线上作业,消除倾斜程度的作业数分布
2.2 智能动态并发度调整: 分区级别自适应数据分布, 达到资源的最优使用
对于分布式作业的并发度动态调整,业界最常见的做法,是AM(application master)在获取上游输出总数据量后,直接通过“总数据量除以单个计算节点期望处理数据量”的方式来计算预期并发,并且据此缩减比例,直接合并相邻数据分区。这种简单的并发调整策略,在数据分布均匀时可能获得预期效果;但是对于线上作业,理想的均匀分布经常是不现实的,尤其是对于双11大促场景,数据的分布可能更加的不均匀。所以这种简单的调整,可能在合并数据后引入严重的数据倾斜。
另一方面,平台本身对于重点基线作业,会基于历史信息来协助执行计划生成(HBO)。但在大促期间,数据特性发生较大变化时,即便是平日较为稳定的基线作业,也可能无法根据历史信息推断合理的并发。而DAG 2.0提供的根据实时数据分布,实现分区级别的自适应并发调整,能够更准确的做出实时的判断,并且避免常见的并发调整策略可能带来的数据倾斜等副作用,做到功能的普适性。今年的双11,也是平台在这个基础上,第一次对于有HBO信息的基线作业,同样打开动态并发调整,使得其覆盖的范围大大扩展。

Input
Reduce
2
19
12
10
Naive
dynamicparallelism
29
14
13
ReduceInputafterDynamicParallelism
ReduceInput
2
5
10
12
19
Adaptive
dynamicparallelism
15
10
19
16
ReduceInputAfterDynamicParaitelism
Fig. 4 简单 vs 自适应动态并发调整策略
双11效果:MaxCompute离线作业通过DAG 2.0完善的动态图执行能力,面对数据计算量洪峰,能有针对性的进行自适应动态调整。在双11大促期间,其自适应的动态并发度调整,在超过1千万的大规模分布式作业上生效。其中11月1号小高峰,通过发动态调整节省了7.8亿个计算节点的调度;而在11月11号当晚,则节省了高达近10亿计算节点的调度。节省资源的同时,保证了计算节点处理数据分布的均匀,确保了集群资源在大促期间的有效使用。
2.3 Conditional Join: 实时Join算法的最优选择
对于传统的大数据作业,作业的执行计划由优化器在提交前确定,运行过程中无法对优化器提供的计划再进行调整。这中"一锤子买卖"的计划产生方式,对于优化器的预判能力有着非常高的要求,对线上实际作业而言,经常得不到满足。
比如对SQL作业中常见的join操作,不同的join算法各有所长,一方面Broadcast Join在性能方面具备显著优势,而SortMerge Join本身更好的通用性,能处理更多的数据join。在实际线上场景中,要求优化器要在作业执行之前,就对起中间数据大小,做出"准确的判断",从而选择最优计划,是比较困难的,出现误判的情况在所难免。导致优化器"误判"的原因很多,包括准确统计数据的缺失,数据处理逻辑以及数据特性的复杂多变等等。而在双11的大促场景上,数据特性的大幅度变化,更可能出现类似某张小表因为数据量大增而变成了一张大表的场景。这种时候如果运维/用户没有及时人工干涉的话,依然按照小表特性来做优化,而使用broadcast join执行计划,会导致运行时OOM失败,损害pipeline产出的稳定性。

Fig. 5 分布式SQL中,不同的join算法
针对这种局限,DAG 2.0执行引擎的动态逻辑图调整能力,为优化器提供了新的选择:允许其在无法事先确定最优join算法时,来提供conditional的结合了不同执行可能性的"综合计划"。在这个基础上,由执行引擎负责在作业运行过程中,收集了足够多的准确数据分布信息后,动态对执行计划进行调整和最优选择。

LogicalPlan
optimizer
cost-based
M1
(1/1)
(1/1)
(1/1)
optimization
PhysicalPian
C8_1
runtimethreshold
CE1
(00)
r00)
planthreshola
(threshold2)
(threshold1)
OR
DAGplan
qeneration
R3.1.8
M6-8
(1/1)
(50/50)
(oN1)
050)
DAG
(executionplan)
M438
J5.1.6.8
M438
J5.1.6.8
(50150)
(38/38
(0/38)
(0/60)
Job
PlanB
PlanA
submission
(SortMergeJjoin)(BroadcastJoin)
(a)plancreation
(b)o
conditionalexecution
Fig. 6 DAG 2.0上支持的conditional join实现
这种动态的选择调整,不仅支持单个join的场景,同时也支持通过作业中多个join节点,以及嵌套join的实现:
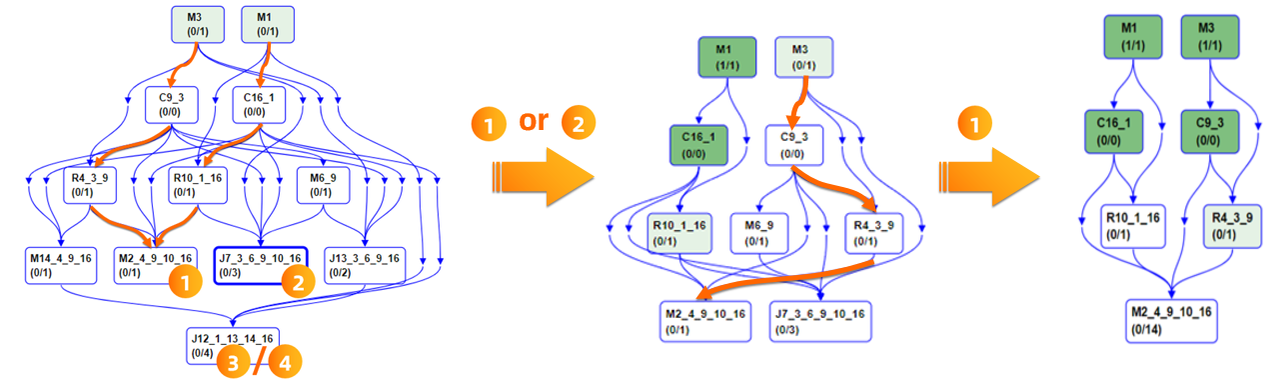
Fig. 7 嵌套conditional join在执行过程中的动态计划变化
双11效果:在双十一当天,有57万作业使用了conditional join,占全网带join操作的离线作业总数的40%。在这些conditional join作业中,均做出了正确的动态选择: 根据统计信息的指导,绝大多数(98.5%) 作业选择了适用的broadcast join算法来获取更优的性能,在这些选择broadcast join的作业中,无一发生OOM错误。相比去年,今年双11当天,全网选用broadcast join的生产作业绝对数目,几近翻倍,在join作业中的占比相对增长20%。这种基于实时信息的动态选择,使得系统能够无需因为少数不适用场景(1.5%),而放弃探索更优化的执行计划。同时对于部分数据膨胀作业,也能在避免人工运维干预的前提下,自动检测出broadcast join不再适用,采用merge join。
3. 新一代执行框架:更灵活,更高效
在DAG 2.0执行引擎的基础之上,计算平台在今年实现了对准实时执行框架的全面升级,采取了全新的资源管理与作业管理分离的架构,并支持了作业管理组件水平扩展的能力,为支持双11大促中的海量作业数目,做好了技术储备,并获得了较好的效果。同时在系统层面,执行引擎基于事件处理的核心状态机实现逻辑,今年也持续进行针对各种不同规模作业的性能调优。这些执行引擎核心性能的提升,带来的是全网每天千万以上作业性能的统一提升。
3.1 系统层面各种指标优化
在2.0全面上线和持续优化后,今年双十一期间,离线计算节点执行的overhead,相比于去年双十一降低2.8X。overhead在计算节点运行时间中的占比数倍降低。光这个调度overhead上的优化,就等同于为阿里集团节省了数千台物理机。同时准实时作业单天总量突破一千万,相比去年增长65%,准实时作业的overhead下降1.9X,亚秒级别的作业占比提升2.4X,准实时作业回退到离线模式的概率,降低2.9X。
| 准实时作业数目 | 调度计算节点总数 | |
| 2019 双11当天 | ~7百万 |
6亿+ |
| 2020 双11当天 | 1000万+ |
8亿+ |
3.2 双11高负载集群集中治理
在今年双11前期压测中,发现集团线上几个大规模集群上,由于作业数目飙升,导致准实时服务QPS被打满,大量作业回退到离线模式运行。而这些离线作业,在fuxi master并发达到上限时,同样会引发排队,导致等待时间显著延长。针对这种情况,对于这些集群,借助准实时框架2.0升级,上线了作业管理组件水平等优化,使得更多作业可以准实时模式执行,大幅提升了这些作业的性能,并降低用户排队时间。保证在集群整体资源不变的情况下,支撑双十一大数据量和大业务量的冲击。

Fig. 8 准实时执行框架2.0新架构
以集团内部某大规模集群为例,打开准实时2.0框架的作业管理横向扩展能力后,每天由于QPS超限导致回退的作业数目降为0,新准入的每天13万个准实时作业,相比之前使用离线模式时,执行性能提升10倍。同时离线作业数量降低了23%:在集群整体机器资源不变的情况下,大大缓解了集群上大量离线排队导致的压力和延迟。
此外飞天nuwa服务作为集团集群上统一分布式协调服务,承载了集群上各种作业的重要协调功能功能。DAG执行引擎通过与阿里飞天nuwa团队协作,双十一之前,重构了准实时框架调用nuwa服务的接口方式,有效的避免了在大规模服务重启时,对nuwa的峰值流量冲击和队列堆积,确保了双11期间其他分布式组件的的稳定。

准实时框架
nuwa服务峰值压力
服务升级
AMaNHILRluLYMy
AMMW
Juuylh
4dodh
16.0u
jo.Scp
18.5ep
20.Sce
4.out
24.Sce
z2.Sep
2.0c
26.Scp
12.0ct
10.0
Fig. 9 准实时执行框架升级对nuwa服务峰值压力的降低
3.3 PAI弹性批量推理引擎升级
除了对MaxCompute作业实现全面对接,DAG 2.0执行引擎的升级,也为PAI平台上Tensorflow/PyTorch作业等执行模式,提供了原生支持。这包括对作业语义的准确描述,以及在动态性,容错方面的全面提升。而在今年双11前夕,PAI团队与执行调度框架团队通力协作,推动了基于资源伸缩的弹性批量推理引擎升级,大大提升了PAI推理作业的整体性能。
在实现新的引擎升级之前,推理作业本质上还是贴着深度学习训练作业的计算模式实现,包括资源的申请使用逻辑,以及调度和failover处理等等方面。而事实上,推理作业本身的特性,与训练作业是有着较大区别,例如计算量的相对可预测性,计算的大规模化和可扩展性,计算节点运行相互独立等等。针对这些特点, 新的弹性批量推理引擎通过支持计算节点的弹性起停,利用部分超卖和超卖升级来解决GPU资源质量,以及动态数据分配等方法,对推理作业进行了大量针对性的优化。
新一代的离线弹性推理引擎,在双11前通过PAI-EVPredict打开,服务了包括搜索、阿里妈妈、淘宝、优酷、ICBU、高德、饿了么、新零售等BU。升级后,PAI-EVPredict上任务排队时长平均减小95%,任务执行时长平均减少2X以上。下图展示了其在某算法推荐团队视频特征抽取任务上的具体效果。

弹性批量推理
引擎升级
视频特征抽取
(p时[:马卖)
任务耗时
牙船少型号王
202010220003220
2020/10/172020/10/182020/10/19202010/20
2020/1021
2020/10/29
任务运行日期
Fig. 10 算法推荐团队视频特征抽取任务日任务耗时趋势变化
3.4 全新计算模式探索
在DAG 2.0执行引擎上,原有的离线模式和准实时模式通过底层灵活的分层DAG模型得以统一。同时在此统一模型上,新的计算模式的探索成为可能。FY21财年期间,新的混合Bubble执行模式的开发,使得平台上规模多种多样的作业,能够在极致性能以及高效的资源利用率之间,探索更好的平衡点。这种全新的计算模式,使得各个规模的作业,均能够在等效资源消耗上,获取进一步的性能优化。

Fig. 11 统一的DAG描述模型,使得混合Bubble执行成为可能
截至今年的双11,Bubble执行模式正在集团内部稳步推进上线的过程中。并在双11前,完成了除高级基线以外全网3200+个project的升级,覆盖了离线作业70%流量。在双11高峰当天,有近150万作业使用Bubble模式执行。对于双11之前的一星期工作日统计的归一化效果如下:

离线模式
离线模式
Bubble执行横式
Bubble执行模式
mH
0.月
0.4
FM
Wed
MOn
Wed
(a)归一化执行性能(latency)对比
(b)归一化资源消耗对比
Fig. 12 Bubble vs 离线模式的执行性能和资源消耗对比
在使用有限考虑资源使用效率的Bubble切割算法(具体Bubble切分算法可以参见Bubble执行专门的介绍)时,从实际生产作业统计来看,Bubble执行模式能在资源消耗基本不变的情况下,带来线上作业30% ~ 40%的性能提升。目前Bubble执行模式正在高级基线上稳步推进,期望在今年的双12和明年双11上取得全网作业上的性能提升。
4. 展望
DAG 2.0核心执行引擎的架构升级,旨在夯实计算平台长期发展的基础,并支持上层计算引擎与分布式调度方面结合,实现各种创新并以及新计算生态的创建。在2019双11基本完成架构本身的升级,向前迈出重要的第一步;在2020年期间,依托DAG 2.0新架构开发的多个新功能实现了落地,包括动态自适应执行能力和新计算模式的实现等等。这些新功能在刚刚过去的双11中经受住了考验。
于此同时,我们也发现大促期间,还是存在比如数据特性变化后,join操作发生较严重的skew等一系列线上一直没有系统解决的问题。执行引擎将与计算引擎团队共同合作,通过adaptive skew join的动态监测方式,推动自适应解决方案的上线。新架构的能力也会与上层计算引擎,以及系统的其他组件进行进一步的深度整合,释放架构升级红利,共同推动平台整体的向前发展。
面向分析的SaaS模式云数据仓库MaxCompute 官网 >>
欢迎加入 “MaxCompute开发者社区”钉钉群,了解更多阿里巴巴大数据技术。

