2018年9月14日笔记
阅读本文的前提是已经阅读《基于tensorflow的一元二次方程回归预测》,文章链接:https://www.jianshu.com/p/b27860402fe3
本文使用tensorboard对一元二次方程回归预测的模型训练过程做可视化展现。
0.编程环境
安装tensorflow命令:pip install tensorflow
操作系统:Win10
tensorflow版本:1.6
tensorboard版本:1.6
python版本:3.6
1.运行tensorboard
本文作者花费了4个小时才成功运行tensorboard,失败的主要原因是文件夹中带有中文。
为了避免读者踩坑,请跟随本文作者做相同操作。
在桌面新建一个文件夹tensorboardTest,如下图所示:
作者提供可以直接在tensorboard中查看的文件。
下载链接: https://pan.baidu.com/s/1uq7ElLd4z8AkTAs5t2gXxw 密码: fiqs
下载文件后在放到 不含有中文的文件夹中,并在此文件夹下打开cmd,如下图所示:
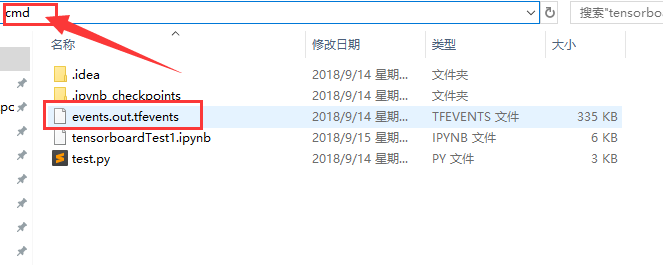
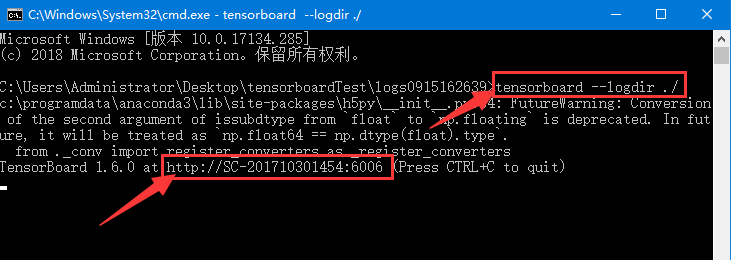
在cmd中输入命令并运行:
tensorboard --logdir ./
成功运行的结果如下图所示:
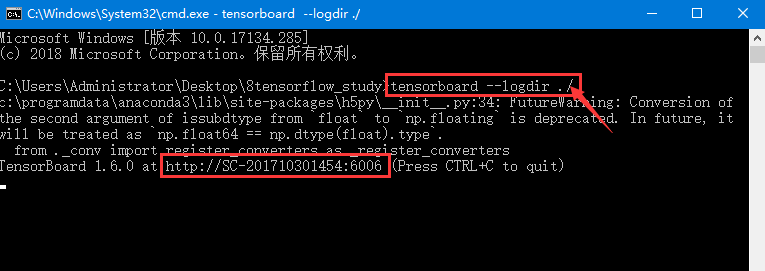
开启tensorboard服务后,可以在浏览器访问网址:
localhost:6006或者
上图中红色方框内的链接
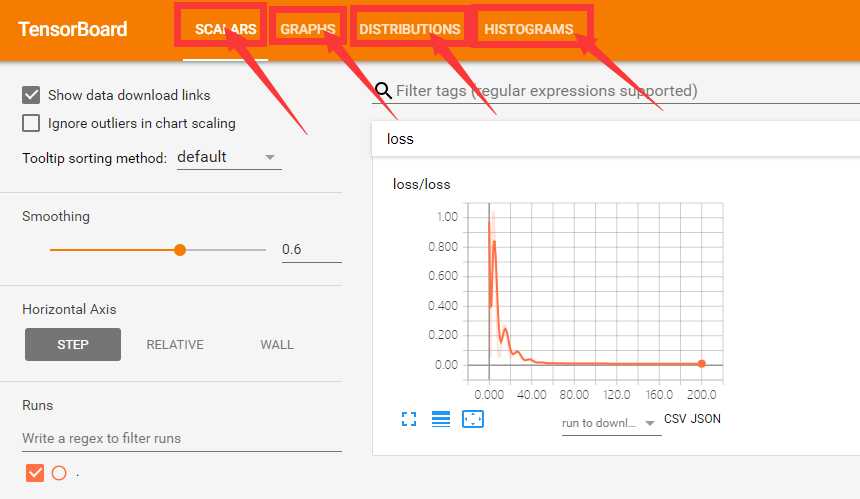
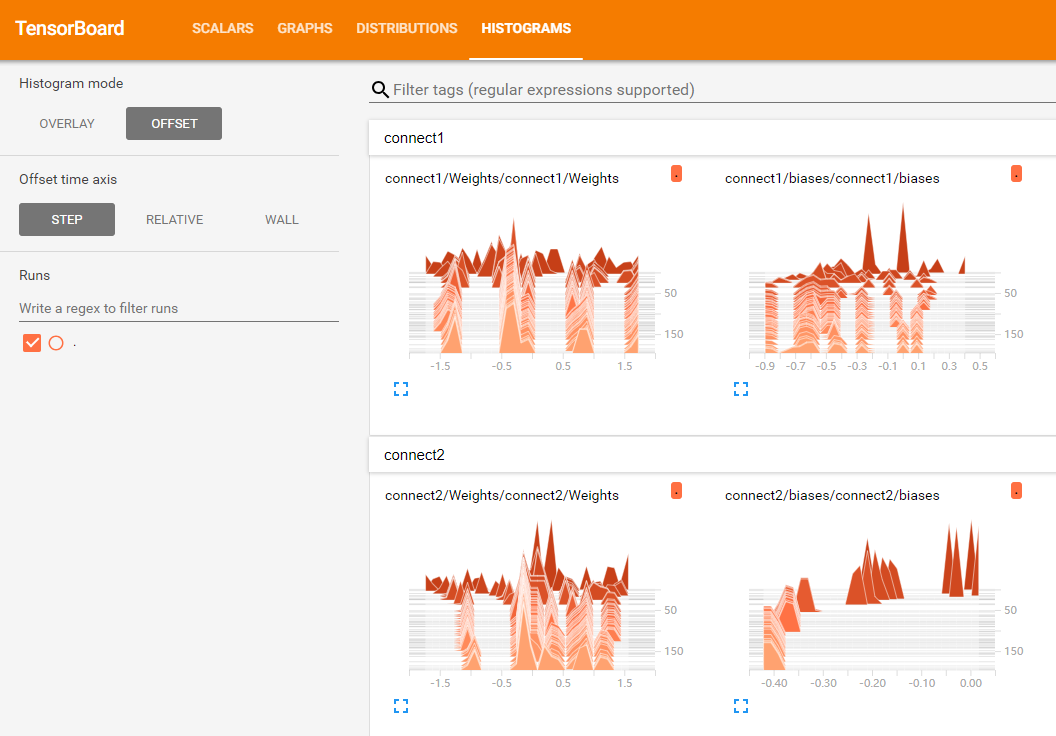
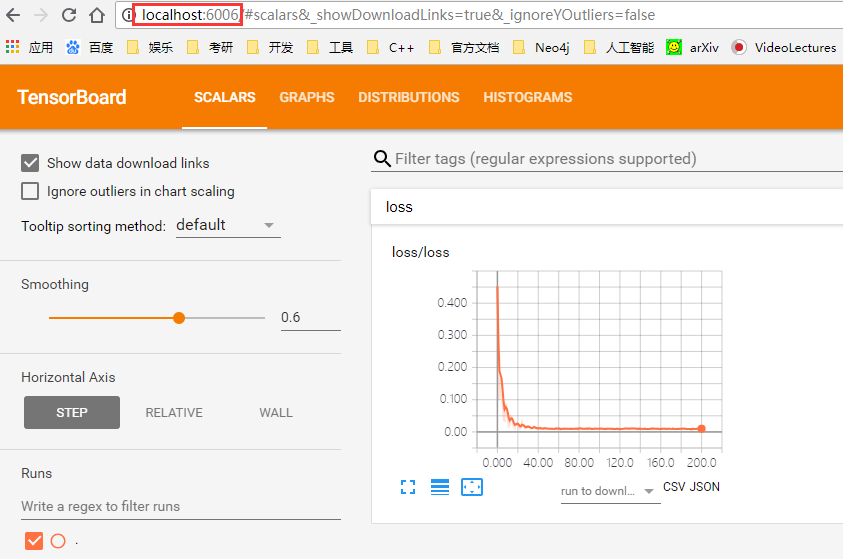
下图的4个红色箭头标注表示通过代码做出了4张图,第1张图是loss的变化曲线图;
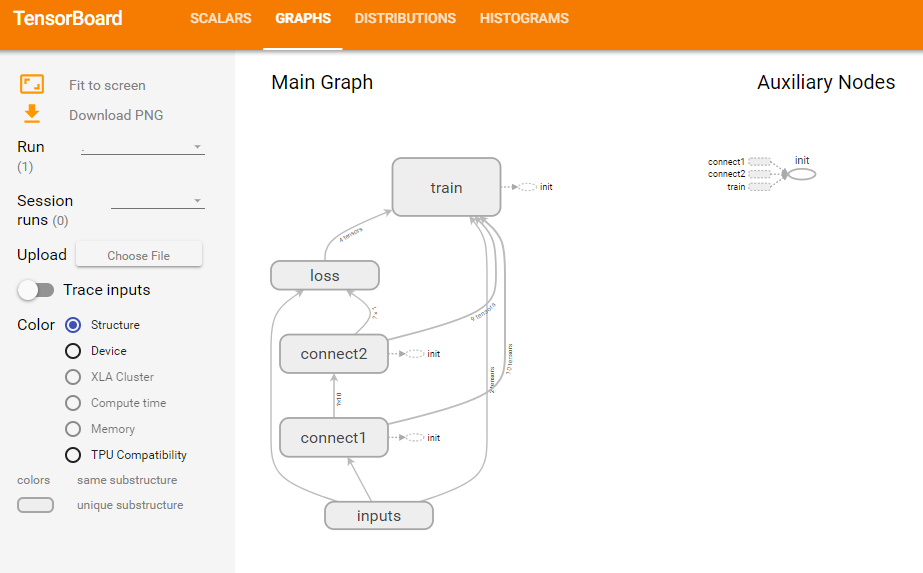
第2张图是神经网络架构图;
第3张图是权重Weights和偏置biases的变化曲线图;
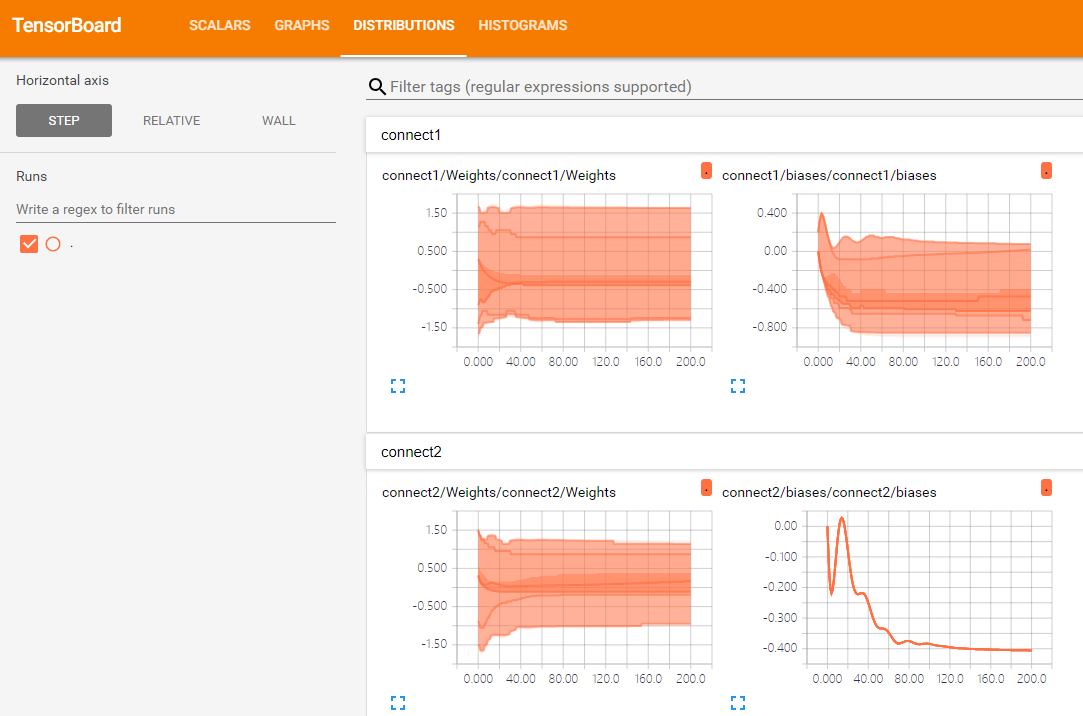
第4张图是权重Weights和偏置biases的分布直方图。
2.打开jupyter
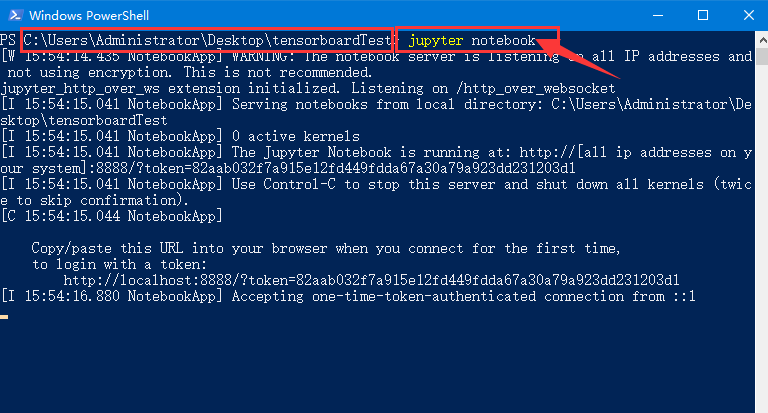
下图中左边红色方框指的是要在文件夹tensorboardTest打开PowerShell或者cmd。
在PowerShell或者cmd中输入命令并运行:jupyter notebook
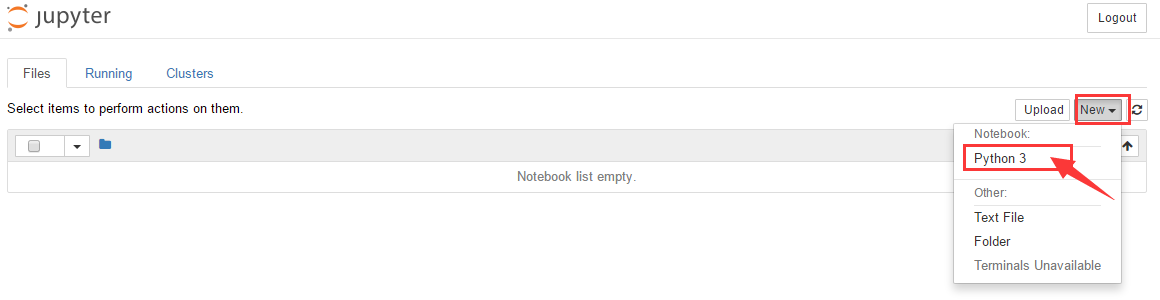
运行命令后会自动打开浏览器,界面如下图所示,点击下图红色箭头标注处新建代码文件。
点击下图红色箭头标注处修改代码文件名为
tensorboardTest1。
3.检测tensorflow环境
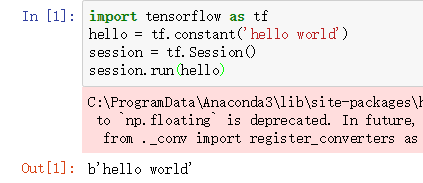
如果下面一段代码运行成功,则说明安装tensorflow环境成功。
import tensorflow as tf
hello = tf.constant('hello world')
session = tf.Session()
session.run(hello)
上面一段代码成功运行的结果如下图所示:
4.数据准备
import tensorflow as tf
import numpy as np
batch_size = 100
X_data = np.linspace(-1, 1, 300).reshape(-1, 1).astype('float32')
noise = np.random.normal(0, 0.1, X_data.shape).astype('float32')
y_data = np.square(X_data) - 0.5 + noise
with tf.name_scope('inputs'):
X_holder = tf.placeholder(tf.float32, name='input_X')
y_holder = tf.placeholder(tf.float32, name='input_y')
第1行代码导入numpy库,起别名np;
第2行代码导入tensorflow库,起别名tf;
第4行代码定义投入训练的样本数量batch_size。
第5行代码调用np.linspace方法获得一个区间内的等间距点,例如np.linspace(0, 1, 11)是获取[0, 1]区间的11个等间距点。如下图所示:

第6行代码调用np.random.normal方法初始化符合正态分布的点,第1个参数是正态分布的均值,第2个参数是正态分布的方差,第3个参数是返回值的shape,返回值的数据类型为ndarray对象。
第7行代码调用np.square方法对X中的每一个值求平方,
- 0.5使用了ndarray对象的广播特性,最后加上噪声noise,将计算结果赋值给变量y。
第8行代码中scope中文叫做 适用范围,每定义一个tf.name_scope,在tensorboard界面的graph中会有一个节点。
第9、10行代码中placeholder中文叫做 占位符,tf.placeholder方法的第1个参数是tensorflow中的数据类型;第2个关键字参数name的数据类型是字符串,是在tensorboard界面中的显示名。
5.搭建神经网络
定义addConnect函数,作用是添加1层连接。
因为该神经网络总共有3层:输入层、隐层、输出层,所以需要调用2次addConnect函数添加2层连接。
addConnect函数第1个参数是输入矩阵,第2个参数是输入矩阵的列数,第3个参数是输出矩阵的列数,第4个参数用来定义是第几层连接,第5个参数是激活函数。
最后6行代码定义损失函数、优化器、训练过程。
def addConnect(inputs, in_size, out_size, n_connect, activation_function=None):
connect_name = 'connect%s' %n_connect
with tf.name_scope(connect_name):
with tf.name_scope('Weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]) ,name='W')
tf.summary.histogram(connect_name + '/Weights', Weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
tf.summary.histogram(connect_name + '/biases', biases)
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
return Wx_plus_b
else:
return activation_function(Wx_plus_b)
connect_1 = addConnect(X_holder, 1, 10, 1, tf.nn.relu)
predict_y = addConnect(connect_1, 10, 1, 2)
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y_holder - predict_y))
tf.summary.scalar('loss', loss)
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(0.1)
train = optimizer.minimize(loss)
6.变量初始化
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
对于神经网络模型,重要是其中的W、b这两个参数。
开始神经网络模型训练之前,这两个变量需要初始化。
第1行代码调用tf.global_variables_initializer实例化tensorflow中的Operation对象。
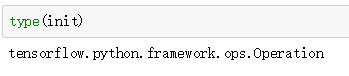
第2行代码调用tf.Session方法实例化会话对象;
第3行代码调用tf.Session对象的run方法做变量初始化。
7.模型训练
import datetime
import random
nowTime = datetime.datetime.now()
timestamp = nowTime.strftime('%m%d%H%M%S')
write = tf.summary.FileWriter('logs'+timestamp, session.graph)
merge_all = tf.summary.merge_all()
for i in range(201):
select_index = random.sample(range(len(X_data)), k=batch_size)
select_X = X_data[select_index]
select_y = y_data[select_index]
session.run(train, feed_dict={X_holder:select_X, y_holder:select_y})
merged = session.run(merge_all, feed_dict={X_holder:select_X, y_holder:select_y})
write.add_summary(merged, i)
第1行代码导入datetime库获取当前时间,从而给文件夹命名;
第2行代码导入random库,第10行代码使用random.sample方法选取数量为batch_size的样本来训练;
第4、 5、 6行代码给新建的日志文件夹命名;
第7行代码将绘制标量曲线图SCALARS、变量曲线图DISTRIBUTIONS、变量分布直方图HISTOGRAMS的任务合并交给变量merge_all;
在200次训练迭代中,第10、11、12行代码选取数量为batch_size的样本来训练;
第13行代码每运行1次,即神经网络训练1次;
第14行代码获得每次训练后loss、Weights、biases值;
第15行代码把loss、Weights、biases值写入日志文件中。
8.完整代码和查看结果
import tensorflow as tf
import numpy as np
import datetime
import random
batch_size = 100
X_data = np.linspace(-1, 1, 300).reshape(-1, 1).astype('float32')
noise = np.random.normal(0, 0.1, X_data.shape).astype('float32')
y_data = np.square(X_data) - 0.5 + noise
with tf.name_scope('inputs'):
X_holder = tf.placeholder(tf.float32, name='input_X')
y_holder = tf.placeholder(tf.float32, name='input_y')
def addConnect(inputs, in_size, out_size, n_connect, activation_function=None):
connect_name = 'connect%s' %n_connect
with tf.name_scope(connect_name):
with tf.name_scope('Weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]) ,name='W')
tf.summary.histogram(connect_name + '/Weights', Weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
tf.summary.histogram(connect_name + '/biases', biases)
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
return Wx_plus_b
else:
return activation_function(Wx_plus_b)
connect_1 = addConnect(X_holder, 1, 10, 1, tf.nn.relu)
predict_y = addConnect(connect_1, 10, 1, 2)
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y_holder - predict_y))
tf.summary.scalar('loss', loss)
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(0.1)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
nowTime = datetime.datetime.now()
timestamp = nowTime.strftime('%m%d%H%M%S')
write = tf.summary.FileWriter('logs'+timestamp, session.graph)
merge_all = tf.summary.merge_all()
for i in range(201):
select_index = random.sample(range(len(X_data)), k=batch_size)
select_X = X_data[select_index]
select_y = y_data[select_index]
session.run(train, feed_dict={X_holder:select_X, y_holder:select_y})
merged = session.run(merge_all, feed_dict={X_holder:select_X, y_holder:select_y})
write.add_summary(merged, i)
代码成功运行会在同级文件夹中产生日志文件夹,如下图所示。
根据代码运行时间对文件夹命名,所以读者的文件夹名与下图不同。
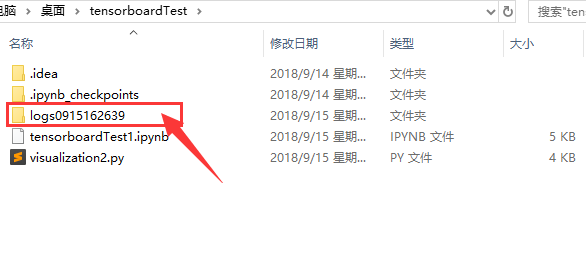
点击进入此文件夹,在此文件夹在打开cmd,如下图所示:
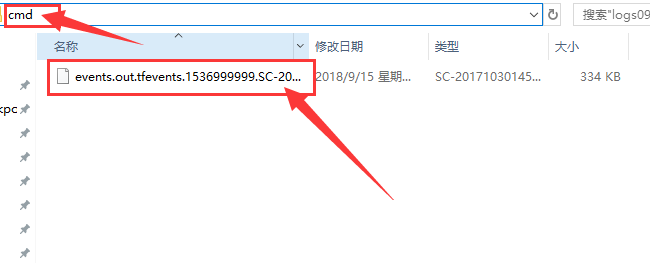
在cmd中输入命令并运行:
tensorboard --logdir ./
开启tensorboard服务后,可以在浏览器访问网址:localhost:6006
浏览器中的界面如下图所示,则说明操作都是成功的。
9.结合matplotlib可视化、tensorboard日志
visualization2代码文件下载链接: https://pan.baidu.com/s/1KkCMOAVrWOkg1SfDaySFoA 密码: ud3z
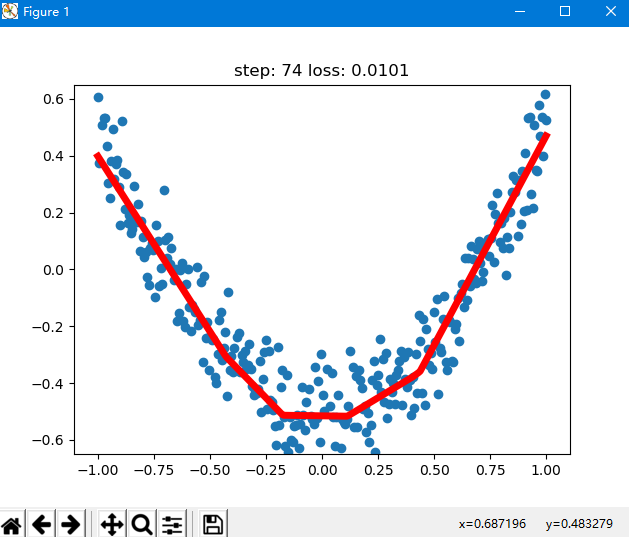
在代码文件同级目录下打开cmd,输入命令并运行:python visualization2.py
运行结果部分截图如下:
10.结论
1.这是本文作者写的第3篇关于tensorflow的文章,加深了对tensorflow框架的理解;
2.本文是作者学习《周莫烦tensorflow视频教程》的成果,感激前辈;
3.因为tensorboard版本原因,原视频的代码需要修改,自己复现代码花费了10多个小时;
4.通过指定batch_size,加深了对tf.Session对象的run方法中的feed_dict参数的理解。