基于欧式距离的分割和基于区域生长的分割本质上都是用区分邻里关系远近来完成的。由于点云数据提供了更高维度的数据,故有很多信息可以提取获得。欧几里得算法使用邻居之间距离作为判定标准,而区域生长算法则利用了法线,曲率,颜色等信息来判断点云是否应该聚成一类。
(1)欧几里德算法
具体的实现方法大致是:
- 找到空间中某点p10,有kdTree找到离他最近的n个点,判断这n个点到p的距离。将距离小于阈值r的点p12,p13,p14....放在类Q里
- 在 Q\p10 里找到一点p12,重复1
- 在 Q\p10,p12 找到一点,重复1,找到p22,p23,p24....全部放进Q里
- 当 Q 再也不能有新点加入了,则完成搜索了
因为点云总是连成片的,很少有什么东西会浮在空中来区分。但是如果结合此算法可以应用很多东东。比如
- 半径滤波删除离群点
- 采样一致找到桌面或者除去滤波
当然,一旦桌面被剔除,桌上的物体就自然成了一个个的浮空点云团。就能够直接用欧几里德算法进行分割了,这样就可以提取出我们想要识别的东西
在这里我们就可以使用提取平面,利用聚类的方法平面去掉再显示剩下的所有聚类的结果,在这里也就是有关注我的微信公众号的小伙伴向我请教,说虽然都把平面和各种非平面提取出来了,但是怎么把非平面的聚类对象可视化出来呢?
哈哈,刚开始我也以为没有例程实现这样的可视化,也许比较难吧,但是仔细一想,提取出来的聚类的对象都是单独的显示在相对与源文件不变的位置所以我们直接相加就应该可以实现阿~所以废话没多说我就直接写程序,的确可视化的结果就是我想要的结果
那么我们看一下我的代码吧
#include <pcl/ModelCoefficients.h> #include <pcl/point_types.h> #include <pcl/io/pcd_io.h> #include <pcl/filters/extract_indices.h> #include <pcl/filters/voxel_grid.h> #include <pcl/features/normal_3d.h> #include <pcl/kdtree/kdtree.h> #include <pcl/sample_consensus/method_types.h> #include <pcl/sample_consensus/model_types.h> #include <pcl/segmentation/sac_segmentation.h> #include <pcl/segmentation/extract_clusters.h> /****************************************************************************** 打开点云数据,并对点云进行滤波重采样预处理,然后采用平面分割模型对点云进行分割处理 提取出点云中所有在平面上的点集,并将其存盘 ******************************************************************************/ int main (int argc, char** argv) { // 读取文件 pcl::PCDReader reader; pcl::PointCloud<pcl::PointXYZ>::Ptr add_cloud(new pcl::PointCloud<pcl::PointXYZ>); pcl::PointCloud<pcl::PointXYZ>::Ptr cloud (new pcl::PointCloud<pcl::PointXYZ>), cloud_f (new pcl::PointCloud<pcl::PointXYZ>); reader.read ("table_scene_lms400.pcd", *cloud); std::cout << "PointCloud before filtering has: " << cloud->points.size () << " data points." << std::endl; //* // 下采样,体素叶子大小为0.01 pcl::VoxelGrid<pcl::PointXYZ> vg; pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_filtered (new pcl::PointCloud<pcl::PointXYZ>); vg.setInputCloud (cloud); vg.setLeafSize (0.01f, 0.01f, 0.01f); vg.filter (*cloud_filtered); std::cout << "PointCloud after filtering has: " << cloud_filtered->points.size () << " data points." << std::endl; //* //创建平面模型分割的对象并设置参数 pcl::SACSegmentation<pcl::PointXYZ> seg; pcl::PointIndices::Ptr inliers (new pcl::PointIndices); //设置聚类的内点索引 pcl::ModelCoefficients::Ptr coefficients (new pcl::ModelCoefficients);//平面模型的因子 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_plane (new pcl::PointCloud<pcl::PointXYZ> ()); pcl::PCDWriter writer; seg.setOptimizeCoefficients (true); seg.setModelType (pcl::SACMODEL_PLANE); //分割模型 seg.setMethodType (pcl::SAC_RANSAC); //随机参数估计方法 seg.setMaxIterations (100); //最大的迭代的次数 seg.setDistanceThreshold (0.02); //设置阀值 int i=0, nr_points = (int) cloud_filtered->points.size ();//剩余点云的数量 while (cloud_filtered->points.size () > 0.3 * nr_points) { // 从剩余点云中再分割出最大的平面分量 (因为我们要处理的点云的数据是两个平面的存在的) seg.setInputCloud (cloud_filtered); seg.segment (*inliers, *coefficients); if (inliers->indices.size () == 0) //如果内点的数量已经等于0,就说明没有 { std::cout << "Could not estimate a planar model for the given dataset." << std::endl; break; } // 从输入的点云中提取平面模型的内点 pcl::ExtractIndices<pcl::PointXYZ> extract; extract.setInputCloud (cloud_filtered); extract.setIndices (inliers); //提取内点的索引并存储在其中 extract.setNegative (false); // 得到与平面表面相关联的点云数据 extract.filter (*cloud_plane); std::cout << "PointCloud representing the planar component: " << cloud_plane->points.size () << " data points." << std::endl; // // 移去平面局内点,提取剩余点云 extract.setNegative (true); extract.filter (*cloud_f); *cloud_filtered = *cloud_f; } // 创建用于提取搜索方法的kdtree树对象 pcl::search::KdTree<pcl::PointXYZ>::Ptr tree (new pcl::search::KdTree<pcl::PointXYZ>); tree->setInputCloud (cloud_filtered); std::vector<pcl::PointIndices> cluster_indices; pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec; //欧式聚类对象 ec.setClusterTolerance (0.02); // 设置近邻搜索的搜索半径为2cm ec.setMinClusterSize (100); //设置一个聚类需要的最少的点数目为100 ec.setMaxClusterSize (25000); //设置一个聚类需要的最大点数目为25000 ec.setSearchMethod (tree); //设置点云的搜索机制 ec.setInputCloud (cloud_filtered); ec.extract (cluster_indices); //从点云中提取聚类,并将点云索引保存在cluster_indices中 //迭代访问点云索引cluster_indices,直到分割处所有聚类 int j = 0; for (std::vector<pcl::PointIndices>::const_iterator it = cluster_indices.begin (); it != cluster_indices.end (); ++it) { //迭代容器中的点云的索引,并且分开保存索引的点云 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_cluster (new pcl::PointCloud<pcl::PointXYZ>); for (std::vector<int>::const_iterator pit = it->indices.begin (); pit != it->indices.end (); ++pit) //设置保存点云的属性问题 cloud_cluster->points.push_back (cloud_filtered->points[*pit]); //* cloud_cluster->width = cloud_cluster->points.size (); cloud_cluster->height = 1; cloud_cluster->is_dense = true; std::cout << "PointCloud representing the Cluster: " << cloud_cluster->points.size () << " data points." << std::endl; std::stringstream ss; ss << "cloud_cluster_" << j << ".pcd"; writer.write<pcl::PointXYZ> (ss.str (), *cloud_cluster, false); //* //————————————以上就是实现所有的聚类的步骤,并且保存了————————————————————————————// //以下就是我为了回答网友提问解决可视化除了平面以后的可视化的代码也就两行 j++; *add_cloud+=*cloud_cluster; pcl::io::savePCDFileASCII("add_cloud.pcd",*add_cloud); } return (0); }
编译生成可执行文件后结果如下
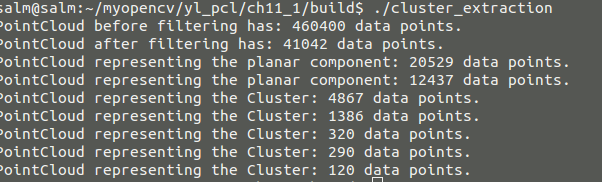
那么我们查看以下源文件可视化的结果

再可视化我们聚类后除了平面的可视化的结果,从中可以看出效果还是很明显的。

当然总结一下,我们在实际应用的过程中可能没那么轻松,因为我们要根据实际的点云的大小来设置相关的参数,如果参数错误就不太能实现现在的效果。
所以对实际应用中参数的设置是需要经验的吧,下一期会介绍其他的分割方法
有兴趣这关注微信公众号,加入我们与更多的人交流,同时也欢迎更多的来自网友的分享