
数加大数据直播系列课程,主要以基于阿里云数加MaxCompute的企业大数据仓库架构建设思路为主题,分享阿里巴巴的大数据是怎么演变以及怎样利用大数据技术构建企业级大数据平台。
本次分享嘉宾是来自阿里云大数据的技术专家祎休!
背景与总体思路
数据仓库是一个面向主题的、集成的、非易失的、反映历史变化的数据集合,用于支持管理决策。其结构图如下所示:
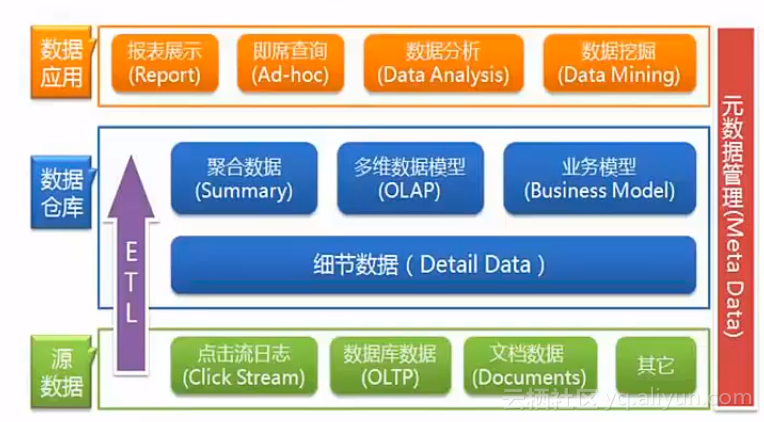
随着大数据、云计算等技术的应用和普及,互联网环境下数据处理呈现出新的特征:业务变化快;数据来源多;系统耦合多;应用深度深。业务变化加快导致数据来源增多,以前的数据大多来自于应用系统数据库,基本为结构化数据,比如Oracle、MySQL等数据。现在的互联网环境下有了更多的数据,比如网站的点击日志、视频数据、语音数据,这些数据都需要通过统一的计算来反映企业的经营状况。在互联网环境下,系统耦合也相对比较多,最重要的是要注重如何在这样的环境下加深数据整合、提升应用深度。从应用深度上来说,之前更多专注于报表分析,在大数据环境下则更多地进行算法分析,通过建立数据模型去预测和研判未来趋势。所以在这种境况下,对于系统的需求也更高:
要求结果数据尽可能快的获取;
实时性需求增多;
访问、获取途径多样便捷;
安全要求高。
在高需求下,传统仓库必然面临着挑战:数据量增长过快导致运行效率下降;数据集成代价大;无法处理多样性的数据;数据挖掘等深度分析能力欠缺。基于这些特征,用户该如何构建大数据仓库?在阿里云的数据仓库构建过程中,总结出了以下四个衡量标准:
稳定——数据产出稳定并有保障,维护系统的稳定性;
可信——数据干净,数据质量足够高,带来更高效的应用服务;
丰富——数据涵盖的业务面足够广泛;
透明——数据的构成体系要足够透明,使得用户放心。
一个完备的大数据仓库应该具备海量的数据存储及处理能力、多样的编程接口和计算框架、丰富的数据采集通道、多种安全防护措施及监控等特征,所以在架构构建时需要遵循一定的设计准则:
自上而下+自下而上地设计,数据驱动和应用驱动整合;
在技术选型上注重高容错性,保证系统稳定;
数据质量监控贯穿整个数据处理流程;
不怕数据冗余,充分利用存储交换易用,减少复杂度和计算量。
架构及模型设计
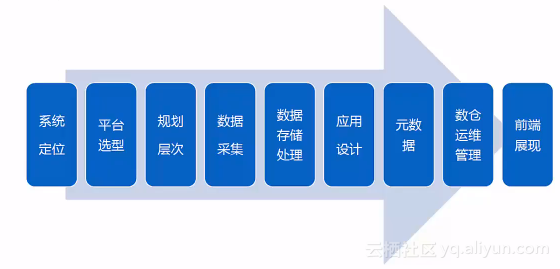
一般来说,数据仓库的构建需要经历以上几个过程。好的架构设计,在功能架构、数据架构、技术架构上,都能够很好满足需求:
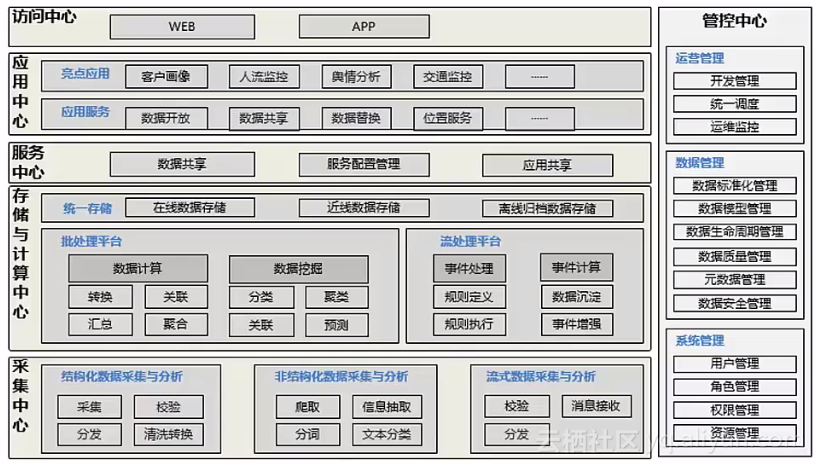
功能架构示例:结构层次清晰
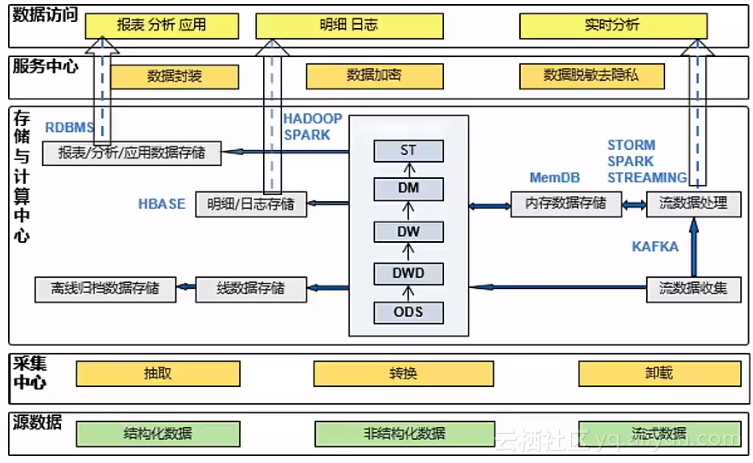
数据架构示例:注重数据流向,数据质量有保障
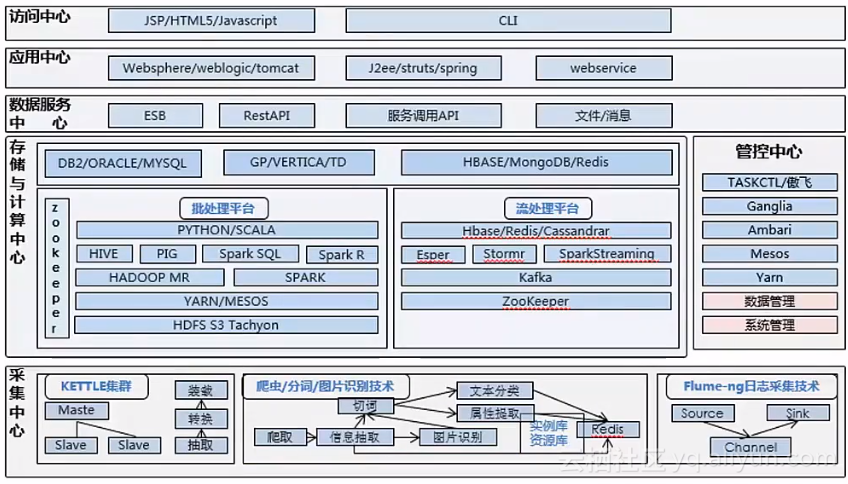
技术架构示例:易扩展、易用
构建数仓的首要任务就是模型设计,业界一般采用的建模方法有两种:
维度建模:结构简单;便于事实数据分析;适合业务分析报表和BI。
实体建模:结构复杂;便于主题数据打通;适合复杂数据内容的深度挖掘。
用户可以根据实际情况进行区分,而在实际数据仓库中,星型模型和雪花模型是并存的,有利于数据应用和减少计算资源消耗。
在数据处理分层上,一般采用较多的是上下三层结构:

这样设计是为了压缩整体数据处理流程的长度,扁平化的数据处理流程有助于数据质量控制和数据运维;把流式处理作为数据体系的一部分,能够更加关注数据的时效性,使得数据价值更高。
基础数据层

数据中间层

围绕实体打通行为,能将数据源进行整合;从行为抽象关系,则是未来上层应用一个很重要的数据依赖。此外,冗余是个好手段,能够保证主题的完整性,提高数据易用性。
数据集市层

需求场景驱动的集市层建设,各集市之间是垂直构建的,需要能够快速试错,深度挖掘数据价值。
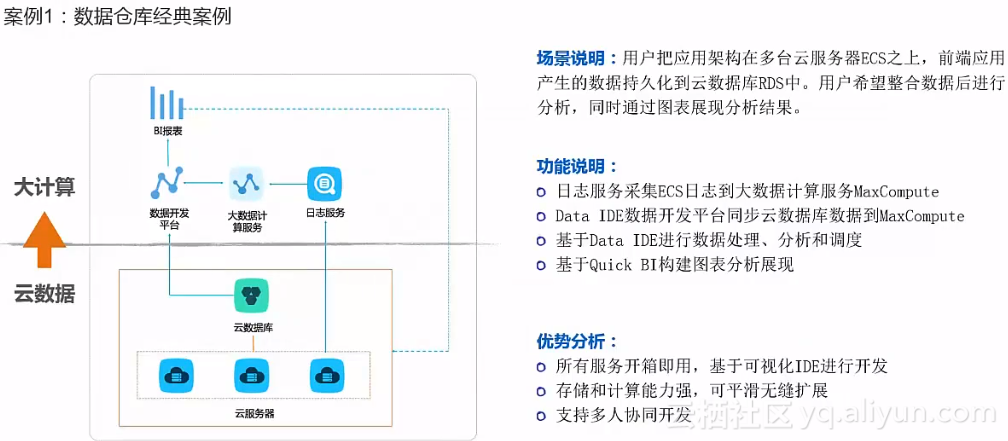
基于阿里云数加搭建大数据仓库
基于阿里云数加搭建大数据仓库的整个业务流程如下所示:
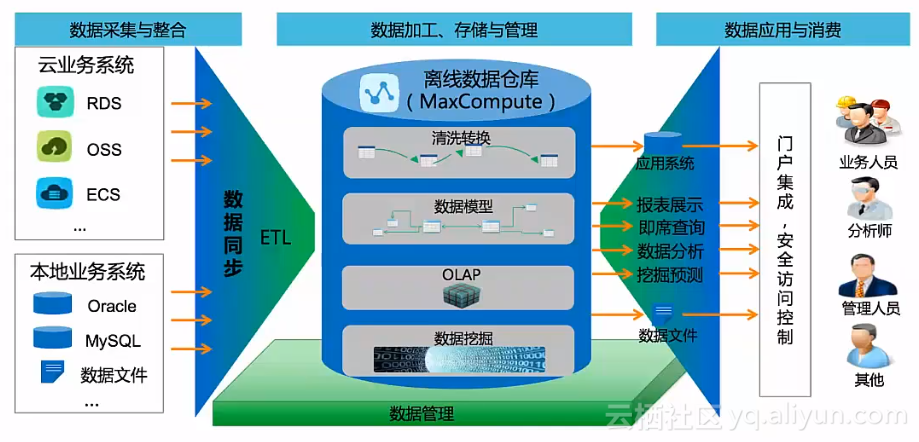
阿里云的数加架构主要分为数据整合、数据体系、数据应用三个层次,如下图:
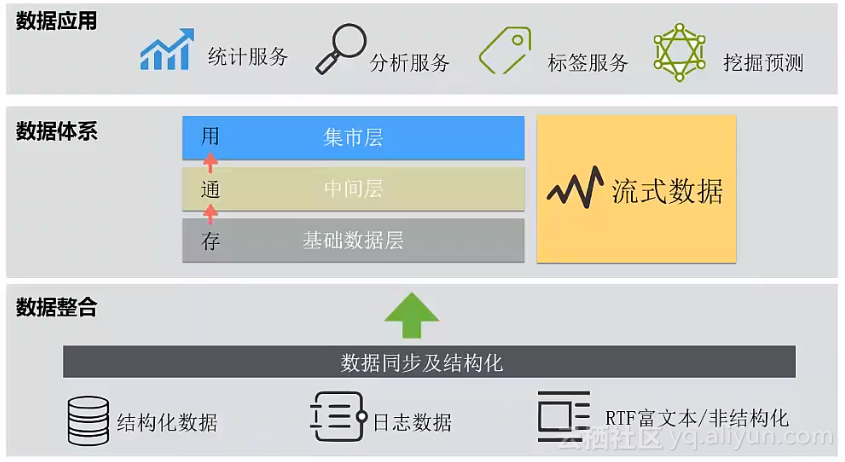
结构化数据采集通常涉及到全量采集和增量采集。全量采集是整个数仓的数据初始化,将历史数据快速地同步到计算平台;增量采集是初始化之后的数据同步。但在数据量巨大、增量数据同步资源消耗严重,或者后续的数据应用需要用到准实时数据的情况下,还会采用实时采集的方法,这种方法对采集端系统有一定的要求,而且采集质量最难控制。
事实上,日志原始结构越规范,解析的成本越低。在日志采集到平台之前,建议尽量不做结构化,后续再通过UDF或MR计算框架实现日志结构化。
数据仓库与阿里云数加产品的对应关系
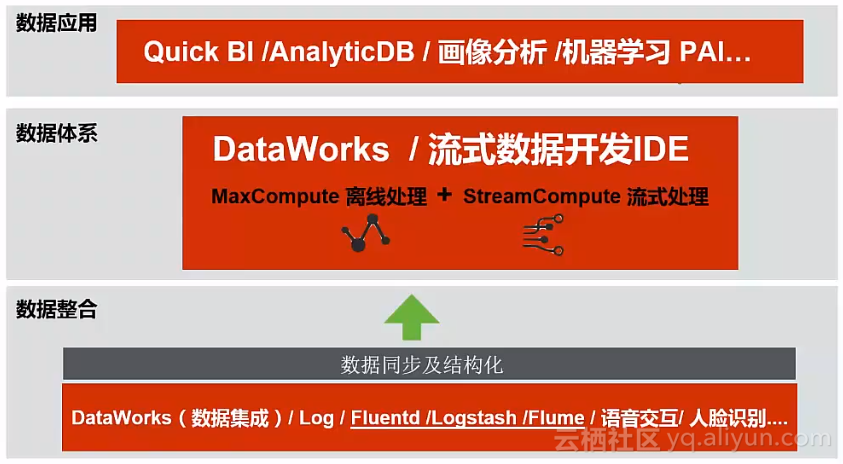
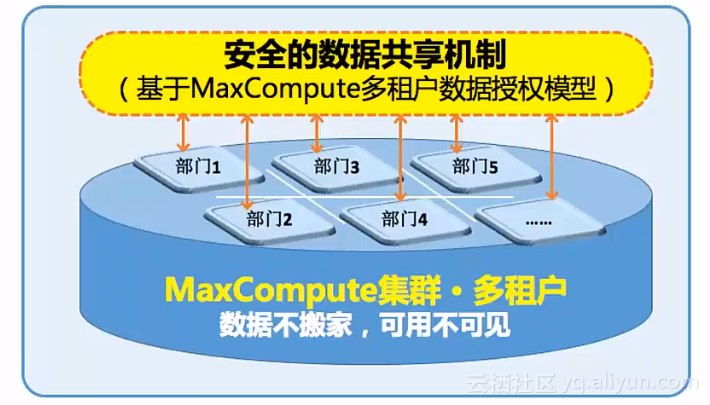
离线数仓:MaxCompute数据共享的安全性
数仓的安全性是最为重要的话题。基于MaxCompute的多租户数据授权模型,是安全性非常之高的数据共享机制,在数据流、访问限制等方面能够有效防治。
架构设计中的一些最佳实践

数据表命名规范
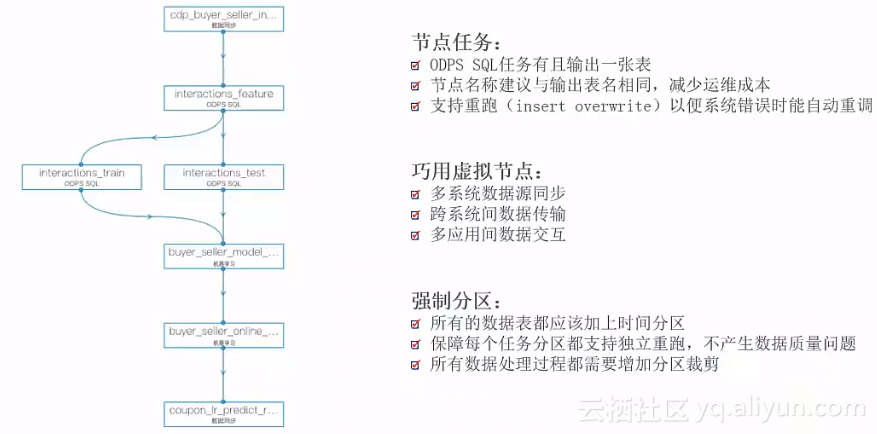
分区表、工作流设计
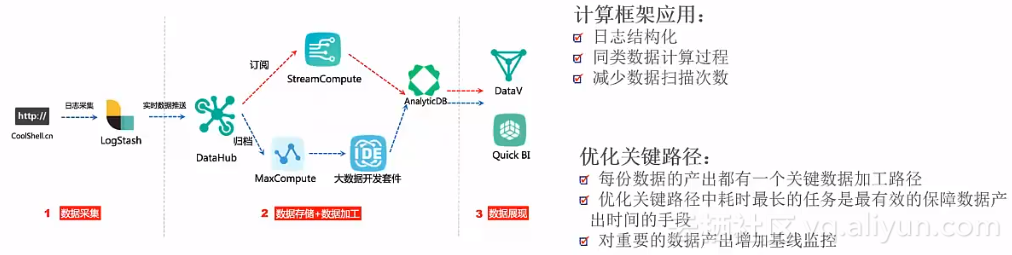
计算框架应用、优化关键路径
实际开发中的一些友好案例
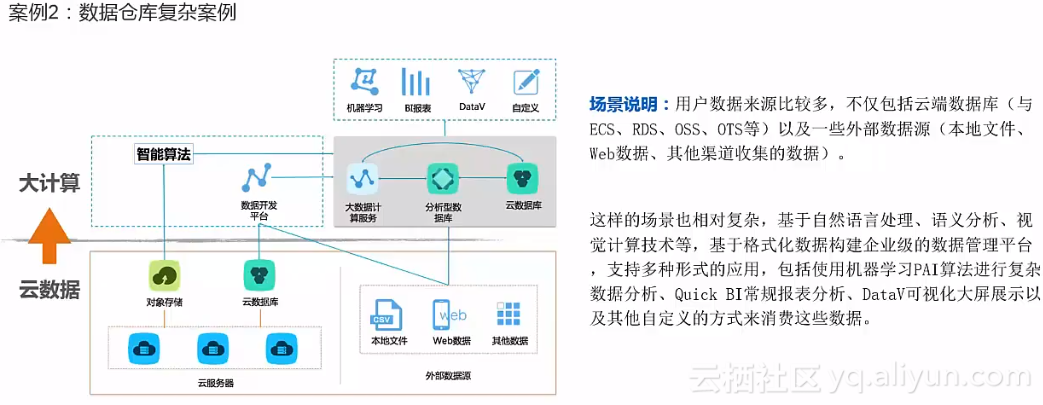
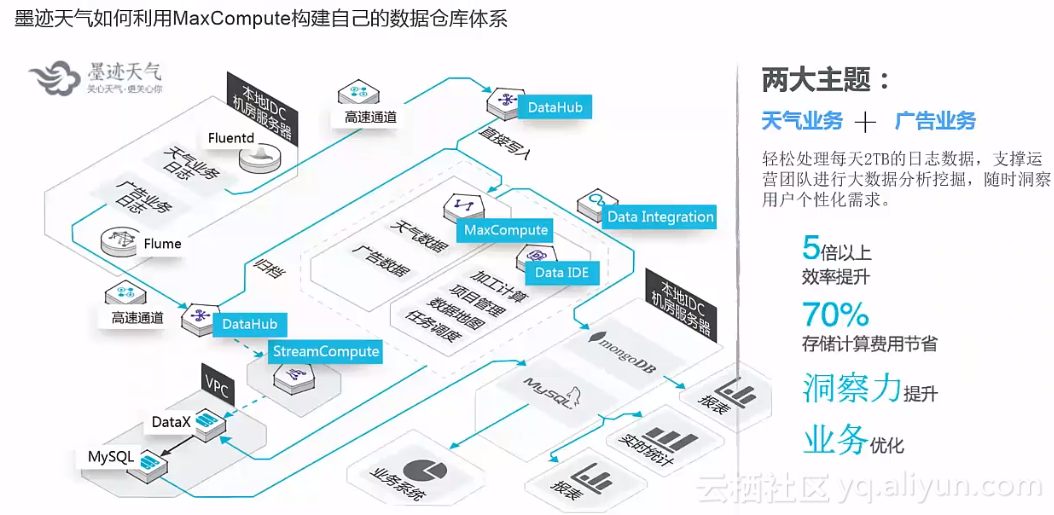
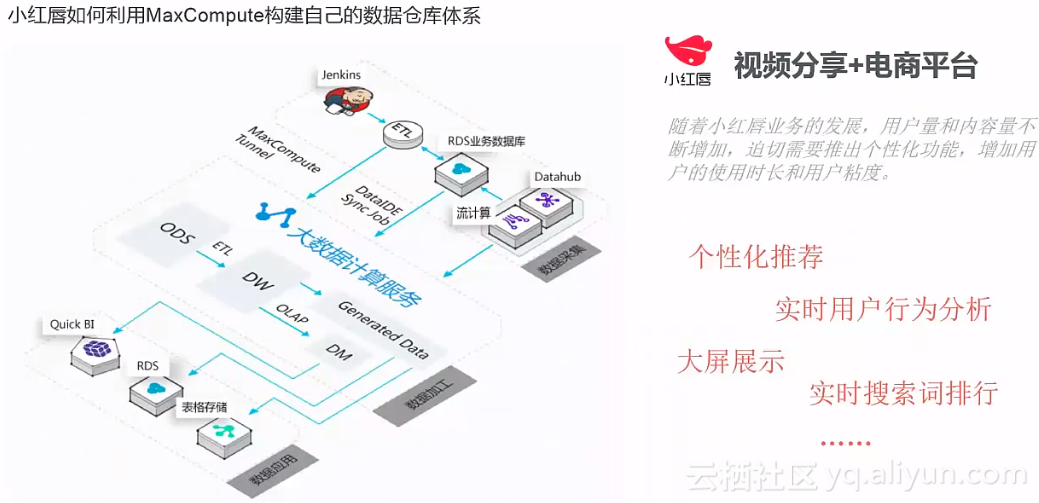
用大数据治理大数据
数据治理分为保障机制、管理、内容建设几个方面,并且贯穿数据开发的整个过程:
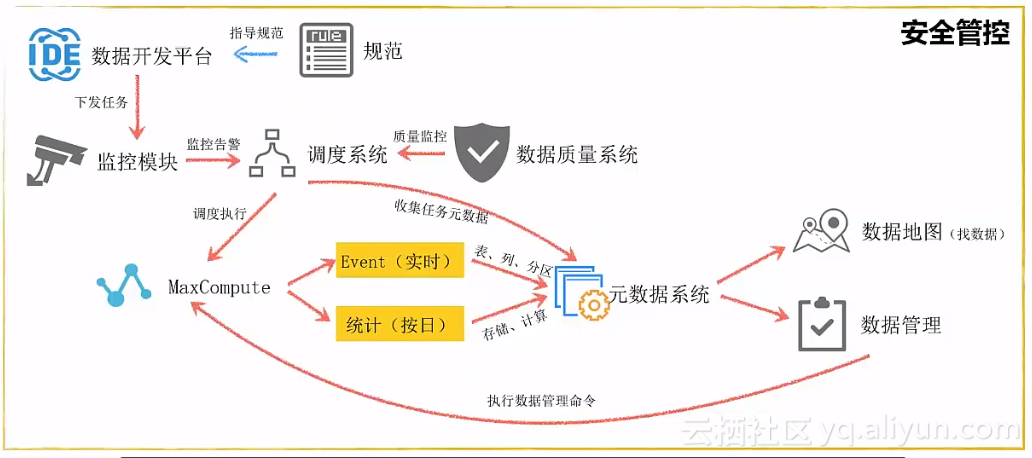
为了有效衡量数据治理的效果,阿里云使用的数据管理健康评估体系能够正确认识数据管理的健康性,给出数据管理健康分。
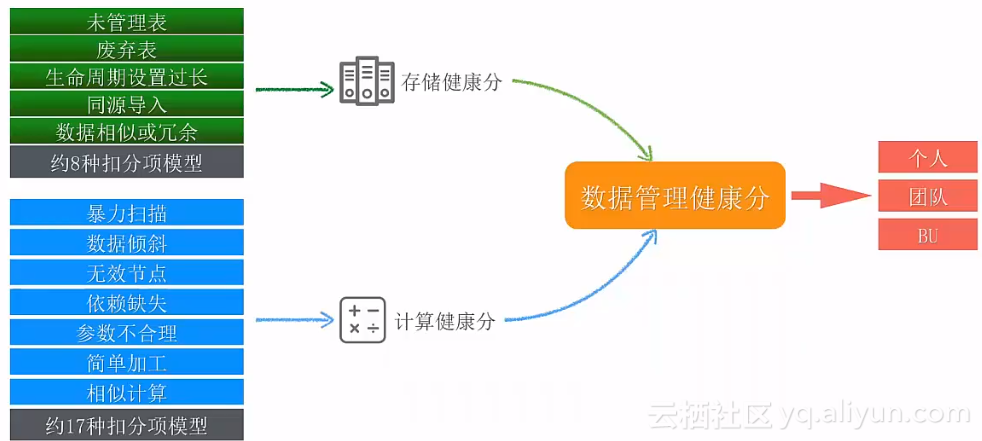
在数据治理过程中,比较重要的一点是重复数据治理。重复数据治理有多种表现:
相同源头:重复拖取同一张表;
计算相似:读取表相同且处理特征相似;
简单加工:简单转换、裁剪后保存至新表;
同表同分区:数据保持不更新或业务已停止;
空跑表:运算结果数据持续为空;
命名相似:表名或字段名相似度较高;
特殊规则:通过已知业务规则识别。
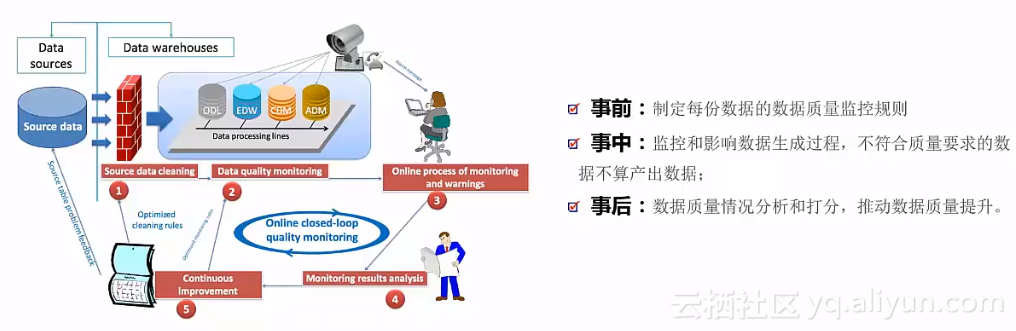
数据质量管理体系
数据生命周期管理

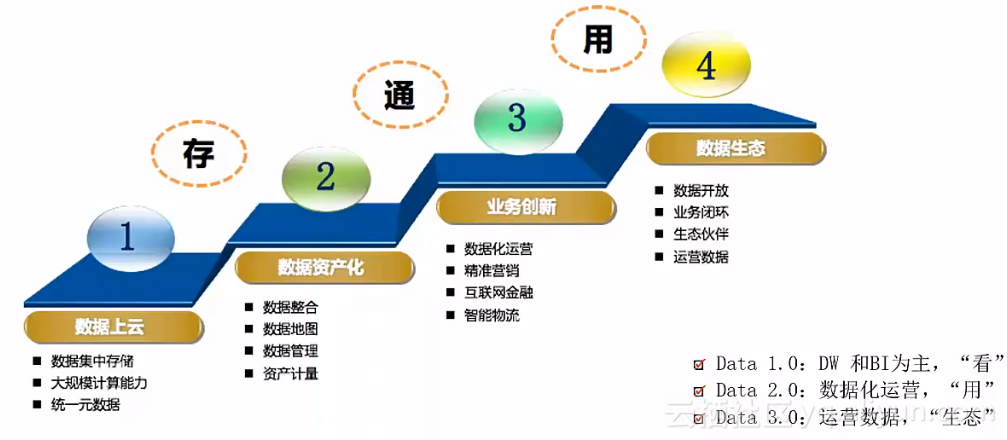
总结:阿里大数据实践之路
阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……


