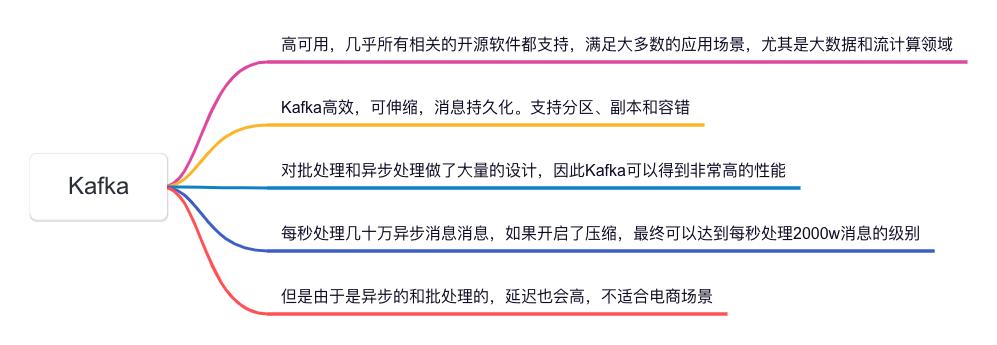
哈喽,大家好,我是小米,一个积极活泼、热爱技术分享的大哥哥!今天我们来聊聊在大数据和流计算领域备受推崇的消息系统——Kafka。Kafka以其高效、可伸缩、消息持久化的特性成为了许多企业的首选,特别是在需要处理大量数据和流数据的应用场景中。本文将深入探讨Kafka的高可用性,并分析其在批处理和异步处理方面的卓越设计。
Kafka的高可用架构
Kafka作为一个分布式流处理平台,主要由以下几个核心组件构成:
- Producer(生产者):负责将数据发送到Kafka集群。
- Consumer(消费者):负责从Kafka集群中读取数据。
- Broker(代理):Kafka集群中的每一个服务器称为一个Broker,负责存储数据并提供服务。
- Topic(主题):数据的逻辑分类单元,生产者和消费者通过主题来进行数据的发布和订阅。
- Partition(分区):每个主题可以划分为多个分区,以实现数据的并行处理和负载均衡。
- Replica(副本):每个分区可以有多个副本,以提高数据的可靠性和容错能力。
Kafka的分区和副本机制
Kafka的分区机制使得数据可以水平分割,这样可以同时在多个节点上进行处理,从而提升了系统的吞吐量和处理能力。每个分区在Kafka集群中可以有多个副本,主副本称为Leader,其它副本称为Follower。Leader负责处理所有的读写请求,而Follower则被动地从Leader同步数据。
这种机制带来的好处显而易见:
- 高可用性:当Leader节点出现故障时,Kafka可以自动选举新的Leader,确保系统的高可用性。
- 容错性:由于有多个副本,即使某些节点发生故障,数据也不会丢失,系统可以继续正常运行。
Kafka的容错设计
Kafka通过ZooKeeper来管理集群的元数据和节点状态。ZooKeeper不仅负责维护Broker列表,还负责选举Leader、管理消费位移等重要任务。当Broker节点失效时,ZooKeeper会感知到变化,并触发副本之间的Leader选举过程,确保服务的持续可用。
Kafka的高效和可伸缩性
Kafka不仅具有高可用性,其高效和可伸缩性也是其被广泛应用的重要原因。
批处理和异步处理
Kafka对批处理和异步处理做了大量的设计,使其在高吞吐量的场景下表现出色:
- 批处理:Kafka允许生产者和消费者以批量的方式发送和接收消息。这种方式减少了网络传输的开销,提高了数据传输的效率。
- 异步处理:Kafka的生产者和消费者都支持异步模式,生产者可以在不等待服务器响应的情况下继续发送下一条消息,从而提升了整体的处理效率。
高性能表现
得益于批处理和异步处理机制,Kafka在实际应用中表现出了极高的性能。据统计,Kafka每秒可以处理几十万条异步消息,如果开启了压缩功能,这一数字可以进一步提升,最终达到每秒处理2000万条消息的级别。这对于大数据处理和流计算领域来说,绝对是一个令人振奋的性能表现。
可伸缩性设计
Kafka的分区机制使得其具有良好的可伸缩性。通过增加分区数,可以很容易地将负载分散到多个Broker上,从而提升系统的整体处理能力。同时,Kafka还支持动态增加分区和Broker,使得系统可以根据业务需求灵活扩展。
Kafka的应用场景
大数据处理
在大数据处理领域,Kafka常被用作数据管道的核心组件。它可以高效地收集、存储和传输海量数据,确保数据在传输过程中的一致性和可靠性。许多企业利用Kafka来构建实时数据分析平台,实现对海量数据的实时处理和分析。
流计算
流计算是指对数据流进行实时处理和分析的技术。Kafka与流计算框架(如Apache Flink、Apache Storm等)结合,可以实现对实时数据的高效处理。Kafka的高吞吐量和低延迟特性,使其成为流计算系统中的理想数据源和数据缓冲区。
日志收集和分析
Kafka还常用于日志收集和分析场景。通过Kafka,应用程序的日志数据可以被实时收集,并传输到日志分析系统中进行存储和分析。这样,运维人员可以实时监控系统的运行状态,及时发现和解决问题。
Kafka的局限性
尽管Kafka有诸多优势,但在某些场景下也有其局限性。由于Kafka采用了异步和批处理的机制,虽然提升了性能,但也带来了一定的延迟。这种延迟在一些对实时性要求极高的场景中(如电商交易系统)可能不太适用。
延迟问题
Kafka的设计初衷是为了高吞吐量和高可用性,因而在某些场景下,延迟问题不可避免。特别是在电商场景中,实时交易处理需要非常低的延迟,而Kafka的异步处理和批处理机制可能无法满足这种极端的实时性要求。
数据一致性
虽然Kafka通过副本机制提高了数据的可靠性,但在极端情况下,仍可能存在数据不一致的问题。例如,在Leader和Follower之间的数据同步过程中,如果发生网络分区或节点故障,可能会导致数据暂时不一致。
配置和管理复杂
Kafka作为一个分布式系统,其配置和管理相对复杂。特别是在大规模集群中,Kafka的运维和监控需要丰富的经验和专业知识。这对于初次接触Kafka的运维人员来说,可能会有一定的学习曲线。
总结
总的来说,Kafka凭借其高可用、高效和可伸缩的特性,成为了大数据和流计算领域的明星组件。它的分区和副本机制确保了系统的高可用性和容错能力,而批处理和异步处理的设计则使其在高吞吐量场景中表现出色。
虽然Kafka在某些对实时性要求极高的场景中可能不太适用,但在大多数应用场景下,Kafka依然是一个非常强大和灵活的消息系统。无论是构建实时数据分析平台,还是进行日志收集和分析,Kafka都能提供稳定可靠的支持。
END
希望这篇文章能帮助大家更好地理解Kafka的高可用性设计和应用场景。如果你对Kafka有任何疑问或想进一步了解的内容,欢迎在评论区留言,我们一起交流探讨!
我是小米,一个喜欢分享技术的29岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号“软件求生”,获取更多技术干货!
推荐阅读
- 深入理解Kafka架构设计
- Kafka在大数据处理中的应用案例
- Kafka与流计算框架的完美结合
