问题一:Flink读取mysql比较慢,导致延迟比较大 有啥提速方式呀?
Flink读取mysql比较慢,导致延迟比较大 有啥提速方式呀?
参考答案:
Flink读取MySQL数据速度慢,可以通过以下几种方式来尝试提速:
- 优化作业配置:
- 增加JobManager和TaskManager的资源分配。例如,提高CPU和内存的大小,以适应并发大或拓扑复杂的作业需求。
- 根据作业的特点调整并行度,合理分配资源以提高数据处理效率。
- 使用Flink CDC:
- Flink CDC(Change Data Capture)是一种高效的数据同步工具,可以实现MySQL的整表和增量读取。相比于传统的JDBC方式,CDC通常能提供更低的延迟和更高的吞吐量。
- 通过Flink CDC抓取MySQL中的数据,并将其汇入到目标存储系统中,这种方式可以大幅提高数据读取的效率。
- JDBC优化:
- 确保使用的JDBC驱动是最新版本,且与MySQL数据库版本兼容。
- 调整JDBC连接参数,如增加连接池大小、调整批量获取数据的阈值等,以减少网络往返次数和提高数据传输效率。
- SQL语句优化:
- 对SQL查询进行优化,避免复杂的联接和子查询,减少数据扫描的范围。
- 使用分区表和索引来加速查询过程。
- 网络优化:
- 确保Flink集群与MySQL数据库之间的网络连接稳定且带宽充足。
- 如果可能,将Flink集群部署在与MySQL数据库同一局域网内,以减少网络延迟。
- 硬件优化:
- 升级MySQL服务器的硬件,如使用更快的磁盘(SSD)、更多的内存和更强大的CPU。
综上所述,提升Flink读取MySQL的速度需要从多个方面进行考虑和调整,包括作业配置、数据同步工具的选择、JDBC连接的优化、SQL查询的优化以及硬件资源的升级等。通过综合这些方法,您可以有效提高Flink读取MySQL的性能,减少延迟。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/601779
问题二:Flink的cdas后续会支持自动加表吗?例如,.* 或者正则
Flink的cdas后续会支持自动加表吗?例如,.* 或者正则
参考答案:
这个正在看怎么不中断作业,现在的情况是需要重启一下作业,停下来打一个cp,然后再启动。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/601778
问题三:Flink的这个假如用时间函数过滤 , 是会一直动态生效的吧?
Flink的这个假如用时间函数过滤 , 是会一直动态生效的吧? 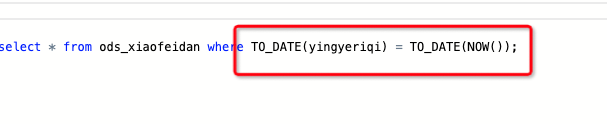
参考答案:
在Flink中,使用时间函数进行过滤时,是会一直动态生效的。
Flink的时间处理机制是基于事件时间(EventTime)或处理时间(ProcessingTime)的概念来实现的。这意味着,一旦定义了时间特性和时间戳,Flink会根据这些信息来处理数据流,并在指定的时间窗口内进行计算。例如,如果您定义了一个基于时间的窗口,如滑动窗口或滚动窗口,Flink会自动根据数据的时间和窗口的定义来分配数据到相应的窗口,并在窗口关闭时触发计算。
具体来说,Flink中的窗口算子(如window)会根据时间戳和水位线(Watermarks)来动态地将数据分配到不同的窗口中。当窗口根据定义的时间长度达到时,Flink会触发窗口的计算逻辑,例如求和、计数或其他用户自定义的操作。这种机制确保了数据处理的连续性和动态性,使得时间函数能够在数据流不断流入的情况下持续生效。
此外,Flink还支持动态更新规则,例如在Flink CEP(Complex Event Processing)作业中,可以动态加载最新的规则来处理上游Kafka数据。这使得Flink能够适应变化的业务需求,实时地对数据流进行处理和分析。
综上所述,Flink的时间函数确实能够动态生效,并且可以根据业务需求进行灵活配置和更新。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/601777
问题四:删除流没有被识别到, 后面加了一个参数 暂时解决。这个是Flink的bug吗?
删除流没有被识别到, 后面加了一个参数 暂时解决。这个是Flink的bug吗?
参考答案:
不是产品 bug,和您的代码相关【sink 有非确定性函数字段now(),影响了 upsert materialize 节点,后续会增加相应文档说明】。Flink 引擎侧VVR 6.0.7 和 8.x 版本在上线前都会给用户提示的~ 
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/601776
问题五:如果用Flink cdc 直接接业务数据,我们应该怎么去避免我们下游的计算任务和接入不出问题?
如果用Flink cdc 直接接业务数据,如果突然业务这边要回刷一整年的订单某个一段。这种我们应该怎么去避免我们下游的计算任务和接入不出问题,这个数据量和资源有比例吗?
参考答案:
在回刷之前用动态参数调整把并发度调整上去,具体的得看你们的数据量和计算量了。 https://help.aliyun.com/zh/flink/user-guide/dynamically-update-deployment-parameters?spm=a2c4g.11174283.0.i2
关于本问题的更多回答可点击进行查看:

