本文来源:支付宝体验科技公众号
编者按:本文作者是蚂蚁集团前端工程师茂松,从非算法同学的视角窥探大模型的理论和实践,欢迎查阅~
前言
当前 LLM(Large Language Model) 大语言模型越来越火,在业务和生活中已经逐渐变得人尽皆知,作为一名技术同学,可以不精通其中的细节,但了解其大致的奥义是应该必备的技术素养,最起码应该清楚大模型是怎么运作的,在业务中我们可以与其建立什么链接,这也是我写这篇文章的主要原因。
本文借鉴了多方文章,加入了自己的理解,由于大部分相关文章都比较有技术壁垒,很多同事包括我读起来都比较晦涩,因此我尽可能将其转化为比较易懂的语言。
我本人也不是专业的算法同学,因此只能用比较浅薄的视角窥探一部分大模型的理论和实践,如果有描述不清或有误之处还请批评指出。
ChatGPT 的概念
GPT 对应的是三个单词:Generative,Pre-Training,Transformer。
Generative:生成式,比较好理解,通过学习历史数据,来生成全新的数据。ChatGPT 回答我们提出的问题时,是逐字(也有可能是三四个字符一起)生成的,如果你使用 ChatGPT 时仔细观察它回答你的方式,你可能会对「逐字」这个概念有更深的感触。这里逐字生成的时候每一个字(或词,在英文中也可能是词根)都可以被称作一个 token。
Pre-Training:预训练,顾名思义就是预先训练的意思。举个简单的例子,如果我们想让一个对英语一窍不通的同学去翻译并总结一篇英语技术文章,那么对这个同学来说就需要先学会英文 26 个字母,进而学会单词语法等,再去了解这篇文章相关的技术,最后才能去完成我们指派的任务。但是如果让一个对英语已经很精通的同学来做这个任务就相对简单的多,他只需要去大致了解一下这篇文章所涉及到的技术,便能很好的总结出来。
这就是预训练,先把一些通用能力提前训练出来。人工智能本身就是一个不断训练参数的过程,如果我们可以提前把通用能力相关的参数提前训练好,那么在一些特殊的场景,发现通用能力不能完全适配时,只做简单的参数微调即可,这样做大幅减少了每个独立训练预测任务的计算成本。
Transformer:这是 ChatGPT 的灵魂,它是一个神经网络架构。后文再进行详细的说明。
以上就是 ChatGPT 的基本概念,结合起来就是一个采用了预训练的生成式神经网络模型,它能够对人类的对话进行模拟。
ChatGPT 的核心任务
ChatGPT 的强大推理能力确实令人印象深刻,它的核心任务就是能够生成一个符合人类书写习惯的下一个合理的内容。具体的实现逻辑就是根据大量的网页、数字化书籍等人类撰写内容的统计规律,推测接下来可能出现的内容。
逐字(词)推测:
体验 ChatGPT 时如果细心观察会发现 ChatGPT 回答问题时是逐字或逐词来进行回答的,这也就是 ChatGPT 的本质:按照上下文来对下一个要出现的字或词进行推测。比如要想让 ChatGPT 预测“湖人总冠军”这五个字,它会经历如下步骤:
- 输入“湖”这个字,输出可能是“泊”,“人”,“水”这三个字,其中结合上下文概率最高的是“人”字
- 输入“湖人”这两个字,输出可能是“总”,“真”,“牛”这三个字,其中结合上下文概率最高的是“总”字
- 输入“湖人总”这三个字,输出可能是“冠”,“赢”,“经”这三个字,其中结合上下文概率最高的是“冠”字
- 输入“湖人总冠”这四个字,输出可能是“名”,“王”,“军”这三个字,其中结合上下文概率最高的是“军”字
由于 ChatGPT 学习了大量人类现有的各种知识,所以它可以进行各种各样的预测,这就是 transformer 模型最终做的事情,但实际原理要复杂得多。
人工智能的基础知识
在介绍 ChatGPT 的原理之前,先学习一下人工智能的一些基础知识:
机器学习:
机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并将这些规律应用到未观测数据样本上的方法。主要研究内容是学习算法。基本流程是基于数据产生模型,利用模型预测输出。目标是让模型有较好泛化能力。
举一个经典的例子,我们挑西瓜的时候是如何判断一个西瓜是否成熟的呢?每个人一开始都是不会挑选的,但是随着我们耳濡目染,看了很多挑西瓜能手是怎么做的,发现可以通过西瓜的颜色,大小,产地,纹路,敲击声等等因素来判断,那么这个就是一个学习的过程。
参数 / 权重:
所有的人工智能都有一个模型,这个模型可以简单的被理解为我们数学里的一个公式,比如一个线性公式:,参数(权重)就是和,这个线性公式中只有这两个参数,那么带入到 ChatGPT 中,3.0 版本已经有了 1750 亿个参数,4.0 的参数规模未公布,但可以猜测只会比 3.0 版本更多而不会更少。因此在这样巨大的参数规模中进行调参训练是一个非常耗费机器(GPU)的工作,所以需要大量的资金和机房支持。
监督学习 / 无监督学习:
监督学习:简单的理解就是给算法模型一批已经标记好的数据,比如上面的例子,我们提前给模型提供 1000 个西瓜,并且标记好这 1000 个西瓜是否已经成熟,然后由模型自己不断去学习调整,计算出一组最拟合这些数据的函数参数,这样我们在拿到一个全新的西瓜时,就可以根据这组参数来进行比较准确的预测。
无监督学习:就是我们扔给模型 1000 个西瓜,由算法自己去学习他们的特征,然后把相似的类逐渐聚合在一起,在理想情况下,我们希望聚合出 2 个类(成熟和不成熟)
过拟合 / 欠拟合:
在我们的模型进行训练的时候,最终的目的就是训练出一组参数来最大限度的能够拟合我们训练数据的特征,但是训练的过程总不会是一马平川的,总会出现各种问题,比较经典的就是过拟合和欠拟合。
直接举例说明更直接一点,如下图,我们希望模型能尽量好的来匹配我们的训练数据,理想状态下模型的表现应当和中间的图一致,但实际训练中可能就会出现左右两种情况。左边的欠拟合并并没有很好的拟合数据,预测一个新数据的时候准确率会比较低,而右侧看起来非常好,把所有的数据都成功拟合了进去,但是模型不具有泛化性,也没有办法对新的数据进行准确预测。

那么怎么解决过拟合和欠拟合的问题呢?可以根据模型训练中的实际表现情况来进行正则化处理,降低复杂度处理等方法,这一点可以自行查阅相关资料。
有监督微调(SFT)
有监督微调(SFT,Supervised Fine-Tuning):是一种用于机器学习的超参数调整方法,它可以使用从未见过的数据来快速准确地调整神经网络的权重参数,以获得最佳的性能。它可以帮助机器学习模型快速地从训练数据中学习,而不需要重新训练整个网络。
强化学习模型(PPO)
强化学习模型(PPO,Proximal Policy Optimization):是一种强化学习算法,可以使智能体通过最大化奖励信号来学习如何与环境进行交互。它是一种非官方算法,使用剪裁目标函数和自适应学习率来避免大的策略更新。PPO 还具有学习可能不完全独立和等分布数据的优势。
人类反馈强化学习(RLHF):
人类反馈强化学习(Reinforcement Learning with Human Feedback )是训练 GPT-3.5 系列模型而创建的。RLHF 主要包括三个步骤:使用监督学习训练语言模型;根据人类偏好收集比较数据并训练奖励模型;使用强化学习针对奖励模型优化语言模型。它使模型能够通过从人类获取反馈,从而不断改进自身学习技能,从而有效地适应实际环境。
再简单的解释一下,因为 LLM 需要大量的训练数据。通过人工反馈从零开始训练它们是不合理的。所以可以通过无监督学习进行预训练,将现成的语言模型创建并做输出。然后我们训练另一个机器学习模型,该模型接收主模型生成的文本并生成质量分数。这第二个模型通常是另一个 LLM,它被修改为输出标量值而不是文本标记序列。
为了训练奖励模型,我们必须创建一个 LLM 生成的质量标记文本数据集。为了组成每个训练示例,我们给主 LLM 一个提示并让它生成几个输出。然后,我们要求人工评估人生成文本的质量。然后我们训练奖励模型来预测 LLM 文本的分数。通过在 LLM 的输出和排名分数上进行训练,奖励模型创建了人类偏好的数学表示。
最后,我们创建强化学习循环。主 LLM 的副本成为 RL 代理。在每个训练集中,LLM 从训练数据集中获取多个提示并生成文本。然后将其输出传递给奖励模型,该模型提供一个分数来评估其与人类偏好的一致性。然后更新 LLM 以创建在奖励模型上得分更高的输出。
神经网络:
对比人脑来看,当信息进入大脑时,神经元的每一层或每一级都会完成其特殊的工作,即处理传入的信息,获得洞见,然后将它们传递到下一个更高级的层。
神经网络也是如此,最基本形式的人工神经网络有三层神经元。信息从一层神经元流向另一层,就像在人脑中一样:
- 输入层:数据进入系统的入口点
- 隐藏层:处理信息的地方
- 输出层:系统根据数据决定如何继续操作的位置
每一层的每一个节点,都会对模型的某个参数进行调整计算,在大部分情况下,每个当前节点与上层的所有节点都是相连的。
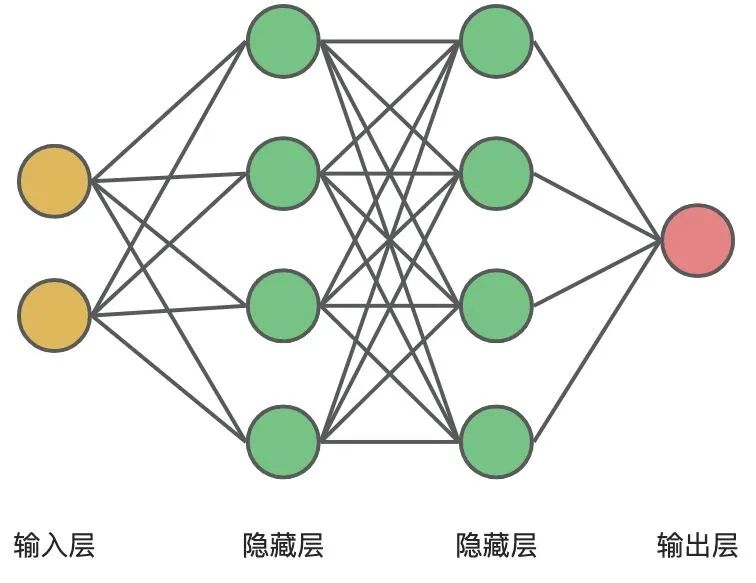
在 ChatGPT 中的神经网络却不是每个给定层都与前一层的每个神经元基本上相连,因为如果要处理具有特定已知结构的数据,这种完全连接的网络有很大概率是 overkill 的。因此,在处理图像的早期阶段,通常会使用所谓的卷积神经网络(“convnets”),其中神经元实际上是布置在类似于图像像素的网格上,并且仅与网格附近的神经元相连。
Transformer 基本原理
第一步:embedding
embedding 的过程可以简单的理解为向量化。因为输入是一个个的词(token),那需要把它映射成一个向量,embedding 就是给定任何一个词,用一个向量来表示它。
在 embedding 的过程中,每个 token 都用一个单层神经网络转化为长度为 768(对于GPT-2)或 12288(对于ChatGPT的GPT-3)的 embedding 向量。
同时,模块中还有一个“辅助通路”(secondary pathway),用于将 token 的整数位置转化为 embedding 向量。最后,将 token 值和 token 位置的 embedding 向量加在一起,生成最终的 embedding 向量序列。
那么为什么要将 token 值和 token 位置的 embedding 向量相加呢?只是尝试了各种不同的方法后发现这种方法似乎可行,而且神经网络的本身也认为,只要初始设置“大致正确”,通过足够的训练,通常算法可以自动调整细节。
以字符串“湖人”为例,在 gpt-2 中它可以将其转化为一系列长度为 768 的 embedding 向量,其中包括从每个 token 的值和位置中提取的信息。
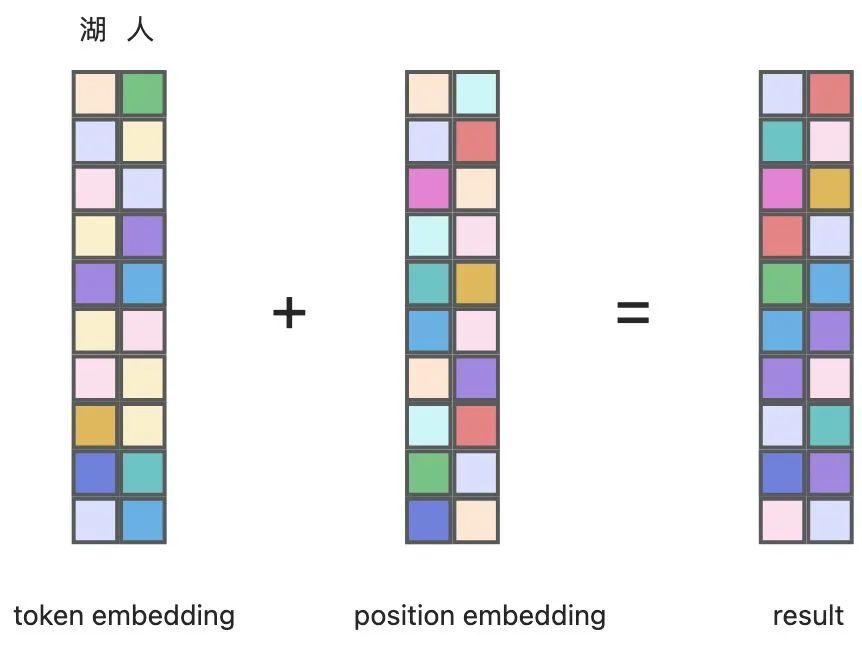
第一张图中就是 token embedding,纵向一列代表一个向量,可以看到最先排列的是“湖”所代表的向量,然后是“人”所代表的向量。第二张图是位置的 embedding,代表着这两个字的位置信息。将这两两个 embedding 相加得到了最终的 embedding 序列。
第二步:Attention
Attention 是整个 transformer 的主要部分,其内部结构是非常复杂的,我作为一名非专业人士,无法面面俱到的将其中的细节完全解释清楚,因此只能把它的核心能力简单叙述一二。
在进行 embedding 之后,需要对一系列的“注意力块”进行数据操作(gpt3 中有 96 个注意力块),而每个“注意力块”中都有一组 attention heads,每个 attention head 都独立地作用于 embedding 向量中不同值的块。
attention head 的作用就是对历史的 token 序列进行回顾,这里的历史 token 序列就是已经生成的文本,之后将这些信息进行打包,以便找到下一个 token。稍微具体的来说,attention head 的作用是重新组合与不同 token 相关的 embedding 向量的块,并赋予一定的权重。
举个例子:
用 ChatGPT 翻译句子“蚂蚁集团”到“ant group”举例,首先进行上一步 embedding 操作,将句子向量化并吸收句子位置信息,得到一个句子的初始向量组。
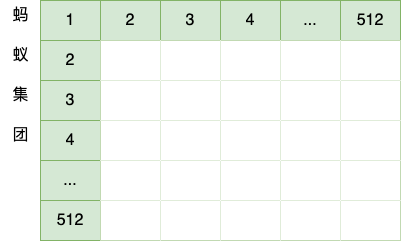
由于样本每个句子长短不同,所以每个句子都会是一个 512 x 512 的矩阵,如果长度不够就用 0 来代替。这样在训练时,无论多长的句子,都可以用一个同样规模的矩阵来表示。当然 512 是超参,可以在训练前调整大小。
接着,用每个字的初始向量分别乘以三个随机初始的矩阵分别得到三个量Qx,Kx,Vx,这样就得到了三个量:Qx,Kx,Vx,比如用“蚂”这个字举例:

然后,计算每个单词的 Attention 数值,比如“蚂”字的 Attention 值就是用“蚂”字的 蚂 分别乘以句子中其他单词的 K 值,两个矩阵相乘的数学含义就是衡量两个矩阵的相似度。
第三步:将向量转为概率
继续用上面翻译的例子:用计算出的每个单词的 Attention 值,通过一个 SoftMax 转换(这里不必关注是怎么转换的),计算出它跟每个单词的权重,这个权重比例所有加在一起要等于 1。再用每个权重乘以相对应的 V 值。所有乘积相加得到这个 Attention 值。
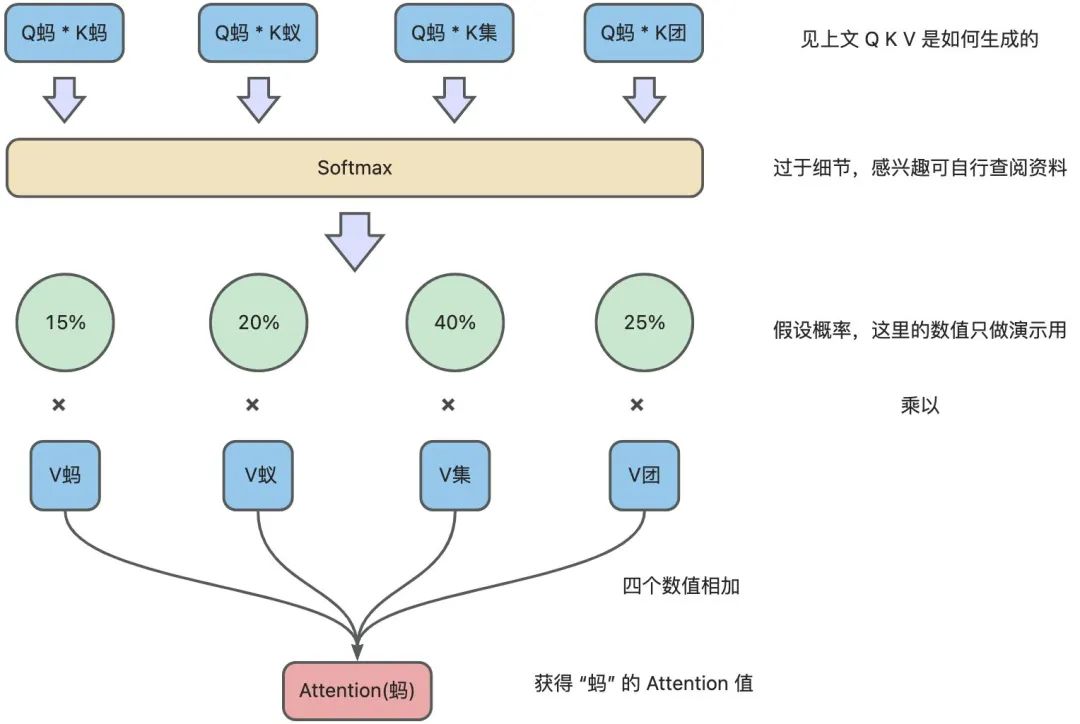
这个 Attention 数值就是除了“蚂”字自有信息和位置信息以外,成功的得到了这个句子中每个单词的相关度信息。
在计算 Attention 之后,每个单词根据语义关系被打入了新的高维空间,这就是 Self-Attention(自注意力机制)。
但在 transformer 里,并不是代入了一个空间,而是代入了多个高维空间,叫做 Multi-Head Attention (多头注意力机制)。将高维空间引入模型训练的主要原因是它在训练时表现出很好的效果,这是人工智能科研论文的一个常见特点,研究人员凭借着极高的科研素养和敏感性,发现一些方向,并通过测试证明其有效性,但不一定有完美的理论支持。这为后续研究者提供了进一步完善的余地。
事实证明,如何提升 Attention(Q,K,V)效率是 transformer 领域迭代最快的部分。
这就是 transformer 的大致原理,有一些细节我个人也没有深入研究,有兴趣的人可以自行去搜索。
总结:
用一张图来表示上面的步骤:
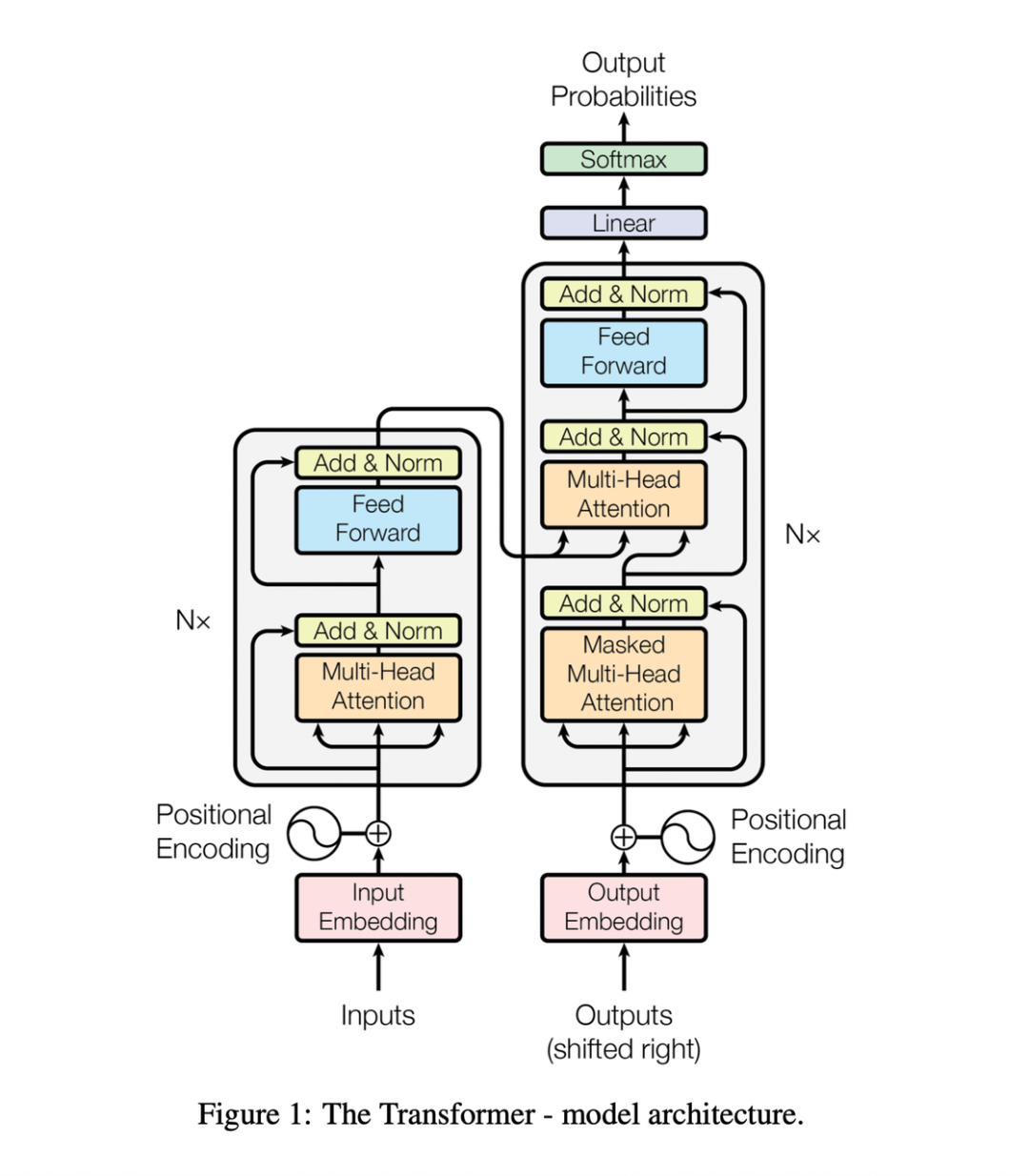
借用阿里巴巴集团暮诗同学标注后的图,看下各部分的职责:

每一个部分我们基本上已经大致都讲述过了,现在我们对 ChatGPT 的实现原理有了简单的认识。
训练数据从哪来以及如何训练?
ChatGPT 的训练数据来源包括维基百科、书籍、期刊、Reddit 链接、Common Crawl 和其他数据集,共计约 45TB 的数据,其中包含了近 1 万亿个单词的文本内容,相当于 1351 万本牛津词典或 1125 万本书。这些数据涵盖了截至 2021 年的海量知识,这也是 ChatGPT 能够与时俱进地解读出很多现实世界新型事物的含义的原因之一。
有了这些数据之后,就可以训练我们的模型,这里就要用到 RLHF 来进行反馈和训练了。这类学习方法通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。
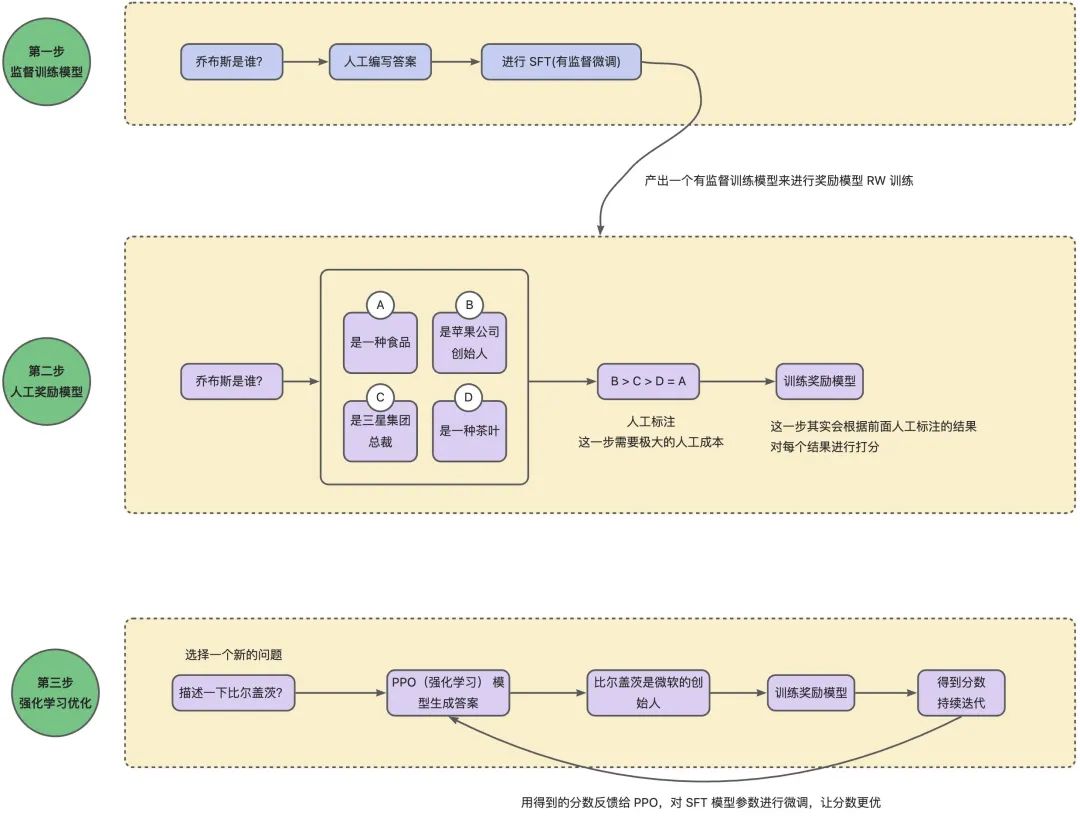
从上图中我们可以看出,ChatGPT 的训练可以分成3步:
- 根据采集的 SFT 数据集对 GPT-3 进行有监督的微调(Supervised FineTune,SFT);
- 收集人工标注的对比数据,训练奖励模型(Reword Model,RM);
- 使用 RM 作为强化学习的优化目标,利用 PPO 算法微调 SFT 模型。
ChatGPT 的 prompt 使用技巧
prompt 的这个单词本意就是「提示」,顾名思义当我们使用 ChatGPT 的时候,如果我们能够给 ChatGPT 一定的提示,那么就会更容易获得我们想要的结果。简单的说,就是给 ChatGPT 提供一些信息的增量,比如你你希望输出的 sql 格式等,把这些内容作为“固定的上下文”,再来跟 ChatGPT 提问,这样就能获得更符合预期的效果。
当我们能熟练使用 prompt 后,我们会极大的提升使用 ChatGPT 的效率,这里的效率不仅是获取我们想要的结果这一方面,还会极大的提升我们使用 ChatGPT 时同类问题的复用性,因为一个完成度很好的 prompt 可以分发给所有有类似需求的人直接使用。
To Do and Not To Do
看下 openAI 的官方推荐文档中是这样说的:
Instead of just saying what not to do, say what to do instead. 与其告知模型不能干什么,不妨告诉模型能干什么。
案例场景:推荐雅思必背英文单词:
prompt1:Please suggest me some essential words for IELTS ❌
prompt2:Please suggest me 10 essential words for IELTS ✅
说明:后者 prompt 会更加明确,前者会给大概 20 个单词。这个仍然有提升的空间,比如增加更多的限定词语,像字母 A 开头的词语。
增加示例
直接告知 AI 什么能做,什么不能做外。在某些场景下,我们能比较简单地向 AI 描述出什么能做,什么不能做。但有些场景,有些需求很难通过文字指令传递给 AI,即使描述出来了,AI 也不能很好地理解。这时我们应该追加部分示例。
案例场景:让 ChatGPT 起名:
prompt1:帮我起三个男生名字 ❌
prompt2:帮我起三个男生名字,比如:龙傲天 ✅
说明:在没有示例的情况下,得到的结果是王伟,张伟这些平平无奇的名字,当我们有了示例,ChatGPT 给到了我们风清扬,云中鹤这些武侠风的名字
使用引导词,引导模型输出特定内容
在代码生成场景里,有一个小技巧,在 prompt 最后,增加一个代码的引导,告知 AI 我已经将条件描述完了,你可以写代码了。
案例场景:让 ChatGPT 写代码:
prompt1:
Create a MySQL query for all students in the Computer Science Department: Table departments, columns = [DepartmentId, DepartmentName] Table students, columns = [DepartmentId, StudentId, StudentName] ❌
prompt2:
Create a MySQL query for all students in the Computer Science Department: Table departments, columns = [DepartmentId, DepartmentName] Table students, columns = [DepartmentId, StudentId, StudentName] SELECT ✅
说明:在 prompt 的最后增加 SELECT 可以很好地提示 AI 可以写 SQL 代码了。
使用特殊符号指令和需要处理的文本分开
不管是信息总结,还是信息提取,你一定会输入大段文字,甚至多段文字,此时有个小技巧。
可以用 """ 将指令和文本分开。根据我的测试,如果你的文本有多段,增加 """ 会提升 AI 反馈的准确性。
案例场景:让 ChatGPT 汇总信息:
prompt1:
Please summarize the following sentences to make them easier to understand.
OpenAI is an American artificial intelligence (AI) research laboratory consisting of the non-profit OpenAI Incorporated (OpenAI Inc.) and its for-profit subsidiary corporation OpenAI Limited Partnership (OpenAI LP). OpenAI conducts AI research with the declared intention of promoting and developing a friendly AI. OpenAI systems run on the fifth most powerful supercomputer in the world.[5][6][7] The organization was founded in San Francisco in 2015 by Sam Altman, Reid Hoffman, Jessica Livingston, Elon Musk, Ilya Sutskever, Peter Thiel and others,[8][1][9] who collectively pledged US$1 billion. Musk resigned from the board in 2018 but remained a donor. Microsoft provided OpenAI LP with a $1 billion investment in 2019 and a second multi-year investment in January 2023, reported to be $10 billion.[10] ❌
prompt 2:
Please summarize the following sentences to make them easier to understand. Text: """
OpenAI is an American artificial intelligence (AI) research laboratory consisting of the non-profit OpenAI Incorporated (OpenAI Inc.) and its for-profit subsidiary corporation OpenAI Limited Partnership (OpenAI LP). OpenAI conducts AI research with the declared intention of promoting and developing a friendly AI. OpenAI systems run on the fifth most powerful supercomputer in the world.[5][6][7] The organization was founded in San Francisco in 2015 by Sam Altman, Reid Hoffman, Jessica Livingston, Elon Musk, Ilya Sutskever, Peter Thiel and others,[8][1][9] who collectively pledged US$1 billion. Musk resigned from the board in 2018 but remained a donor. Microsoft provided OpenAI LP with a $1 billion investment in 2019 and a second multi-year investment in January 2023, reported to be $10 billion.[10] """ ✅
Please summarize the following sentences to make them easier to understand.
Text: """
其他技巧
类似的技巧还有一些,由于篇幅原因不再一一赘述,详细可以查看一下两个网站:
openAI 官方最佳实践:https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api
learningPrompt wiki:https://learningprompt.wiki/docs/category/%EF%B8%8F-%E6%8A%80%E5%B7%A7%E7%AF%87
大模型如何和我们的业务结合起来?
当我们了解了大模型的基本原理和一些使用技巧之后,最重要的还是思考在这个大模型时代让我们的业务也能和大模型结合起来。我这里抛砖引玉的说一下自己的一些想法,每一个想法只做简单叙述,不深入讨论。
prompt 平台建设
prompt 的使用作为大模型时代必备的技能,我们不必要求每一个员工都完全精通各类 prompt 技巧,而可以将 prompt 的生成变得工程化,可以作为一个中间件也可以作为一个平台,集成各类业务的 prompt 模板,比如可以分为数据分析模板,业务总结模板,智能客服模板等等提供给真实业务去使用。
prompt 收拢管理后会极大提升蚂蚁所有业务的大模型相关业务效率,并可以在数据安全等方面做出合规监控,也可以极大的降低新手上手成本,同时由于各个业务场景不同,平台需要结合 ODPS,dataphin 等数据平台进行数据的绑定和聚合。
业内已经有比较成熟的 prompt 交易平台,比如 promptBase(https://promptbase.com/marketplace?model=gpt):
可以看到 prompt 作为一项资产,是大模型时代平台必备的基础能力之一。
数据分析 + 大模型
我所在的部门是大数据部门,目前蚂蚁集团进行数据分析或生成数据报表多使用 deepinsight,场景洞察,场景化自助分析这些平台,也有部分业务有自己搭建的看数平台,总之各个平台有各自的优缺点和定位,如何让这些平台能和大模型结合起来为整个数据分析场景提效?
我认为在这个领域提效整体分为两个模块:生成数据报表和数据分析。
生成数据报表的阶段可以结合 LLM 进行对话式图表生成,将数据投喂给 LLM 后提供 prompt,并结合各自业务特点进行 prompt 留存,与其他平台行程联动。
数据分析侧除了传统的让大模型告诉我们数据代表的含义之外,还可以让 LLM 对数据趋势做出预测。
在整个数据分析领域,我觉得难点在于上手成本,不仅包括对各类图表要熟悉,还要对分析有一定知识背景,而大模型最大的优势就是能弱化所有的上手成本,让分析小白也能看懂各类报表。
目前微软在这个领域已经有了比较先进的探索经验:Introducing Microsoft Fabric and Copilot in Microsoft Power BI(https://powerbi.microsoft.com/en-us/blog/introducing-microsoft-fabric-and-copilot-in-microsoft-power-bi/):
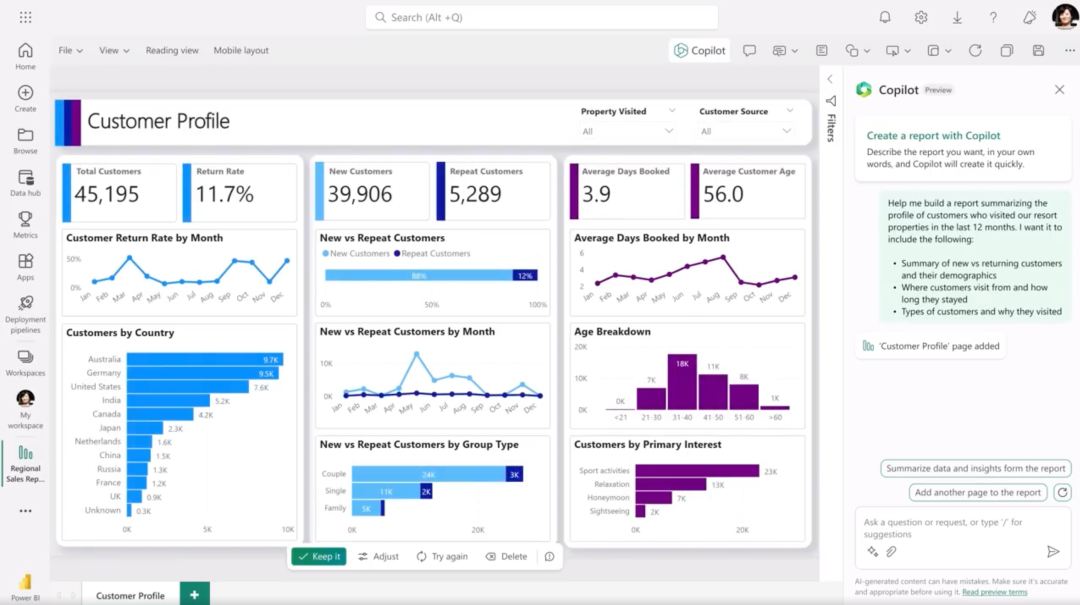
智能客服
大家体验过 ChatGPT 之后应该都会联想到客服相关的产品,各业务线的一个痛点就是都需要值班和答疑,以 Tracert 业务为例,每日答疑量是巨大的,巅峰时甚至占每日精力的 80%,这样对相关业务同学的心力消耗也是不可弥补的。
如果建设了智能客服平台,结合研发小蜜,将各业务的平台场景投喂进去之后,将会对所有业务线进行一次提效。目前在医疗,金融等领域,ChatGPT 的问答已经被训练得比较成熟了:
医疗:https://github.com/xionghonglin/DoctorGLM
金融:https://github.com/jerry1993-tech/Cornucopia-LLaMA-Fin-Chinese
法律:https://github.com/pengxiao-song/LaWGPT
code snippet + 大模型
大家一定体验过大模型的各类代码生成,其结果虽然不是百分百完全可用的,但是在很多场景下,ChatGPT 生成的代码基本上稍作修改就可以使用。目前有很多编辑器都做出了这方面的探索,比如 Cursor(https://github.com/getcursor/cursor)
好不好用只用试用了才知道,在我们不熟悉的领域,这类代码生成能弥补我们的能力短板,比如让一个不熟悉 SQL 的同学去捞数据,确实提升了生产力,但是一旦进入熟悉领域,比如让其生成一段业务代码,那会发现其实在组织提供 prompt 的过程中的耗时,不一定比直接写代码少。
除了代码生成这个领域,还可以涉足代码检测。比如代码提交后,CR 时加入大模型智能 CR,可以有效的识别到语法不规范等简单问题,当前蚂蚁的 code 平台已经在做类似的工作了。
大模型需要警惕的问题
谨防大模型一本正经胡说
当你使用 ChatGPT 时,有时候发现它在一本正经的胡说八道,比如:

这是因为大模型始终只是一个模型,不具有分别消息真假的能力,在我们熟悉的领域,如果出现了类似的错误我们可以立即发现,但是如果是一个陌生领域,那就有点危险。在模型的训练过程中,语料确实都是真实的正确的信息,但是在推理过程中不能百分百保证其正确性,一定要警惕。
警惕数据安全风险
各大公司的大模型如雨后春笋,为什么不能直接使用 openAI 的训练结果呢?一个是 ChatGPT 不开源,另一个是数据是各大公司的命脉,一旦使用外部大模型,无法组织数据安全的泄露。目前除了我国之外,意大利、德国、英国、加拿大、日本等多个国家的相关企业都开始发出警告,限制在业务运营中使用ChatGPT等交互式人工智能服务。
因此在我们使用外部大模型的过程中一定要警惕数据泄露的风险,切勿因小失大。
其他风险
近日 OWASP 发布了大型语言模型漏洞威胁 Top10,感兴趣的可以参考该文章:https://www.51cto.com/article/757021.html
写在最后
这是最好的时代,也是最坏的时代,在技术变革面前,跟不上节奏的人可能面临更大的风险。我们作为技术人,一定要跟上时代的潮流,但是同时也要明辨是非,不要一股脑全都投入大模型之中。
我们应该去掌握大模型能做什么,去思考业务如何能够和大模型融合,但是不必焦虑和恐慌,因为没有 AI 能取代你,能取代你的只有你停止不前的脚步。
参考文章
What Is ChatGPT Doing and Why Does It Work?:https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
Learning Prompt:https://learningprompt.wiki/
ChatGPT背后的核心技术:https://www.modb.pro/db/610013






