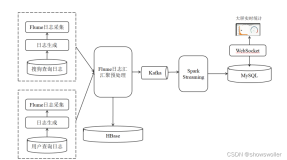
基于Spark中随机森林模型的天气预测系统
在这篇文章中,我们将探讨如何使用Apache Spark和随机森林算法来构建一个天气预测系统。该系统将利用历史天气数据,通过机器学习模型预测未来的天气情况,特别是针对是否下雨的二元分类问题。
简介
Apache Spark是一个开源的大数据处理框架,它提供了强大的API和工具,用于数据处理和机器学习。Spark的机器学习库(MLlib)提供了多种算法,包括分类、回归、聚类等,可以方便地进行大规模数据集的机器学习任务。随机森林是一种集成学习方法,它通过构建多个决策树并输出类别(分类)或平均预测(回归)来提高预测的准确性。
数据准备
首先,我们需要准备天气数据集。在这个例子中,我们使用了一个包含天气描述、最高温度、最低温度和风速的CSV文件。数据需要被加载到Spark DataFrame中,并进行预处理,以便后续的机器学习任务。
def read_data_from_csv(spark): df = spark.read.jdbc( url="jdbc:mysql://localhost:3306/big_data", table="etl_weather_data", properties={ "user": "root", "password": "12345678", "driver": "com.mysql.cj.jdbc.Driver" }) df.createTempView("weather") df = spark.sql(""" select *, cast(CASE WHEN weather LIKE '%雨%' THEN 0 ELSE 1 END as int)AS weather_condition from weather; """) return df
特征工程
特征工程是机器学习中的一个重要步骤,它涉及到从原始数据中选择和构建那些对模型预测最有帮助的特征。在这个案例中,我们将天气描述字符串转换为索引,并将风速转换为数值类型。
def data_feature_enginnering(df): indexer = StringIndexer(inputCol="weather", outputCol="weather_index") df_indexed = indexer.fit(df).transform(df) df_with_wind_speed_numeric = df_indexed.withColumn("wind_speed", df_indexed["wind_speed"].cast("double")) features_col = ["high_temperature", "low_temperature", "weather_index", "wind_speed"] assembler = VectorAssembler(inputCols=features_col, outputCol="features",handleInvalid="skip") df_assembled = assembler.transform(df_with_wind_speed_numeric).select("features", "weather_condition") return df_assembled
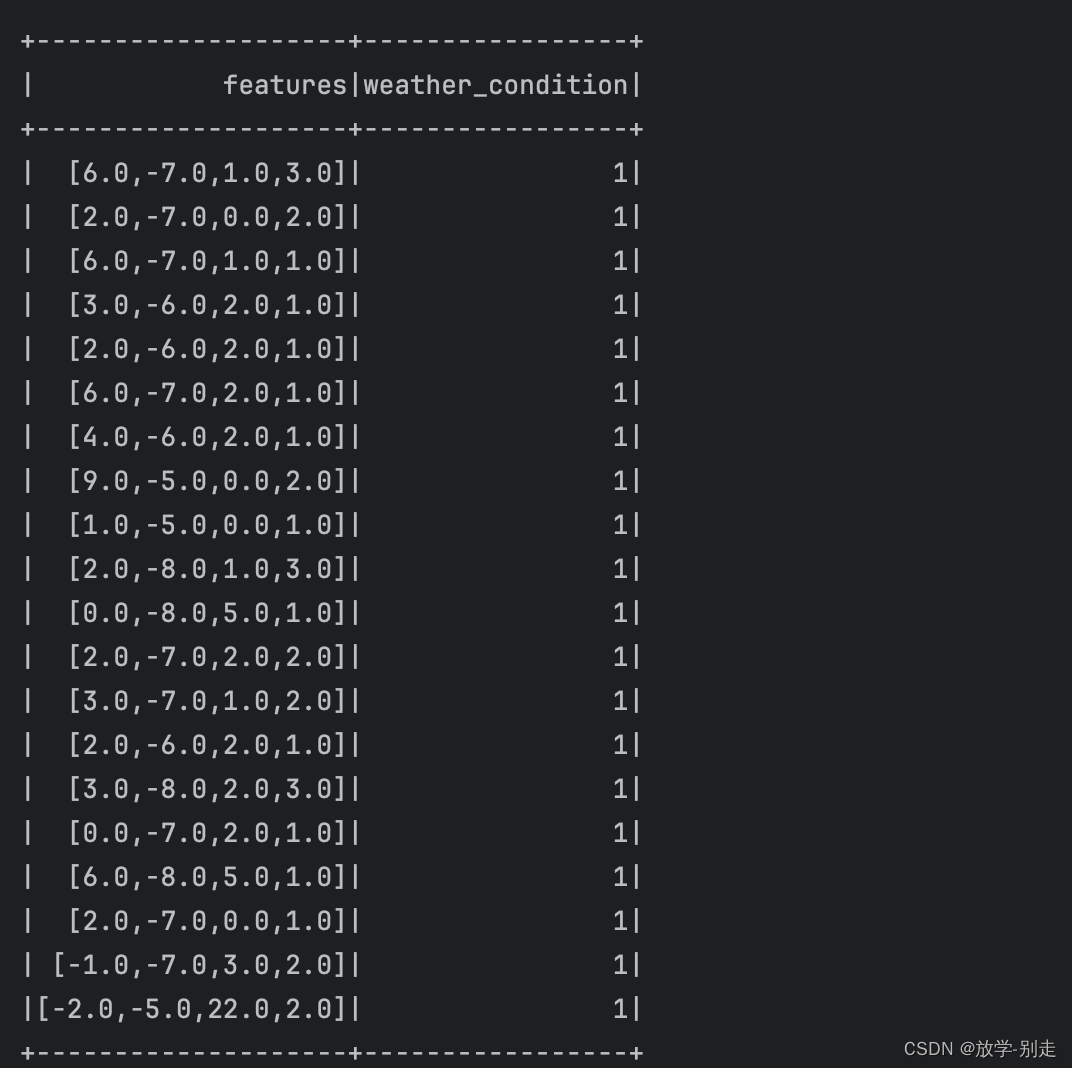
模型训练
在特征工程之后,我们将数据集分为训练集和测试集,使用随机森林分类器在训练集上进行模型训练,并在测试集上评估模型的性能。
def model_training(df_assembled): train_df, test_df = df_assembled.randomSplit([0.8, 0.2], seed=42) rf = RandomForestClassifier(featuresCol="features", labelCol="weather_condition",maxBins=160) model = rf.fit(train_df) # 评估模型 predictions = model.transform(test_df) evaluator = BinaryClassificationEvaluator(labelCol="weather_condition") accuracy = evaluator.evaluate(predictions) print(f"Model Accuracy: {accuracy}") predictions.show()

系统实现
整个系统是通过以下步骤实现的:
数据读取与预处理:使用Spark的JDBC读取器从数据库中读取天气数据,并进行初步的SQL处理,将天气情况转换为二元标签(下雨为0,否则为1)。
特征工程:通过StringIndexer和VectorAssembler等工具,将类别型特征转换为数值型,并组合成特征向量。
模型训练与评估:使用RandomForestClassifier进行模型训练,并通过BinaryClassificationEvaluator计算模型的准确率。
结果展示:最后,我们将展示模型的预测结果,以验证模型的有效性。
结论
通过使用Apache Spark和随机森林算法,我们成功构建了一个天气预测系统。该系统能够处理大规模数据集,并提供了较高的预测准确性。这证明了Spark在处理大数据和机器学习任务方面的实用性和强大能力。
此外,该系统也可以作为其他领域的预测模型的参考,例如交通流量预测、股票市场趋势分析等。随着数据量的增加和模型的进一步优化,我们期待该系统在未来能够提供更加精确的预测结果。