问题一:mysql增加默认值,这个ddl操作,会导致flink cdc任务同步失败吗?
mysql增加默认值,这个ddl操作,会导致flink cdc任务同步失败吗?
参考回答:
MySQL增加默认值的DDL操作(Data Definition Language,数据定义语言)不会影响Flume CDC(Change Data Capture,变更数据捕获)任务的正常运行。这是因为Flume CDC是基于MySQL binlog日志进行实时捕获数据变动的,只要MySQL仍然在产生binlog日志,Flume CDC就能继续监听和处理变动。
但是,在某些情况下,增加默认值的DDL操作可能会导致binlog日志产生大量的数据变动,这可能会增加Flume CDC的工作负载。如果 Flume CDC任务出现了同步失败的现象,可以检查以下几点:
- MySQL服务器的状态和性能,确保有足够的资源来应对大数量的DDL操作。
- Flume CDC任务的配置,确保任务的缓冲区大小足够大,能够承受大量的大量的DDL操作产生的数据变动。
- Flume CDC任务的日志级别,以便及时发现问题。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/568295
问题二:我们在使用阿里云flinksql 往clickhouse写数据的时候发现会丢数据或重复数据,怎么办?
我们在使用阿里云flinksql 往clickhouse写数据的时候发现会丢数据或重复数据,请问这个有什么解决方案吗? 我们是3个节点的clickhouse, 写的本地表
参数 WITH (
'connector' = 'clickhouse',
'url' = 'jdbc:clickhouse://ip1:8123,ip2:8223,ip3:8223/db',
'tableName' = '',
'userName' = '',
'password' = '',
'shardWrite' = 'true',
'batchSize' = '20000',
'flushIntervalMs' = '1000',
'maxRetryTimes' = '1'
);
自建的ck
参考回答:
ClickHouse结果表保证At-Least-Once语义,对于EMR的ClickHouse,提供Exactly Once的语义。https://help.aliyun.com/zh/flink/developer-reference/clickhouse-connector?spm=a2c4g.11174283.0.i2 如上。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/568294
问题三:Flink这个托管内存的使用率一直都是一个固定的值是吗?
Flink这个托管内存的使用率一直都是一个固定的值是吗?原来是100%,现在是95.93% 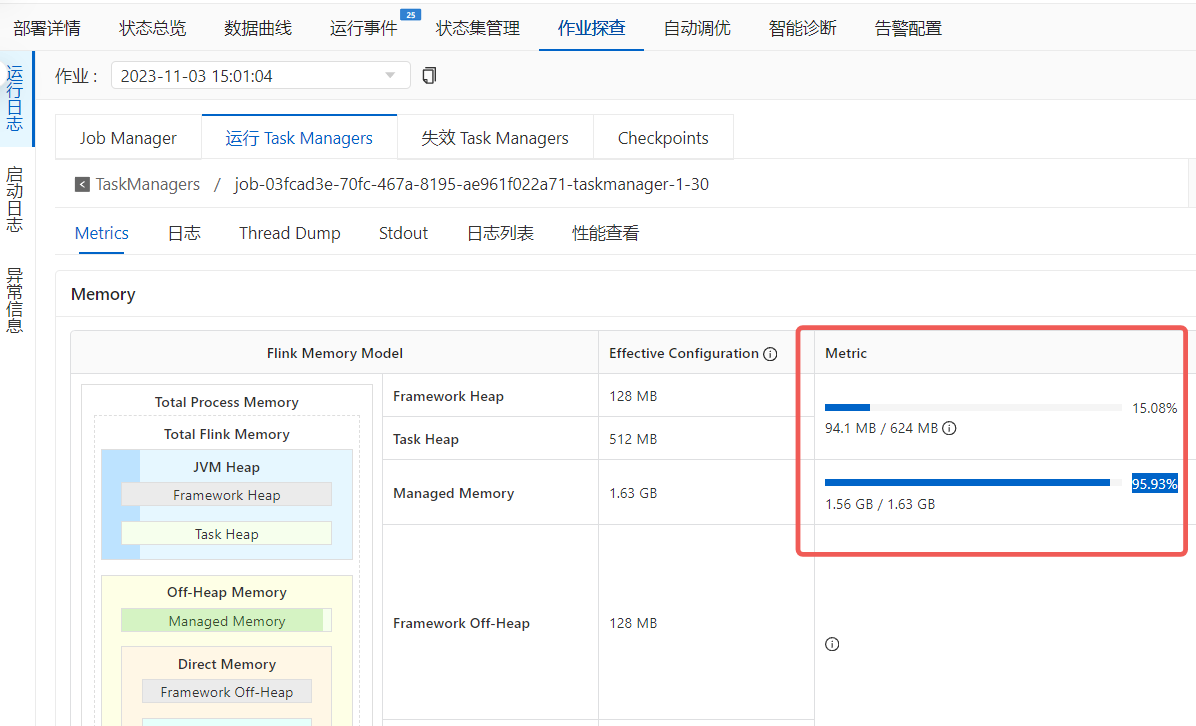
使用genimi backend,这个托管内存的比例是每个job都有固定的比例吗,还是每个job都不一样?
参考回答:
managed memory 一启动Gemini就会把所有分配给它的managed都claim过去,所以这上面是看不出实际用量的。没有配置的话,默认是0.4。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/568293
问题四:阿里云Flink里哪个产品可以像flume一样采集日志啊?
阿里云Flink里哪个产品可以像flume一样采集日志啊?
参考回答:
sls里面的logtail,es里面的filebeat。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/568292
问题五:flink-sql1.3数据从datahub摄入时间与sink hologres的时间怎么获取?
专有云flink-sql 1.3 数据从datahub摄入时间 与 sink hologres 的时间怎么获取?
参考回答:
数据进入 datahub 的时间?
有system-time 这个 meta 字段
TIMESTAMP METADATA VIRTUAL
系统时间。可以用 current_timestamp,取 Flink 系统时间。数据写入 Hologres 的时间?这个可以暂时没有 meta 可以获取。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/568290
