前言
人类获取的信息83%来自视觉,图文多模态大模型能感知更丰富和精确的真实世界信
息,构建更全面的认知智能,从而向AGI(通用人工智能)迈出更大步伐。
元象今日发布多模态大模型XVERSE-V,支持任意宽高比图像输入,在主流评测中效
果领先。该模型全开源,无条件免费商用,持续推动海量中小企业、研究者和开发者
的研发和应用创新。

XVERSE-V 性能优异,在多项权威多模态评测中超过零一万物Yi-VL-34B、面壁智能OmniLMM-12B及深度求索DeepSeek-VL-7B等开源模型,在综合能力测评MMBench中超过了谷歌GeminiProVision、阿里Qwen-VL-Plus和Claude-3V Sonnet等知名闭源模型。

图. 多模态大模型综合评测
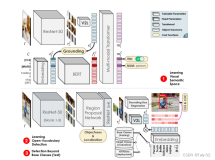
融合整体和局部的高清图像表示
传统的多模态模型的图像表示只有整体,XVERSE-V 创新性地采用了融合整体和局部的策略,支持输入任意宽高比的图像。兼顾全局的概览信息和局部的细节信息,能够识别和分析图像中的细微特征,看的更清楚,理解的更准确。


注:Concate* 表示按列进行拼接
这样的处理方式使模型可以应用于广泛的领域,包括全景图识别、卫星图像、古文物扫描分析等。
示例- 高清全景图识别 、图片细节文字识别


模型效果
免费下载大模型
Hugging Face:
https://huggingface.co/xverse/XVERSE-V-13B
ModelScope魔搭:
https://modelscope.cn/models/xverse/XVERSE-V-13B
Github:
https://github.com/xverse-ai/XVERSE-V-13B
元象持续打造国内开源标杆,在 国内最早开源最大参数65B 、 全球最早开源最长上下文256K 以及 国际前沿的MoE模型 , 并在 SuperCLUE测评全国领跑 。此次推出MoE模型, 填补 国产开源空白,更将其 推向了国际领先水平。
商业应用上,元象大模型是 广东最早获得国家备案的模型之一 ,可向全社会提供服务。元象大模型去年起已和多个腾讯产品,包括 QQ音乐 、虎牙直播、全民K歌、腾讯云等,进行深度合作与应用探索,为文化、娱乐、旅游、金融领域打造创新领先的用户体验。

多方向实际应用表现突出
模型不仅在基础能力上表现出色,在实际的应用场景中也有着出色的表现。具备不同场景下的理解能力,能够处理信息图、文献、现实场景、数理题目、科学文献、代码转化等不同需求。
图表理解
不论是复杂图文结合的信息图理解,还是单一图表的分析与计算,模型都能够自如应对。


视障真实场景
在真实视障场景测试集VizWiz中,XVERSE-V 表现出色,超过了InternVL-Chat-V1.5、DeepSeek-VL-7B 等几乎所有主流的开源多模态大模型。该测试集包含了来自真实视障用户提出的超过31,000个视觉问答,能准确反映用户的真实需求与琐碎细小的问题,帮助视障人群克服他们日常真实的视觉挑战。

VizWiz测试示例
看图内容创作
XVERSE-V 具备多模态能力的同时保持强大的文本生成能力,能够很好胜任理解图像后创造性文本生成的任务。

教育解题
模型具备了广泛的知识储备和逻辑推理能力,能够识别图像解答不同学科的问题。

百科解答
模型储备了历史、文化、科技、安全等各类主题的知识。

代码撰写

自动驾驶

情感理解与识别
![218635c5-ef47-4766-bded-f7e0307ea4d3[1].png](https://ucc.alicdn.com/pic/developer-ecology/umvm3uqpbgldm_15380b1d01914c359ec3064f8d0e52dd.png "218635c5-ef47-4766-bded-f7e0307ea4d3[1].png")
点击即可跳转模型链接
XVERSE-V-13B · 模型库 (modelscope.cn)