问题一:DataWorks中mysql整库同步到holo,源表Procedure字段?
DataWorks中mysql整库同步到holo,源表Procedure字段?
参考回答:
在DataWorks中,如果你尝试从MySQL整库同步数据到Hologres(Holo),并且源表包含PROCEDURE字段,可能会遇到一些问题。这是因为PROCEDURE是一个特殊的数据类型,在某些数据库系统中用于存储存储过程的定义。
在将这样的表进行同步时,需要注意以下几点:
- 兼容性:
首先,确保目标数据库Hologres支持这种类型的字段。如果Hologres不支持存储过程或者与之等价的功能,你可能需要寻找替代方案或对数据结构进行调整。 - 转换和映射:
如果Hologres可以接受某种等效的数据类型来存储这些信息,你可能需要在同步过程中执行一个数据转换步骤,将PROCEDURE字段的内容转换为Hologres支持的格式。 - 保留或忽略:
根据你的需求,你可以选择是否需要将PROCEDURE字段的数据同步到Hologres。如果不重要的话,可以在同步任务配置中将其忽略。 - 自定义脚本:
如果内置的同步工具无法处理这种特殊情况,你可能需要编写自定义的脚本来迁移这些特殊的字段。这通常涉及查询源数据库并将结果写入目标数据库的过程。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/573637
问题二:DataWorks迁移助手导出时,设计到的表只能导出当前导出用户创建的表 这个可以解决么?
DataWorks迁移助手导出时,设计到的表只能导出当前导出用户创建的表 这个可以解决么?
参考回答:
创建导出包的时候可以过滤 
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/573636
问题三:DataWorks数据建模-数据指标,原子指标的度量,需要加修饰词作为特殊度量的场景怎么处理?
DataWorks数据建模-数据指标,原子指标的度量,需要加修饰词作为特殊度量的场景怎么处理?
参考回答:
在 DataWorks 数据建模中,原子指标是一种不可再细分的度量,它通常由业务过程和度量组成。例如,“支付金额”就是一个典型的原子指标,其中“支付”是业务过程,“金额”是度量。
当需要添加修饰词作为特殊度量的场景时,可以考虑以下处理方式:
- 创建派生指标:
- 对于具有修饰词的度量,可以将其视为一个派生指标。
- 通过定义公式或使用脚本来计算这些特殊的度量,并将结果存储为新的数据表或视图。
- 这样可以在保持原子指标清晰的同时,允许对数据进行更复杂的分析。
- 使用标签或维度:
- 如果修饰词代表了某种属性或分类,可以考虑使用标签或维度来表示。
- 在原子指标的基础上,增加额外的列来记录这些属性或分类信息。
- 这样可以方便地按照不同的维度进行筛选、分组和聚合。
- 扩展原子指标的定义:
- 如果修饰词对于理解和解释指标非常重要,可以考虑在原子指标的命名中包含这些修饰词。
- 比如,在“订单金额”这个原子指标中,如果有一个特例是“已退款订单金额”,那么可以将这个特殊度量命名为“已退款订单金额”。
- 文档和注释:
- 如果修饰词仅仅是为了提供额外的上下文信息,而不会影响指标的实际值,那么可以通过文档或者注释来描述这些信息。
- 这种方法适用于那些不常用但又需要保留的特殊情况。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/573632
问题四:DataWorks跑数据集成,但是为啥没生效,实际数据量远比1m大?
DataWorks跑数据集成,从polar到odps,设置了限流,speed=[{"throttle":true,"concurrent":2,"mbps":"1 
"}]。但是为啥没生效,实际数据量远比1m大?
参考回答:
这里的限流是相对的哈 ,比如 设置了限流2m,实际运行时 前4s都是是0m 第5s是5m 平均下来后流速还是小于2
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/573631
问题五:DataWorks mongo中的array类型写入mc中的string, 为什么格式不是json?
DataWorks mongo中的array类型写入mc中的string, 为什么格式不是json? 格式很奇怪? 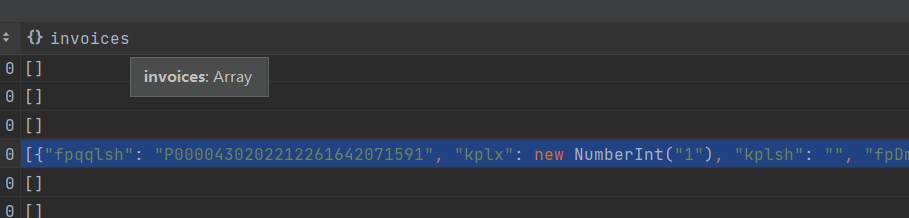

参考回答:
这个是符合预期的哈
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/573626
