作为一名专注于大数据存储与处理技术的博主,我深知Hadoop Distributed File System(HDFS)作为一款广泛应用的分布式文件系统,在大数据生态系统中的基石地位。本篇博客将结合我个人的面试经历,深入剖析HDFS的底层原理、关键特性及其故障排查方法,分享面试必备知识点,并通过示例进一步加深理解,助您在求职过程中自信应对与HDFS相关的技术考察。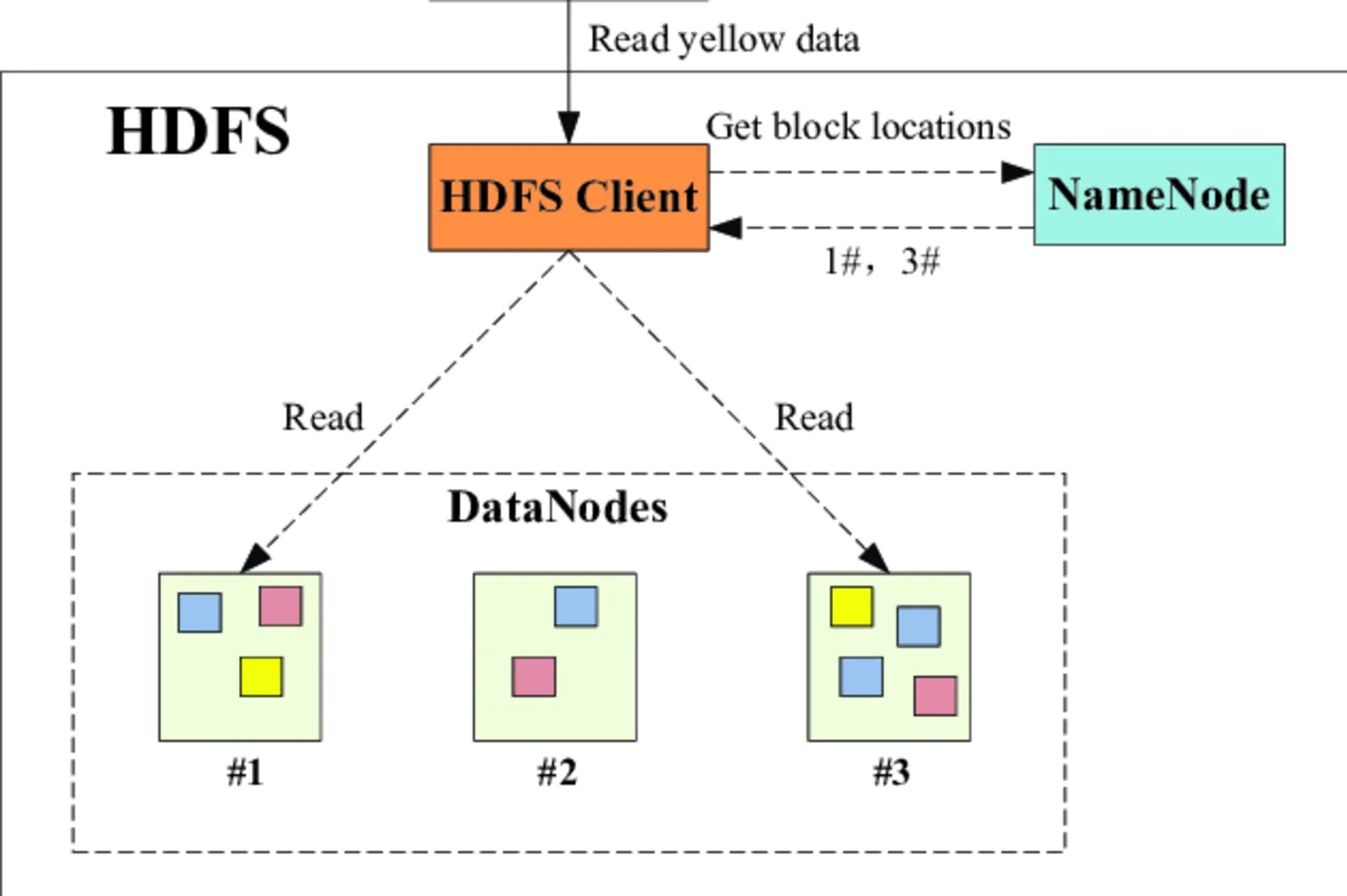
一、面试经验分享
在与HDFS相关的面试中,我发现以下几个主题是面试官最常关注的:
HDFS架构与工作原理:能否清晰描述HDFS的架构组成,包括NameNode、DataNode、Secondary NameNode或HA NameNode等组件?如何理解HDFS的文件块管理、副本放置策略、读写流程?
HDFS高级特性:能否解释HDFS的快照、Erasure Coding、HDFS Federation、HDFS High Availability等特性的工作原理与应用场景?
HDFS故障排查:如何定位并解决HDFS常见的读写错误、数据丢失、NameNode故障等问题?如何利用HDFS Shell命令、Hadoop Metrics、日志分析等工具进行故障排查?
HDFS与其他分布式文件系统对比:能否对比分析HDFS与GlusterFS、Ceph、Amazon S3等文件系统的优缺点?在何种场景下更倾向于选择HDFS?
二、面试必备知识点详解
HDFS架构与工作原理
HDFS采用Master-Slave架构,主要组件包括:- NameNode:管理文件系统命名空间,维护文件与Block映射关系,处理客户端的元数据操作请求。
- DataNode:存储实际数据块,执行来自NameNode的Block创建、删除、复制等指令,响应客户端的读写请求。
- Secondary NameNode(或HA NameNode):定期合并EditLog与FsImage,辅助NameNode进行checkpoint,或在HA模式下提供NameNode故障切换。
文件读写流程如下:
写入:客户端向NameNode申请写入文件,NameNode返回文件Block列表及对应DataNode地址。客户端将数据按Block写入DataNode,DataNode完成写入后向NameNode报告Block完成。
读取:客户端向NameNode请求文件Block列表及对应DataNode地址。客户端直接从DataNode读取数据。
# HDFS Shell命令示例
hdfs dfs -mkdir /data
hdfs dfs -put local_file /data/
hdfs dfs -ls /data/
hdfs dfs -get /data/local_file local_copy
HDFS高级特性
HDFS提供了多项高级特性以增强其可用性、可靠性与性能:- 快照:创建某一时刻文件系统的只读副本,用于备份、恢复、版本控制等。
- Erasure Coding:使用编码算法替代传统的三副本策略,提高存储效率,保证数据容错。
- HDFS Federation:支持多个NameService,实现命名空间水平扩展。
- HDFS High Availability:通过Active-Standby NameNode、JournalNode等机制,确保NameNode服务高可用。
HDFS故障排查
排查HDFS问题,可遵循以下步骤:定位问题:通过客户端错误信息、HDFS Shell命令、Hadoop Metrics、NameNode与DataNode日志等途径,确定问题类型(如读写错误、数据丢失、NameNode故障等)。
分析原因:根据问题类型,结合HDFS工作原理、配置参数、系统状态等信息,分析可能的原因。
解决问题:采取针对性措施修复问题,如修复硬件故障、调整配置参数、重启服务、恢复数据等。对于复杂问题,可能需要结合社区文档、源码分析等手段。
HDFS与其他分布式文件系统对比
HDFS相比其他分布式文件系统(如GlusterFS、Ceph、Amazon S3),优势在于:- 大数据处理:针对大规模数据集设计,提供高吞吐量、大文件支持。
- Hadoop生态集成:与Hadoop MapReduce、YARN、Hive、Spark等组件无缝集成,构成完整的大数据处理平台。
- 社区活跃:作为开源项目,拥有庞大用户群体与活跃开发者社区,持续更新迭代。
但在某些场景下,如需要支持小文件、低延迟访问、跨云存储等需求,可能需要考虑使用GlusterFS、Ceph、Amazon S3等文件系统。
结语
深入理解HDFS分布式文件系统的原理、特性及其故障排查方法,不仅有助于在面试中展现扎实的技术功底,更能为实际工作中构建、管理和维护大规模数据存储系统提供有力保障。希望本文的内容能帮助您系统梳理HDFS相关知识,从容应对各类面试挑战。
