技术解读
近期,HPC-AI Tech团队在GitHub上正式公开了Open-Sora项目(https://github.com/hpcaitech/Open-Sora),该项目致力于复现OpenAI的Sora模型核心技术,并已取得实质性进展。作为开源社区内的开创性工作,Open-Sora率先提供了全球首个类Sora视频生成方案。魔搭社区也迅速跟进并深入学习了这一研究成果,以期促进技术交流与应用落地。
Open-Sora的工作主要分为如下几个部分:
1、变分自编码器(VAE)
为了降低计算成本,Open-Sora使用VAE名将视频从原始像素空间映射至潜在空间(latent space)。Sora的技术报告中,采用了时空VAE来减少时间维度,Open-Sora项目组通过研究和实践,发现目前尚无开源的高品质时空VAE(3D-VAE)模型。Google研究项目的MAGVIT所使用的4x4x4 VAE并未开放源代码,而VideoGPT的2x4x4 VAE在实验中表现出较低的质量。因此,在Open-Sora v1版本中,使用来自Stability-AI的2D VAE(sd-vae-ft-mse)。
2、Diffusion Transformers - STDiT
在处理视频训练时,涉及到大量token。对于每分钟24帧的视频,共有1440帧。经过VAE 4倍下采样和patch尺寸2倍下采样后,大约得到1440x1024≈150万token。对这150万个token进行全注意力操作会导致巨大的计算开销。因此,Open-Sora项目借鉴Latte项目,采用时空注意力机制来降低成本。
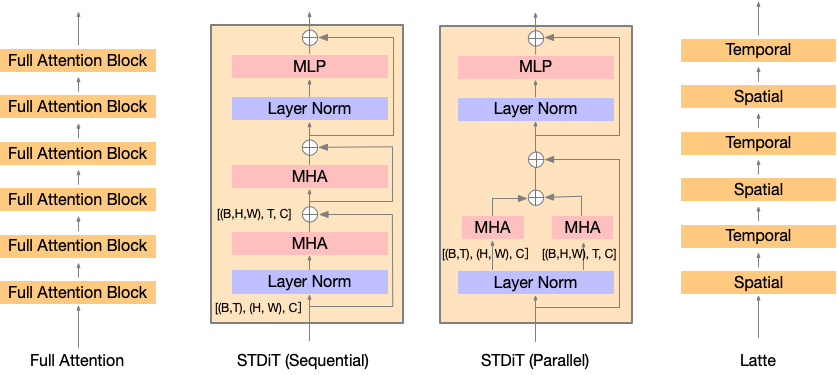
如图所示,在STDiT(空间-时间)架构中每个空间注意力模块之后插入一个时间注意力模块。这一设计与Latte论文中的变体3相似,但在参数数量上未做严格控制。Open-Sora在16x256x256分辨率视频上的实验表明,在相同迭代次数下,性能排序为:DiT(全注意力)> STDiT(顺序执行)> STDiT(并行执行)≈ Latte。出于效率考虑,Open-Sora本次选择了STDiT(顺序执行)。
Open-Sora专注视频生成任务,在PixArt-α一个强大的图像生成模型基础上训练模型。这项研究,采用了T5-conditioned DiT结构。Open-Sora以PixArt-α为基础初始化模型,并将插入的时间注意力层初始化为零值。这样的初始化方式确保了模型从一开始就能保持图像生成能力,文本编码器采用的则是T5模型。插入的时间注意力层使得参数量从5.8亿增加到了7.24亿。
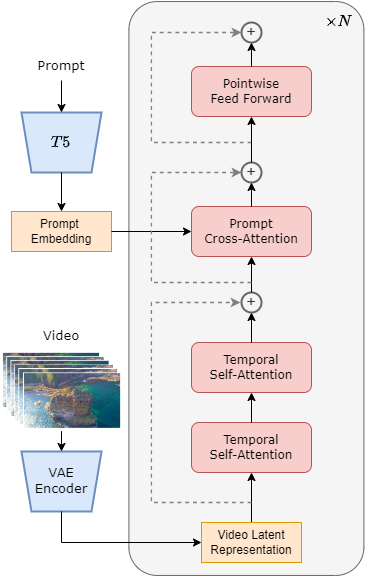
受PixArt-α和稳定视频扩散技术成功的启发,Open-Sora采取了逐步训练策略:首先在36.6万预训练数据集上以16x256x256分辨率训练,然后在2万数据集上分别以16x256x256、16x512x512以及64x512x512分辨率继续训练。借助缩放position embedding,显著降低了计算成本。
3、Patch Embedding
Open-Sora尝试在DiT中使用三维patch embedding,但由于在时间维度上进行2倍下采样,生成的视频质量较低。因此,在下一版本中,Open-Sora把下采样的任务留给时空VAE,在V1中按照每3帧采样(16帧训练)和每2帧采样(64帧训练)的方式进行训练。
4、Video caption
Open-Sora使用LLaVA-1.6-Yi-34B(一款图像描述生成模型)为视频进行标注,该标注基于三个连续的帧以及一个精心设计的提示语。借助这个精心设计的提示语,LLaVA能够生成高质量的视频描述。

总结来说,Open-Sora项目V1版本非常完整的复刻了基于Transformers的视频生成的Pipeline:
- 比较多种STDiT的方式,采用了STDiT(顺序执行),并验证了结果
- 借助position embedding,实现了不同分辨率和不同时长的视频生成。
在试验的过程中也遇到了一些困难,比如我们注意到,
- Open-Sora项目一开始采用的是VideoGPT的时空VAE,验证效果不佳后,依然选择了Stable Diffusion的2D的VAE。
- 同时,三维patch embedding,由于在时间维度上进行2倍下采样,生成的视频质量较低。在V1版本中依然采用了按帧采样的方式。
Open-Sora也借助了开源项目和模型的力量,包括但不限于:
- LLaVA-1.6-Yi-34B的多模态LLM来实现Video-Caption,生成高质量的视频文本对。
- 受PixArt-α和稳定视频扩散技术成功的启发,采用了T5 conditioned DiT结构。
Open-Sora项目通过其强大的工程能力,快速的搭建和验证了Sora的技术链路,推动了开源视频生成的发展,同时我们也期待V2版本中,对时空VAE等难题的进一步解决。
魔搭最佳实践
第一步:下载代码并安装:
# install flash attention (optional) pip install packaging ninja pip install flash-attn --no-build-isolation # install apex (optional) pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" git+https://github.com/NVIDIA/apex.git # install xformers pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu121 git clone https://github.com/hpcaitech/Open-Sora cd Open-Sora pip install -v .
第二步:下载模型并放到对应的文件夹
cd Open-Sora/opensora/models # 下载VAE模型 git clone https://www.modelscope.cn/AI-ModelScope/sd-vae-ft-ema.git # 下载ST-dit模型 git clone https://www.modelscope.cn/AI-ModelScope/Open-Sora.git # 下载text-encoder模型 cd text-encoder git clone https://www.modelscope.cn/AI-ModelScope/t5-v1_1-xxl.git
第三步:修改config文件/mnt/workspace/Open-Sora/configs/opensora/inference/16x256x256.py
num_frames = 16 fps = 24 // 3 image_size = (256, 256) # Define model model = dict( type="STDiT-XL/2", space_scale=0.5, time_scale=1.0, enable_flashattn=True, enable_layernorm_kernel=True, from_pretrained="/mnt/workspace/Open-Sora/opensora/models/stdit/OpenSora-v1-HQ-16x256x256.pth", ) vae = dict( type="VideoAutoencoderKL", from_pretrained="/mnt/workspace/Open-Sora/opensora/models/sd-vae-ft-ema", ) text_encoder = dict( type="t5", from_pretrained="/mnt/workspace/Open-Sora/opensora/models/text_encoder", model_max_length=120, ) scheduler = dict( type="iddpm", num_sampling_steps=100, cfg_scale=7.0, ) dtype = "fp16" # Others batch_size = 2 seed = 42 prompt_path = "./assets/texts/t2v_samples.txt" save_dir = "./outputs/samples/"
运行推理代码:
torchrun --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x256x256.py
显存峰值约30G,值得一提的,大部分的显存使用是t5-v1_1-xxl,我们切换成t5-v1_1-large,会报conditioned tensor shape不对,后续魔搭社区也会继续尝试切换,目标是可以让开发者在一张消费级显卡上使用。
使用官方提供的prompt的生成效果:

prompt:A serene underwater scene featuring a sea turtle swimming through a coral reef. The turtle, with its greenish-brown shell, is the main focus of the video, swimming gracefully towards the right side of the frame. The coral reef, teeming with life, is visible in the background, providing a vibrant and colorful backdrop to the turtle's journey. Several small fish, darting around the turtle, add a sense of movement and dynamism to the scene. The video is shot from a slightly elevated angle, providing a comprehensive view of the turtle's surroundings. The overall style of the video is calm and peaceful, capturing the beauty and tranquility of the underwater world.

prompt:The dynamic movement of tall, wispy grasses swaying in the wind. The sky above is filled with clouds, creating a dramatic backdrop. The sunlight pierces through the clouds, casting a warm glow on the scene. The grasses are a mix of green and brown, indicating a change in seasons. The overall style of the video is naturalistic, capturing the beauty of the landscape in a realistic manner. The focus is on the grasses and their movement, with the sky serving as a secondary element. The video does not contain any human or animal elements.
 00_00_00-00_00_30.gif")
prompt:A serene night scene in a forested area. The first frame shows a tranquil lake reflecting the star-filled sky above. The second frame reveals a beautiful sunset, casting a warm glow over the landscape. The third frame showcases the night sky, filled with stars and a vibrant Milky Way galaxy. The video is a time-lapse, capturing the transition from day to night, with the lake and forest serving as a constant backdrop. The style of the video is naturalistic, emphasizing the beauty of the night sky and the peacefulness of the forest.
 00_00_00-00_00_30.gif")
prompt:The Grandeur of a Venetian Canal at Twilight.As evening descends upon Venice, the Grand Canal shimmers with the reflections of historic palazzos and gently bobbing gondolas. The fading light turns the water to liquid gold, while the sky transitions from a soft lavender to the deep blue of the coming night. Lanterns begin to glow from wrought iron posts, casting a warm light on the faces of lovers walking hand in hand along the cobblestone paths. The gentle lapping of the water against the stone walls of the canal carries the soft melodies of a distant accordion, evoking a timeless romance only Venice can offer.
 00_00_00-00_00_30.gif")
prompt:A Rustic Vineyard at Harvest Time.Nestled in the rolling hills of the countryside, the vineyard is a patchwork of vines laden with clusters of ripe, plump grapes. Workers move between the rows, baskets in hand, as they gather the fruits of their labor under the autumn sun. The vines are a cascade of golden leaves, ready to fall at the slightest touch. In the distance, a stone farmhouse rests, its walls aged by time, with smoke rising from the chimney into the clear blue sky. The air is filled with the sweet scent of grapes and the earthy aroma of the soil, inviting a sense of home and the promise of a bountiful harvest.
64帧
脚本换为/configs/opensora/inference/64x512x512.py
注意修改模型为OpenSora-v1-HQ-16x512x512.pth
推理时显存占用约44G
保存视频时占用更高,约60G

以上同样的prompt的生成效果:
 00_00_00-00_00_30.gif")
prompt:A serene underwater scene featuring a sea turtle swimming through a coral reef. The turtle, with its greenish-brown shell, is the main focus of the video, swimming gracefully towards the right side of the frame. The coral reef, teeming with life, is visible in the background, providing a vibrant and colorful backdrop to the turtle's journey. Several small fish, darting around the turtle, add a sense of movement and dynamism to the scene. The video is shot from a slightly elevated angle, providing a comprehensive view of the turtle's surroundings. The overall style of the video is calm and peaceful, capturing the beauty and tranquility of the underwater world.
 00_00_00-00_00_30.gif")
prompt:The dynamic movement of tall, wispy grasses swaying in the wind. The sky above is filled with clouds, creating a dramatic backdrop. The sunlight pierces through the clouds, casting a warm glow on the scene. The grasses are a mix of green and brown, indicating a change in seasons. The overall style of the video is naturalistic, capturing the beauty of the landscape in a realistic manner. The focus is on the grasses and their movement, with the sky serving as a secondary element. The video does not contain any human or animal elements.
 00_00_00-00_00_30.gif")
prompt:A serene night scene in a forested area. The first frame shows a tranquil lake reflecting the star-filled sky above. The second frame reveals a beautiful sunset, casting a warm glow over the landscape. The third frame showcases the night sky, filled with stars and a vibrant Milky Way galaxy. The video is a time-lapse, capturing the transition from day to night, with the lake and forest serving as a constant backdrop. The style of the video is naturalistic, emphasizing the beauty of the night sky and the peacefulness of the forest.
点击直达Open-Sora开源链接:
GitHub - hpcaitech/Open-Sora: Open-Sora: Democratizing Efficient Video Production for All


