在TiDB分布式数据库中,PD(Placement Driver)调度器扮演着至关重要的角色。作为集群的“大脑”,PD调度器不仅管理着全局的元数据,还负责调度资源、均衡负载以及处理各种异常情况,确保整个集群的稳定运行。
一、PD调度器的基本架构
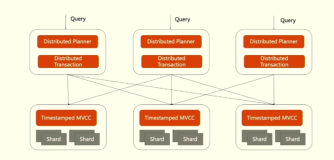
PD调度器采用分布式架构,由多个节点组成,这些节点通过Raft协议保证数据的一致性和高可用性。每个PD节点都维护着集群的元数据信息,并通过定期的心跳检测和数据同步,确保集群状态的一致性。此外,PD调度器还提供了丰富的API接口,供外部系统查询集群状态、管理集群资源等。
二、PD调度器的功能特点
全局元数据管理:PD调度器负责维护集群的全局元数据,包括表结构、索引、分区等信息。这些元数据是数据库操作的基础,通过PD调度器的管理,可以确保元数据的准确性和一致性。
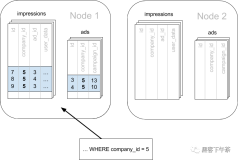
负载均衡:PD调度器根据集群的实时负载情况,自动调整数据的分布和节点的负载,以实现负载均衡。通过合理的调度策略,可以避免某些节点过载或空闲,提高整个集群的性能和稳定性。
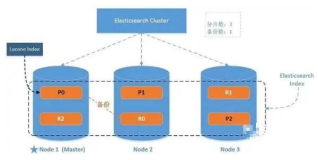
自动容灾恢复:当集群中出现节点故障或数据丢失时,PD调度器能够自动检测并触发容灾恢复机制。通过复制数据、迁移任务等操作,确保数据的完整性和业务的连续性。
智能调度策略:PD调度器内置了多种智能调度策略,可以根据不同的业务场景和需求,自动选择最优的调度方案。这些策略包括但不限于基于负载的调度、基于成本的调度以及基于优先级的调度等。
三、PD调度器的使用场景
PD调度器广泛应用于各种需要高可用性、高性能和弹性伸缩的数据库场景中。无论是大规模的在线事务处理(OLTP)场景,还是复杂的在线分析处理(OLAP)场景,PD调度器都能够发挥其独特的优势,帮助用户构建稳定、高效的分布式数据库集群。
总结:
PD调度器作为TiDB分布式数据库的核心组件,在全局元数据管理、负载均衡和自动容灾恢复等方面发挥着重要作用。通过深入理解PD调度器的工作原理和使用方法,用户可以更好地管理和优化TiDB集群,确保数据库的稳定运行和高效性能。随着技术的不断发展,未来PD调度器还将继续优化和完善,为TiDB用户提供更加卓越的数据库服务。