
问题一:Flink CDC现在支持从oracle备库同步数据吗?
Flink CDC现在支持从oracle备库同步数据吗?
参考答案:
备库不支持的要主库
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/538438?spm=a2c6h.13066369.question.46.2ac075ebuZMEog
问题二:Flink CDC中为oracle cdc 指定chunkcloum 全量阶段数据更新增量无法同步?
Flink CDC中oracle cdc 指定chunkcloum 全量阶段如果发生数据更新的话后边增量就同步不到,如果默认用rowid就没问题,怎么解决?
参考答案:
在 Flink CDC 的 Oracle CDC 连接器中,当在全量阶段指定了 chunkcloum(也称为split_column)时,如果该列在全量阶段发生了数据更新,可能会导致后续增量阶段无法正确同步更新的数据。
这是因为在全量阶段,Oracle CDC 连接器会按照 chunkcloum 列进行数据切分,并使用切分后的范围进行数据抓取。如果在全量阶段,chunkcloum 列的数据发生了更新,那么在后续的增量阶段,这些更新的数据将无法被正确地捕获和同步。
为了解决这个问题,你可以考虑以下两种方法:
使用 rowid 作为 chunkcloum 列:你已经提到使用 rowid 作为 chunkcloum 列没有问题,因为 rowid 是一个内置的唯一标识符,不会发生数据更新。如果使用 rowid 作为 chunkcloum 列,可以确保在全量阶段发生数据更新时,后续的增量阶段仍然能够正确捕获和同步。
调整全量和增量阶段的策略:你可以考虑将全量和增量阶段的策略进行调整,以解决数据更新导致的同步问题。例如,可以在全量阶段使用 rowid 作为 chunkcloum 列进行切分,确保全量数据的完整性。然后,在增量阶段使用其他方法(如主键、时间戳等)来捕获和同步变更数据。这样可以避免全量阶段数据更新导致的同步问题。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/541235?spm=a2c6h.13066369.question.49.2ac075ebZodu8k
问题三:请教一下大佬们Flink CDC oraclecdc中的数据同步到clickhouse中时间字段的?
请教一下大佬们Flink CDC oraclecdc中的数据同步到clickhouse中时间字段的数据多了八个小时 这个是什么原因?
参考答案:
cdc采集到的datetime类型数据是会转成bigint的时间戳的,如果用的datastream API需要自己写convertor,如果用的sql就得设置 timezone 
你去搜一下咋写convertor转换cdc的时间戳
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/538382?spm=a2c6h.13066369.question.48.2ac075ebgW6LC1
问题四:Flink CDC中我想用cdc同步新增的数据但是在测试的时为什么写入到目标库的时候数据减少了很多?
Flink CDC中我想用cdc同步新增的数据,更新和删除的不管, 但是在测试的时候发现,写入到目标库的时候数据减少了很多 ,有知道可能是什么原因的吗?
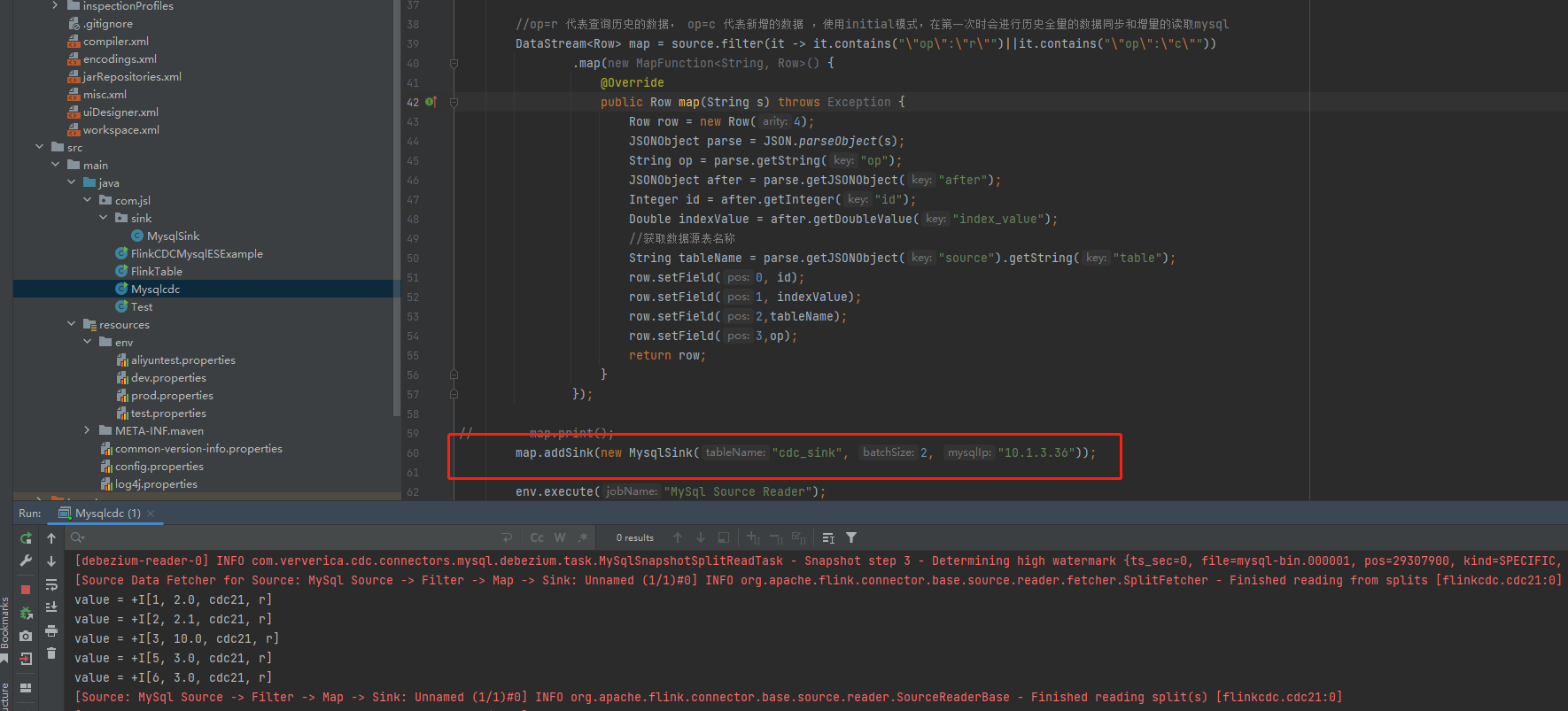
没对数据做任何出处理, 就是 source - filter - sink。
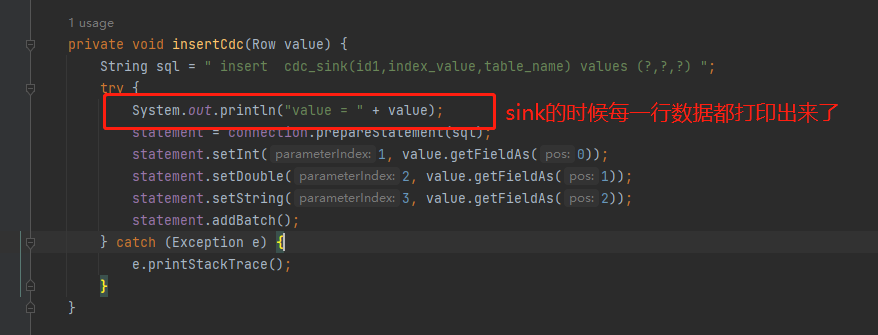
参考答案:
这可能是由于 Flink CDC 的同步策略导致的。Flink CDC 是基于时间戳进行同步的,如果目标表中的数据没有按照时间戳排序,那么 Flink CDC 就无法正确地识别新增、更新和删除的数据。可以尝试在目标表中创建一个时间戳列,并将其设置为自动递增,然后将该列作为主键。这样,Flink CDC 就可以根据时间戳来识别新增、更新和删除的数据了。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/535310?spm=a2c6h.13066369.question.51.2ac075ebXcUL30
问题五:flink cdc 同步 mongo 的数据到hudi,大概2亿多条数据,目前发现同步历史数据的时?
flink cdc 同步 mongo 的数据到hudi,大概2亿多条数据,目前发现同步历史数据的时候,状态特别大,都100G+了,比source端接收的数据量还大,而且我还做了按天分区的。有人知道啥原因吗?
参考答案:
有个changelogNormalize节点,应该是这个节点占用state比较大,mongo是什么版本?高版本的mongo有优化可能,低版本原理上需要这个节点,
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/522287?spm=a2c6h.13066369.question.52.2ac075ebYDMHKK


