
视觉语言预训练如CLIP已经在各种下游任务上展现出良好的性能,如零样本图像分类和图像文本检索。现有的CLIP类似的论文通常采用相对较大的图像编码器,如ResNet50和ViT,而轻量级的对应物很少被讨论。在本文中,作者提出了一种多级交互范式来训练轻量级CLIP模型。
- 首先,为了减轻一些图像文本对不是严格的一一对应关系的问题,作者通过逐步软化负样本标签来改进传统的全局实例级对齐目标。
- 其次,作者引入了一个松弛的二分匹配基于 Token 级对齐目标,以实现图像块与文本词之间的更精细的对应。
- 此外,作者观察到CLIP模型的准确性并不会随着文本编码器参数的增加而相应提高,因此作者利用掩码语言建模(MLM)的额外目标来最大化缩短文本编码器的潜力。
在实践中,作者提出了一种辅助融合模块,在网络的不同阶段将未遮蔽图像嵌入注入到遮蔽文本嵌入中,以增强MLM。大量的实验表明,在不增加推理过程中的额外计算成本的情况下,所提出的方法在多个下游任务上实现了更高的性能。
1 Introduction
近年来,视觉语言预训练(VLP)在多个下游任务上表现出卓越的性能,如零样本分类、图像文本检索和图像描述。成功可以归因于几个因素:从网页爬取的大规模图像文本对,良好设计的模型架构和适当的预训练目标。一般来说,现有的VLP模型可以大致分为单流和双流两种范式。单流模型通常构建图像文本融合模块来模拟图像块与文本词之间的精细交互。尽管它们在某些任务上实现了有前景的表现,但冗余组件设计和昂贵的计算成本限制了它们的更广泛应用。
相比之下,双流模型解耦了图像和文本的编码器,分别提取图像和文本的嵌入。像CLIP和ALIGN这样的代表性双流模型在大型网页爬取图像文本对上进行全局对比学习,在多个下游任务上实现了惊人的性能。
由于其简单性和惊人的准确性,双流范式在多模态领域最近占据主导地位。然而,现有的VLP模型由于其庞大的参数,难以在边缘设备上部署。例如,大多数现有的CLIP类似工作通常采用ResNet50和ViT作为图像编码器,而轻量级对应物很少被讨论。文本编码器主要由12个Transformer块组成,具有沉重的参数。因此,在可承受的计算资源下探索配备轻量级图像和文本编码器的CLIP类似模型是一个开放的问题。
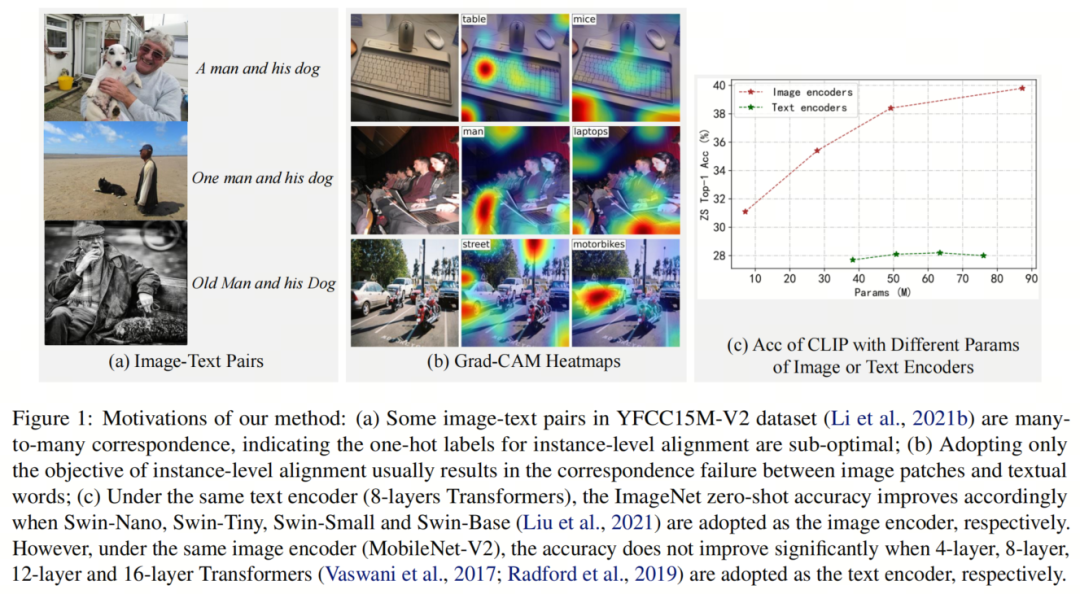
很不幸的是,直接将现有方法应用在训练轻量级CLIP模型上通常会得到次优的结果。受大小限制的图像和文本编码器在学习用于对齐图像和文本的丰富表示方面具有更大的困难。首先,一些从网页爬取的图像文本对不是严格的一一对应(图1.(a)),这对在单一热编码下预训练的轻量级CLIP模型更为有害。此外,仅采用全局实例级对齐是有效的但不够充分。例如,MobileNet-V2图像编码器的Grad-CAM Heatmap 表明图像块与文本词之间通常存在不匹配,通常导致更低的准确性。最后,与轻量级图像和文本编码器之间的相互忽视相比,适当地融合图像和文本的嵌入,即轻量级图像和文本编码器之间的互相帮助,可能有助于提高最终性能。
在本文中,作者提出了LightCLIP,这是一种用于训练轻量级CLIP模型的有效图像-文本对齐和融合范式。为了减轻预训练数据集中一些从网页爬取的图像文本对不是严格的一一对应的问题,作者首先通过逐步软化负样本标签来改进传统的全局实例级对齐目标。考虑到轻量级图像和文本编码器的有限表示能力,作者然后设计了一个松弛的二分匹配基于 Token 级对齐目标,以实现图像块与文本词之间的更精细的对应。
具体来说,作者将 Token 级对齐问题视为一个直接的一对一预测问题,其中可以使用二分匹配算法(如Hungarian)有效地计算最优的一对一对应关系。最后,根据观察到CLIP模型的性能不会随着文本编码器参数的增加而相应提高(图1.(c)),作者减少了文本编码器的层数,并利用掩码语言建模(MLM)的目标来帮助预训练。在实践中,作者提出了一种辅助融合模块,在网络的不同阶段将未遮蔽图像嵌入注入到遮蔽文本嵌入中,以增强MLM。
值得注意的是,多级融合模块只在每个训练时间引入,因此,在推理时间保持预计算图像和文本嵌入的能力。在多个基准测试上的广泛实验和彻底的消融研究证明了所提出方法的有效性。
2 Related Work
视觉语言预训练(VLP)通过在大规模图像文本对上学习两个模态之间的表达式联合表示,在各种下游任务上实现了有前景的零样本性能。总的来说,现有的VLP模型可以大致分为两类,即单流和双流。单流范式使用单个深度融合编码器,通过跨模态交互来建模图像和文本的代表性,例如视觉BERT、OSCAR、VILLA、UNIMO和UNITER。
虽然它们在某些任务上实现了有前景的表现,但所有可能的 Query -候选对的跨模态融合过程必然会降低推理速度。此外,为了提取有用的图像区域,通常采用现成的目标检测器,例如Faster R-CNN,这使得该方法的可扩展性较低。相比之下,双流范式分别编码图像和文本,具有解耦的图像和文本编码器,如ViLBERT、CLIP和ALIGN。图像文本对比学习通常用于同时优化图像和文本编码器。
由于其简单性、灵活性和相对较低的计算成本,双流VLP模型目前占据主导地位。以下类似于CLIP的工作如雨后春笋般涌现。为了减轻网页爬取图像文本对中噪声信息的影响,PyramidCLIP、SoftCLIP和CLIP-PSD提出用软化的标签替代对比学习中图像和文本之间的硬一一热编码标签。ALBEF采用动量模型生成额外的伪目标作为监督。
NLIP提出了一种基于噪声和谐和噪声补全的原理噪声稳健框架,以稳定预训练过程。DiHT也从数据集噪声、模型初始化和训练目标方面改进了VLP性能。而不是使用图像和文本全局嵌入之间的常见对比学习,FILIP、COTS和TokenFlow等提出了更精细的 Token 级对齐。然而,大多数先前的作品倾向于相对较大的模型,而更受资源受限设备欢迎的轻量级模型很少被讨论。
3 Method
在本节中,作者首先介绍了LightCLIP的整体架构和目标,然后详细阐述了逐步软化的实例级对齐,通过二分匹配的松弛 Token 级对齐以及多级融合来增强MLM。
Overall Architecture and Objective
LightCLIP的整体架构和目标如图2.(a)所示,其中图像和文本编码器各自分为四个阶段。

作者采用了多个轻量级网络作为图像编码器,包括ResNet18、MobileNet-V2和Swin-Nano。ResNet18、MobileNet-V2和Swin-Nano的参数分别为12.51M、2.45M和7.11M。文本编码器采用了8层Transformer,其架构根据进行了修改。对于没有阶段划分的文本编码器Transformer,作者根据其层数将网络均匀划分为四个阶段。整体目标可以表示为:
其中且。,和分别表示软化实例级对齐的目标,松弛 Token 级对齐的目标和增强MLM的目标,将在下面详细讨论。遵循CLIP,仅在图像和文本的二维输出嵌入处计算。经验上,在第四个网络阶段的三个维嵌入处计算。
Progressive Softened Instance-Level Alignment
重新考虑实例级对齐。对于图像编码器和文本编码器,给定一个图像文本对批,其中表示第对。相应的图像和文本的全局嵌入和分别通过和获得。
为了在将配对的图像文本嵌入拉近的同时将未配对的嵌入推远,广泛采用了InfoNCE来执行L2归一化图像和文本嵌入之间的全局对齐。具体来说,对于第对,通过计算归一化图像到文本的相似度和文本到图像的对偶来完成。
在标准CLIP范式中,使用硬一一热编码标签作为目标来计算InfoNCE。形式上,令表示第对图像文本对的one-hot标签,其中等于1,其他所有值等于0。那么图像到文本和文本到图像的实例损失可以计算为:
其中表示交叉熵函数。全局实例级对齐的最终目标可以通过计算得到。
然而,如图1.(a)所示,一些图像文本对并不是严格的一一对应关系。因此,假设未配对的图像和文本之间绝对没有相似性是错误的。为了减轻这个问题,PyramidCLIP提出了一种标签平滑方法,通过为所有负样本均匀分配较弱权重来降低标签的平滑性。
其中表示软化标签向量,是超参数,表示全1向量。然而,标签平滑忽略了负样本之间的潜在差异。因此,作者提出了一种负样本重要性感知软化策略:
其中表示作者软化的标签向量,
公式7可以根据负样本的相似度分数为不同的负样本分配不同的权重。除了这个方法外,作者还将以上标签统一,并引入了一种逐步软化的方法,以保持训练稳定性和实现更高的准确性。
如图2.(c)所示,随着预训练的进行,计算实例级对齐目标所需的标签从全1的逐渐过渡到软化的,然后过渡到软化的。形式上,在预训练周期中,对比学习中的标签可以表示为:
$\mathbf{y}_{inst}^{i}=\begin{cases}\mathbf{y}_{inst}^{i},&e<r_{1}\times e\\="" \widehat{\mathbf{y}}_{inst}^{i},&r_{1}\times="" e\leq="" e<r_{2}\times="" \widehat{\mathbf{y}}_{inst}^{i},&e\geq="" r_{2}\times="" e\end{cases}="" \tag{9}$<="" p="">
其中表示预训练的总周期,和分别表示预训练周期的比例。具体来说,,且$r_{1}<r_{2}$。< p=""></r_{2}$。<>
Token-Level Alignment via Bipartite Matching
实例级对齐只计算基于全局输出二维嵌入图像和文本之间的相似度分数,即,忽略了图像块和文本词之间的更精细的局部交互(如图1.(b)所示)。
为了增强图像和文本编码器的细粒度代表性能力,需要对图像和文本之间的 Token 级信息进行对齐。有一些工作实现了细粒度的交互,但它们通常引入额外的计算成本,如现成的目标检测器或文本摘要提取器。
为了模拟图像块和文本词之间的局部交互,同时保持效率,作者提出了一种有效的无检测器分治 Token 级对齐目标,通过二分匹配实现。给定两个集合之间的成本矩阵,例如不同工人完成不同任务所需的回报,二分匹配旨在找到工人和任务之间的一一对应关系,使得完成所有任务的总回报最小。
类似地,当将二分匹配应用于两个模态之间的 Token 级对齐问题时,需要解决两个问题,即如何构建对应的两集合和如何定义成本矩阵。对于类似于CLIP的两流范式,图像和文本自然地提供了两个分离的嵌入。此外,公式3中计算的相似度分数可以转移到成本矩阵的计算中。
考虑到移动图像和文本编码器的代表性能力有限,作者只对配对的图像文本进行对齐,忽略未配对的(如图2.(d)所示)。因此,移动图像和文本编码器的学习难度相对降低,迫使它们专注于学习配对图像文本之间的交互。
形式上,与实例级对齐中使用的二维嵌入不同, Token 级对齐基于三维嵌入计算,即,其中分别表示批量大小、 Token 数量和通道。定义和分别为第个图像和第个文本的非填充 Token 数量,相应的嵌入为和。对于第个图像文本对,图像到文本的余弦相似度通过如下方式计算:
可以看到。然后,第个图像到文本的成本矩阵通过如下方式计算:
其中且。此外,第对配对图像文本与最低匹配成本之间的最优一一匹配可以计算为:
其中表示所有的排列集合。成本矩阵中的最小值由的索引给出。Hungarian算法被用来解决方程12。然后,通过以下方式计算 Token 级图像到文本的目标:
确实,文本到图像的 Token 级目标等于图像到文本的 Token 级目标。因此,作者可以直接通过得到 Token 级对齐的最终目标。
值得注意的是,作者的松弛 Token 级对齐只在预训练时引入,因此在预训练时的计算复杂度为,而在推理时的计算复杂度仍为。此外,二分匹配方案实现了一一对应的图像块与文本词,具有最低匹配成本。相反,像FILIP和TokenFlow这样的其他类似无目标 Token 级对齐,常常出现一对一或一对多的对应关系,导致CNN的次优结果和甚至负效果。
Image to Text Fusion for Enhancing MLM
如图1.(c)所示,CLIP模型的准确性并没有随着文本编码器参数的增加而相应增加。因此,作者通过直接减少文本编码器的层数来压缩文本编码器。此外,为了最大限度地利用缩短的文本编码器,作者借鉴了之前工作的成功经验,利用掩码语言建模(MLM)的目标。具体而言,作者首先随机选择每个序列的15%的所有 Token 。
遵循BERT,选择的 Token 随后被替换为10%的随机 Token ,10%的未变 Token ,以及80%的[MASK]。然后,使用相应 Token 的嵌入来预测原始 Token 。如图2.(a)所示,作者的MLM在两个嵌入上分别计算:被遮蔽文本本身的嵌入和未遮蔽图像到被遮蔽文本的多个网络阶段的融合嵌入。
直觉上,借助于来自图像编码器的未遮蔽图像嵌入,缩短文本编码器的学习将更容易和更有效。形式上,与方程10一致,作者用来表示文本编码器第四阶段(以被遮蔽文本为输入)的嵌入。仅使用文本嵌入计算的MLM首先可以表示为:
其中表示第个文本的原始 Token 分布的one-hot分布,表示全连接层用于预测原始 Token 。对于带有未遮蔽图像到被遮蔽文本的嵌入的MLM,经验上,多个网络阶段的融合通常可以实现更高的性能。如图2.(b)所示,以两个网络阶段的融合为例:
其中和分别表示第个网络阶段中被遮蔽文本的嵌入和未遮蔽图像的嵌入。表示卷积操作,将的维度转换为的维度。最后,通过将和相加并除以2来计算完整的增强MLM。值得注意的是,融合模块只在预训练时引入,因此推理效率可以得到保持。
4 Experiments
Experimental Setup
预训练数据集。在实际中,作者采用Cui等人提出的YFCC15M-V2数据集(原始数据集为YFCC100M)作为实验中的预训练图像文本对,该数据集是通过更仔细地从YFCC100M数据集中过滤得出的。
与像CC3M、CC12M、LAION-400M和LAION-5B等公共数据集相比,中等规模的YFCC15M-V2在训练成本和性能之间取得了良好的平衡。在删除无效的下载URL后,作者得到了15,255,632个图像文本对,略少于DeCLIP中的15,388,848对。
实现细节。在实验中,作者设定了超参数,,在方程1中的值为0.8,0.1和0.1,分别对应图像到文本的软化标签对齐、文本到图像的软化标签对齐和增强MLM的目标。在方程9中,和的值为0.33和0.66,分别对应图像到文本和文本到图像的软化标签对齐的权重。在方程7和方程6中,的值为0.2。方程15中的基于第二个和第三个网络阶段中的嵌入计算。为了获得更好的泛化和数据效率,对图像和文本进行了数据增强。
图像按照MOCO和SimCLR的方法进行增强。文本通过随机同义词替换、随机交换和随机删除进行增强。为了节省内存,使用了自动混合精度。此外,输入图像被重新缩放到,文本的最大长度限制为77个 Token 。作者使用AdamW优化器和余弦学习率调度器进行训练。具体而言,权重衰减设置为0.1,学习率线性从0增加到峰值值,即在总迭代次数的5%内增加到5e-4。所有模型均从零开始训练,分别进行了8或32个周期(即8个周期用于消融研究,32个周期用于比较)。此外,作者进行了8次实验。
评估任务。作者在两个下游任务上进行评估:零样本图像分类和零样本图像文本检索。对于零样本图像分类,作者在11个数据集上进行实验,如ImageNet、CIFAR-10、Pets。对于零样本图像文本检索,作者在Flickr30K和MS-COCO上进行实验。
Zero-shot Image Classification
在ImageNet上的零样本图像分类任务上,作者首先使用与表1中相同的预训练数据YFCC15M-V2进行实验。作者将LightCLIP与其他方法,包括CLIP、SLIP和DeCLIP进行比较。其他方法的结果是通过作者的实现获得的。与CLIP基线相比,作者的方法在ResNet18、MobileNet-V2和Swin-Nano图像编码器上分别将Top-1准确率提高了4.2%/3.8%/3.4%。与具有竞争力的DeCLIP方法相比,LightCLIP仍然具有优势。

在其他10个小数据集上的零样本分类结果如下:包括Oxford-IIIT Pets、CIFAR-10、CIFAR-100、Describable Textures、Stanford STL-10、Food-101、Oxford Flowers-102、FER-2013、SUN397和Caltech-101。相应的结果按照顺序在表2中报告。

与CLIP基线相比,作者的LightCLIP在ResNet18、MobileNet-V2和Swin-Nano图像编码器上分别将平均零样本准确率提高了7.1%/6.7%/7.9%。
Zero-shot Image-Text Retrieval
在包括Flickr30K和MS-COCO在内的两个检索基准上评估LightCLIP。零样本检索结果如表3所示。实验结果表明,LightCLIP在不同图像编码器上带来持续改进。

特别是,在Flickr30K上的图像到文本的Top-1命中率改进显著,这可以归因于作者在预训练期间精心设计的对齐目标和网络架构。
Ablation Study
作者基于CLIP基线进行了彻底的消融研究。作者分析了表4中的每个组件,其中表示逐步软化的标签。每个组件的引入都带来了准确率的提高,而完整的LightCLIP在两个网络上都达到了最高的零样本准确率。

Visualization

在图3中,作者使用MobileNet-V2图像编码器通过Grad-CAM Heatmap 来可视化图像块与文本词之间的对应关系。显然,LightCLIP实现了更精确的对应关系,这可以解释LightCLIP在表3中在图像文本检索任务上的显著优势。例如,LightCLIP准确捕获了单词_cake_与图像中的区域之间的对应关系,这对下游任务至关重要。

作者使用Swin-Nano图像编码器通过t-SNE来可视化提取的图像嵌入。如图4所示,LightCLIP实现了相对较好的聚类性能,大多数类别的嵌入更加紧凑且高度区分,从而导致更高的分类准确率。
5 Conclusion
在本文中,作者探索了在可承受的计算资源下移动CLIP模型。在预训练数据集中存在许多到许多的现象,图像块与文本词之间存在失败的对齐,文本编码器参数增加而零样本准确率没有相应增加等问题,这些都激励了所提出的LightCLIP。作者首先通过逐步软化负样本标签改进了传统的全局实例级对齐目标。然后,设计了一个基于松弛二分匹配的 Token 级对齐目标,以实现更精细的对齐。最后,利用多级融合的未遮蔽图像到遮蔽文本的嵌入增强MLM,以最大化缩短文本编码器的潜力。通过大量实验和消融研究,证明了所提出方法的有效性。
参考
[1]. LightCLIP: Learning Multi-Level Interaction for Lightweight Vision-Language Models.
