大数据处理平台的架构演进经历了从批处理到实时流处理的转变,这种转变主要是为了应对越来越多的数据、更快的分析需求和实时决策的要求。以下是从批处理到实时流处理的架构演进过程:
批处理架构:
在大数据处理的早期阶段,批处理架构是主要的架构范式。这种架构中,数据会按照一定的时间间隔或者一定的数据量进行批量处理。数据会被收集、存储,然后在固定的时间间隔内进行处理和分析。典型的批处理框架包括Hadoop MapReduce。
优点:
- 适用于离线数据处理,特别是对历史数据进行分析和挖掘。
- 能够处理大规模的数据,适合大数据分析任务。
- 易于调度和资源管理。
缺点:
- 不能实现实时分析和决策,延迟较高。
- 不适合需要立即响应的业务场景。
- 对于数据变化频繁的场景,批处理难以满足需求。
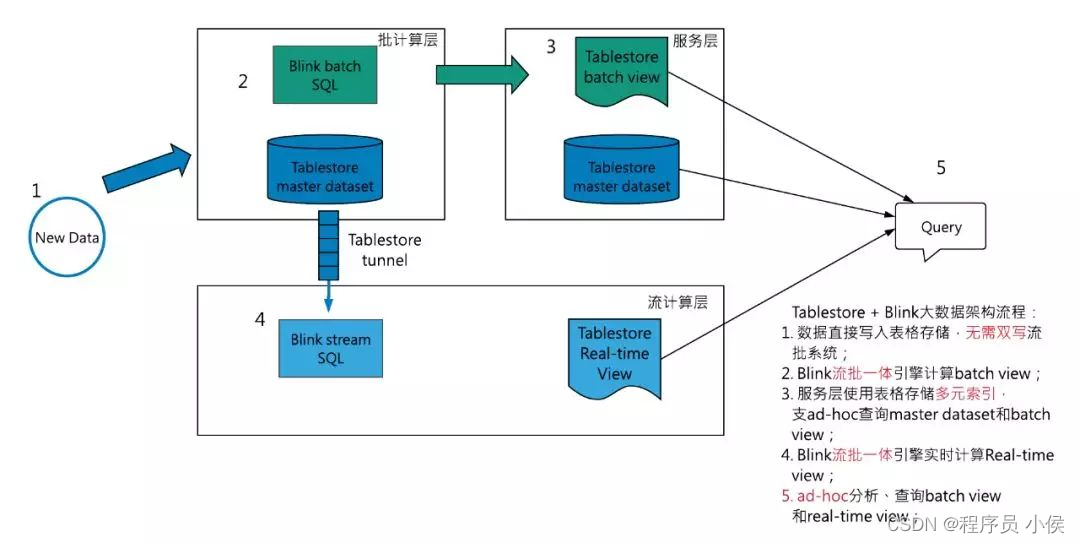
实时流处理架构:
随着数据量和业务需求的增长,批处理架构的限制变得更为明显。实时流处理架构逐渐崭露头角,允许数据以流的形式进行处理和分析,以实现更低的延迟和更高的即时性。在实时流处理架构中,数据可以在产生的时候立即被处理,从而支持更实时的决策和分析。流处理框架如Apache Kafka和Apache Flink在这一演进过程中扮演了重要角色。
优点:
- 实时性更强,能够满足需要即时响应的场景。
- 适用于实时监控、实时分析和实时决策。
- 可以减少数据处理的延迟,提高数据价值。
缺点:
- 对于一些历史数据分析等场景,实时流处理可能不如批处理高效。
- 处理大量实时数据可能需要更多的资源和复杂的管理。

混合架构:
随着业务需求的多样化,批处理和实时流处理的结合成为了一种常见的架构选择。在许多场景下,批处理和实时处理是相辅相成的,可以结合起来提供更全面的数据处理能力。例如,将实时流数据存储下来,然后在批量任务中进行深入分析和挖掘。
优点:
- 可以充分发挥批处理和实时处理的优势,满足不同的业务需求。
- 可以减少实时流处理的压力,将部分处理转移到批处理中进行。
缺点:
- 增加了系统的复杂性,需要同时维护批处理和实时处理的组件。
- 数据的一致性和同步可能需要更多的注意。
综上所述,大数据处理平台的架构演进从批处理到实时流处理,反映了对数据处理速度和实时性的不断追求。不同的架构范式在不同的场景下有其独特的优势,根据业务需求和数据特性进行选择和结合,可以更好地满足多样化的大数据处理需求。
后记 👉👉💕💕美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!! 🌹🌹🌹
