
《云栖战略参考》由阿里云与钛媒体联合策划,呈现云计算与人工智能领域的最新技术战略观点与业务实践探索,希望这些内容能让您有所启发。
文/张申宇
作为一家成立已有百年的传统制造业企业,松下业务覆盖广,并且在中国及东北亚地区拥有多达64家独立法人公司,员工人数超过4万人。
多元化的业务组合为松下常年可持续性发展提供了坚实的保障,但也带来了不小的挑战。错综复杂的传统烟囱式IT架构让这家深耕中国市场近30年的制造业龙头在数字化转型的过程中面临诸多难题,松下中国的64家法人公司“各自为政”,形成了一个个数据孤岛,无法进行及时的数据共享导致了业务洞察不及时、响应慢等诸多问题。
如何在新的云计算技术时代焕发活力、敏锐洞察前沿趋势?松下中国正在尝试解答这一时代命题,历时三年的大数据治理正让“大象起舞”。
百年制造业企业的数据应用之痛
大数据分为两个维度,一是数据量规模,另一个是数据的复杂度和多样性。
对松下中国这类传统企业来说,它们不像互联网企业有很多数字化渠道,其数据主要来自内部,例如财务系统、生产计划系统,所以整体数据量没有互联网企业多,但量级也能达到TB级。
对松下来说,更大的问题在于数据的复杂度和多样性,以及如何让数据在众多公司之间高效地流通与使用。松下中国业务种类丰富、体系庞大、供应链管理复杂,其在中国的布局已有30多年,集研发、生产、制造、流通、销售、服务于一体,业务范围涉及研究开发、养老、住建、汽车、车载、能源、电池等多个领域,这些多元化的业务组合为松下常年可持续性发展提供坚实保障,但也带来管理层面的各种挑战。
“烟囱式的架构使得松下拥有分别独立的业务场景、IT系统、数据库,造成了严重的数据孤岛,系统和系统之间的数据语言不统一让数据无法贯穿,最终导致数据无法分析。”松下信息系统(上海)有限公司数据分析部部长南宫兰强调,“很多主数据,比如产品主数据、客户主数据,部分是在CRM系统里,部分是在ERP系统里,部分是在Excel表格里,我们分析时无法确认到底以哪个数据为准,同时也带来了数据分析准确性的问题。”
长期基于Excel进行数字化表格的制作也造成了工作效率低下。“工作人员需要耗费大量时间成本手动完成数据整理、分析和存储,实际上并没有较好地顺应互联网浪潮,因此我们迫切需要改变这一局面。”南宫兰如是说。
不仅如此,原先松下旗下的每家法人公司都是自行搭建IT架构,重复的IT建设不仅带来了重复投资的成本浪费,也带来了一系列技术层面的问题,运维成本也逐年上升。此外,由于每个架构体系不一样,技术人员需要学习很多新技术和工具,带来了极大负担。
例如,在松下中国电池业务的物料全生命周期管理中,因为以前不能实时分享各项数据,数据流拉通不及时,导致了电池物料的批次、工位、供应商等生产信息查询效率极其低下,甚至出现查询不到的情况,链路内各个部门沟通不及时,最终导致了电池的品控、质量监督难题,甚至会出现大量积压库存、排期生产困难等严重影响企业效率的问题。
如何有效的利用销售数据对销售趋势进行预测,从而更好地安排产品排产,以及通过数据分析进一步降低产品的不良率等问题,也是松下彼时面临的重要挑战。
上述种种问题及挑战也映射出了不同部门、不同法人公司之间沟通效率问题,最终导致了工作效率与投入产出量化困难。在当下需要降本增效的大环境下,显然传统的烟囱式的架构已经不能满足以松下为代表的传统制造业企业的数字化需求。
除了技术难题,观念上的“思想包袱”也是阻碍松下数字化进程的一大因素,会导致运营效率低下,增加经营压力。对此,南宫兰坦言:“老牌工业企业历史包袱比较重,在过去几十年的经营过程当中形成的一种习惯性的思维,意识上的差异是最难解决的。”
松下的数据之路,从搭建云上全托管大数据平台开始
基于以上痛点,在2020年前后,松下集团提出了“松下变革”的发展理念,决心重新搭建IT架构,并逐步将原有业务迁移到新架构之上。
“从集团整体的角度出发,经过多次的选型和对比,我们选择了兼容性更强、开放程度更高的技术架构,开始重新搭建集团整体IT架构。”南宫兰表示,“核心目的是提升自身运营效率,实现降本增效。”基于此,松下中国于2021年正式确定使用阿里云提供的MaxCompute+DataWorks+Hologres的方案,搭建全托管大数据平台,数据底座由Serverless架构打造。
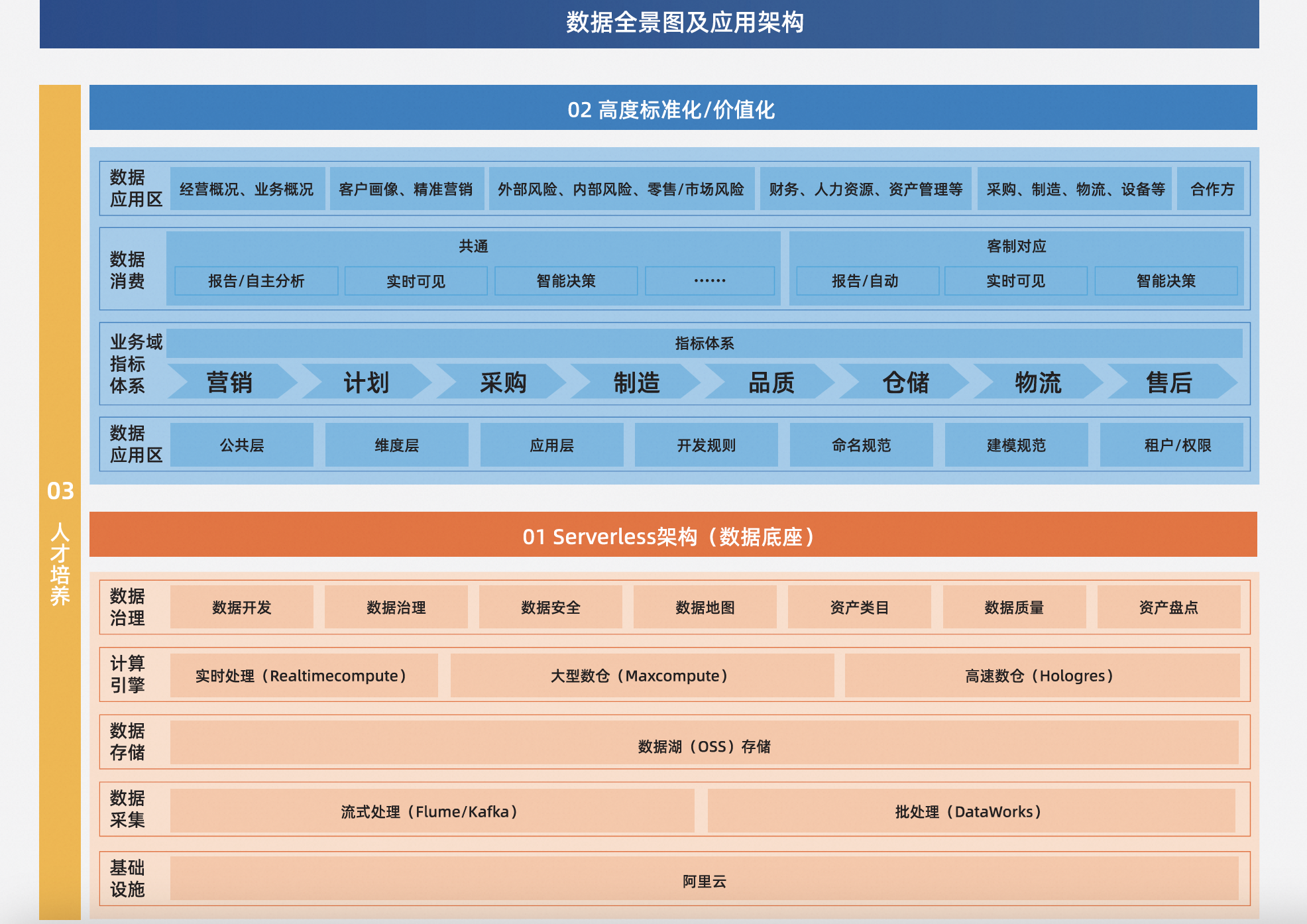
“从公司角度出发,核心指标是如何把现有的成熟工具、产品经过组合,更高效地给应用方去使用。这样的目标决定了我们需要选择低成本、高性能、高可用的Serverless架构。”南宫兰强调。
原先每多对接一家工厂,团队可能就得增加一个人员,并且常态化负责平台运维。采用Serverless的全托管方案后,不到10人的团队就能对接所有工厂。松下中国IT部门的人员可以将更多的精力聚焦在如何利用数据创造价值上,底层包括升级、备份、灾备、弹性等在
内的众多“脏活累活”都可以交给阿里云,这种模式让企业的人员可以有更多的精力专注于驱动自身业务发展。另外Serverless架构与之前购买机器的旧方式对比,旧方式会导致机器的闲置率高,而在Serverless架构下不使用资源时不收费,又可以实现存储计算分别扩缩容,弹性能力极佳,从而可以显著降低成本,符合公司降本增效的业务目标。
不过Serverless只是让平台初期仅仅具备基础能力,南宫兰将这个平台比作“毛坯房”。2022年,松下中国基于大数据平台的基础,在数据应用层进行工作指标体系搭建、数据资产盘点及开发规范流程化等工作,并对贯穿销售以及计划采购、制造、品质等多个场景在内的最上游用户层进行了数据分析的产品化封装,算是进入到了“拎包入住”的阶段。
“此时,我们具备提供给不同法人公司使用的统一架构,但各个法人之间的数据互联互通仍是一个比较难的问题。”南宫兰表示,2023年,松下中国集中解决了不同法人公司之间的标准互通和系统、数据等独立分割的问题。
具体来说,一方面,通过MaxCompute+DataWorks搭建的解决方案操作更加便捷。“我们对不同部门的云资源权限进行严格控制,禁止随意操作生产环境的资源,保证生产环境中数据的安全性,不同法人公司只需关心作业和数据,而无需关心底层分布式架构及运维。”南宫兰强调。
在这套大数据平台中,一个DataWorks工作空间对应两个MaxCompute项目,并且支持设置开发和生产双环境,进一步提升了代码规范,保证了生产环境中数据的安全性与稳定性。MaxCompute+DataWorks使用一套用户认证体系,集成MyID,管理简单;集成权限管理平台具备敏感数据自动发现、数据脱敏、数据水印溯源、审批和审计权限等能力。而这点也正好满足了松下中国对于不同法人公司之间数据保密性与流通性的需求。
解决了众多公司之间的数据流通问题后,则进入了“毛坯房”的精装阶段,需要更加高效的装修工具。“市面上的数据开发工具,大家看架构图,其实都差不多,好像每个产品大家都有,但是在我们对比和深入使用各个产品后,发现DataWorks作为十几年沉淀的工具产品,在开发、运维、建模、治理等方面所需要的产品能力非常齐全和深入。”南宫兰表示,通过可视化的全链路SQL开发方式,覆盖了从数据集成、ETL、分析、治理各个阶段,原本需要3-6个月才能对接完成1家公司的数据工作,现在缩短到了1个月。
数据实时化方面,通过采用一站式实时数仓Hologres与Flink,松下中国具备了快捷、实时的数据分析能力。Hologres支持实时数据同步和快速查询,可以在数据写入后立即进行分析和查询的特点,也解决了原本松下信息同步不及时和延时性的问题,实现了数据的实时更新、实时分析。“Hologres还能和离线MaxCompute数据一体化融合,进一步提升了效率的同时也降低了成本。”南宫兰表示,这让松下中国的数据处理能力和业务响应速度有了质的飞跃。
除此之外,使用云上的全托管的产品,企业非常关心数据安全问题,“全托管产品对我们来说相对比较黑盒,阿里云架构师刘旭、仲向远带队和我们沟通了很多次,除了阿里云本身一些安全能力,也给我们介绍了大数据多租户数据隔离等技术原理,解决了我们很多的疑虑。”南宫兰补充到,这也是很多企业客户在选择云上产品时也会有的顾虑。
降本超30%,2025全面覆盖
2022年底,跨部门、跨公司的数据孤岛已被打通,新的架构帮助集团和下属法人公司实现了降本增效。
目前,松下旗下的64家法人公司已经有21家加入了新的IT架构中,为松下集团在中国及东北亚地区节约了超过30%的总成本,减少了近50%的交付时间,同时大幅降低了系统的故障率。“大数据平台上线两年多来,一直稳定运行,没有发生过一次宕机。”南宫兰表示。
在公司内部,降本增效的场景也比比皆是。
例如,在松下中国经营分析端的业务效率化场景,实现了PSI内部关键决裁会议资料中财务数据输出的全自动化。对比原来要从不同的系统去手动下载、处理相关数据,通过大数据平台改造,减少了60%以上的手动处理工作量。
在生产端,通过生产销售系统数据整合分析,工厂经营中一个非常重要的生产指标——“LeadTime(订单交货周期)”,实现了非常可观的提升。经过一年的改善,信息流LT由12天缩减至5天,物资流LT从44天缩减至28天,大大提升了订单响应速度以及工厂经营风险把控能力。
此外,通过大数据平台建立了销量预测,松下中国解决了原来缺乏销量预测时期的需求满足率低、库存高、以及长周期原材料备货困难等问题。
以制造业最常见的物料全生命周期管理为例,在迁移至新架构之前,松下集团内部采用的是月度信息共享制度,并且是以邮件/电话的形式进行共享,容易造成极大的信息差及延时问题。迁移到全新大数据平台后,不仅拉通了包括制产销在内的各个部门的信息,工厂、门店、公司,以及各个法人公司之间的数据也实现了全面拉通,消除了信息差,提升了后端响应速度的同时,降低了制造废率。
实现“拎包入住”式的IT架构仅是松下中国数智化转型的第一步。接下来,松下中国还将从“横向”“纵向”两个维度,进一步深入企业对于数据的应用,从而进一步激发数据价值。
从纵向维度看,南宫兰表示:“现阶段,松下中国的整体数字架构是‘大而广’。未来,将会在更多精细化场景推广大数据应用,实现制造智能化,并积极探索大模型在制造业的应用场景的落地。”
从横向维度看,目前新的架构仅覆盖30%的法人公司。“我们希望,在2025年之前实现64家法人公司全覆盖。”南宫兰如是说。而随着越来越多的法人公司加入新的架构中,以及松下中国数据应用的成熟度越来越高,实现以数据驱动业务发展已经在松下内部逐步展开。
值得一提的是,刚刚过去的2023年,松下得到属于制造业自己的数据中台著作权认证,这也是未来松下中国数字布局中重要的一环——具备对外提供数字技术服务的能力。
松下有业内公认的精细化管理体系,其明确的顶层管理框架和方法论与阿里云数据工具平台结合,通过智能数据建模,把底层数据多样复杂性屏蔽掉、实现统一化,搭建指标体系、数据模型,甚至最终的数据产品将变成一个有价值的、明确的数据中间层,形成可复制的能力,不仅仅在集团内部实现成功推广,更希望能够推动行业的数据标准化建设。
可以预见,未来松下中国将进一步与阿里云深入合作,对内赋能自身业务发展;对外输出数字能力,打造内外“双循环”。
