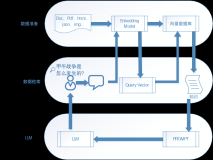
为了训练AI模型,需要收集和准备足够的数据。数据应该涵盖各种情况和场景,以确保系统在各种情况下都能准确地运行。数据原始来源应该是真实的,并且应该涵盖系统预计的使用情况。数据应该根据特定的需求进行采样和处理,可以来自各种来源,例如公共数据集、第三方数据提供商、内部数据集和模拟数据集等。很多大模型训练的数据从广义上可以分成两大类,其一是通用文本数据,包含了网页、书籍、网络留言以及网络对话,这类主要是因为获取容易、数据规模大而被广泛的大模型利用,通用文本数据更容易提高大模型的泛化能力;其二是专用文本数据,主要是一些多语言类别的数据、科学相关的产出数据以及代码,这类数据可以提高大模型的专项任务的能力。在准备数据时,还应该注意数据的质量,例如数据的准确性、完整性和一致性。另外,还应该考虑隐私和安全问题,如果数据包含敏感信息,例如用户的个人身份信息,应该采取脱敏措施确保数据的安全性和隐私性。数据收集和准备是测试AI系统的重要步骤之一,需要充分的计划和准备,以确保测试的准确性和全面性。
数据收集完成后,通常是要对数据进行清洗,这里的清洗说的是对数据一些“不好”的内容的处理,这里的不好指的是数据的噪音、冗余、有毒等内容,从而确保数据集的质量和一致性。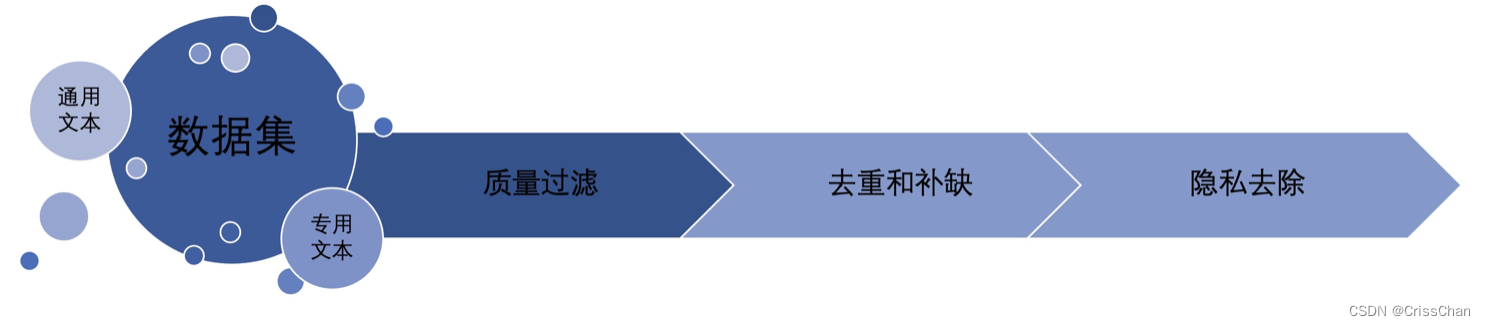
无论收集到的数据集是通用文本数据、还是专用文本数据都要经过一系列的数据清洗才能用于 LLM 模型的训练,在面对初始收集的数据集需要首先通过质量过滤提高数据集的数据质量,常规的做法是设计一组过滤规则,消除低质量的数据,从而实现数据质量的提高。那么常用的规则有基于语言的过滤规则、基于度量的过滤规则、基于关键词的过滤规则。
- 基于语言的过滤规则:如果LLM主要用于某一类语言的任务处理,那么就可以建立清除其他语言的数据的过滤规则,从而剩下目标语言的数据。
- 基于度量的过滤规则:可以利用生成文本的评估度量,也就是 LLM 生成的问题进行度量从而检测并删除一些不自然的数据。
- 基于统计的过滤规则:利用数据集中统计特征来评价数据集中的数据的质量过滤低质量的数据,这里的统计特征可以是标点的分布、符号与单词比率,句子长度等。
- 基于关键词的过滤规则:基于特定的关键词集合,可以识别和删除文本中的噪音或无用元素,例如 HTML 标签、有毒词语等。
在数据清洗中一个重要的工作就是去重和补缺,在收集到的数据集中可能有很多重复的样本,那么在数据集可以投入使用之前通过对数据各个字段的检测删除重复内容,确保数据集中的样本都是唯一的。在去重的过程中,我们同样也会关注数据是否有缺失,这里的缺失是指某些字段或者特征缺少信息,而不是说少了某一方面的数据,对于缺失值的数据我们可以选择删除该条记录,也可以使用插补方法填充缺失内容。目前常用的插补方法有均值填补、中位数填补、众数填补以及用其他一些模型进行预测填补,均值填补就是使用数据集中缺失字段其他记录中其他数据的算术平均数进行填补(算术平均数是一组数据之和,除以这组数据个数的结果值);中位数填补和均值填补的思路类似(中位数是按顺序排列的一组数据中居于中间位置的数),就是填补进去的值不再是算数平均数而是对应缺失字段的中位数;众数填补(众数是在一组数据中,出现次数最多的数据。)也是同样的道理,就是用众数替换了上面的算术平均数。用模型进行预测填补是一个目前还说相对较新的方向,利用一些模型的预判能力补充数据的缺失。无论是哪一种,都会面临一些填补后数据出现重复样本的可能,因此去重和数据缺失填补是一个交替的工作。
由于数据集的来源不唯一,因此数据除去重复、缺失值意外还有可能很多不一致的问题,这些问题有些是因为原系统的数据是人工输入的、也有可能是不通系统的设计差异导致的,例如在日期的存储中,不同的系统设计差异性非常大,有的采用了日、月、年的方式存储,有的是月、日、年的顺序存储,有的采用了/作为分割线(20/02/2022,是 2022 年的 02 月 20 日),有的采用-作为分割线(02-20-2022,是 2022 年的 02 月 20 日),因此需要将其含义一样,但是表现不一致的数据统一格式,将文本数据转换为小写或大写形式,统一单位等。在处理数据一致性的过程中同时也会关注数据的异常值,这里说的异常值不是数据缺失,而是数据有明显的问题,数据很多原始来源都是人工输入的,往往很多原始系统的设计就会导致数据出现问题。异常值可能是由于测量错误、数据录入错误或真实且重要的异常情况引起的,例如我们在人口统计的数据中,年龄的字段看到了 300 ,那么这个数据就明显违反了常规逻辑,因此我们可以选择删除异常记录,或者按照前面缺失值填补方法中的均值填补、中位数填补、众数填补等方法进行填补。
隐私去除也是必不可少的数据清洗的流程,用于训练大模型的数据绝大部分都是来自网络的,这里面包含了大量的敏感信息和个人隐私信息,如果这样的数据用于大模型的训练那么对于大模型的伦理道德的会形成潜在的风险,增加隐私泄露的可能性。因此,必须从数据集中删除这方面的内容。在隐私去除过程中我们比较常用的就是基于规则的方法,例如建立删除规则的关键字,通过关键字规则删除姓名、电话、地址、银行账号等等的隐私数据。
在完成如上的数据逻辑方面的清洗后,就要进行数据可用方面的清洗,将数据类型进行正确的转换,确保数据的类型与任务的要求相匹配。例如,将文本字段转换为分类变量、将数字字段转换为连续变量或离散变量。在完成转换后,要对数据进行验证,验证数据的格式、结构是否满足了预期,例如日期字段是不是要求的格式、数据精度是否符合模型需求等等。对于跨多个数据表、数据源的数据集,对齐数据之间的关联性也需要进行分析,提出由于数据来源的不通而引起的数据偏差和错误。如果数据集过大,可以采用随机或其他采样方法来减少数据量,以加快处理和分析的速度。但要注意,采样可能会引入采样偏差,因此需要权衡和考虑采样策略。如上全部的清洗过程,都需要记录、留痕,也为了能够在后续的模型训练过程中出现一些非预期的结果的时候,反向追溯可以浮现数据清洗过程,帮助查找问题。