论文地址:
https://arxiv.org/pdf/2306.04670.pdf
项目地址:
https://github.com/mindgarage-shan/trans_object_detection_survey

Transformer在自然语言处理(NLP)中的惊人表现,让研究人员很兴奋地探索它们在计算机视觉任务中的应用。与其他计算机视觉任务一样,DEtection TRansformer (DETR)将检测视为集合预测问题,而不需要生成候选区和后处理步骤,从而将TRansformer引入到目标检测任务中。它是一种最先进的(SOTA)目标检测方法,特别是在图像中目标数量相对较少的情况下。尽管DETR很成功,但它的训练收敛速度慢,对小目标的性能较差。因此,人们提出了许多改进方法来解决这些问题,从而极大地改进了DETR。自2020年以来,基于Transformer的目标检测引起了越来越多的关注,并展示了令人印象深刻的性能。尽管研究社区已经对Transformer在视觉领域进行了大量追踪,但仍然缺少关于使用Transformer进行2D目标检测的进展的综述。本文对21篇有关DETR研究进展的论文进行了详细的综述。从Transformer的基本模块开始,如自注意力、对象查询和输入特征编码。然后,介绍了DETR的最新进展,包括backbone修改、查询设计和注意力精化。还从性能和网络设计方面比较了所有检测Transformer。希望这项研究能增加研究人员对解决在目标检测领域应用Transformer面临的现有挑战的兴趣。
从引用量、发展时间线和DETR方法变体的魔改思路分布等角度展示DETR的发展:
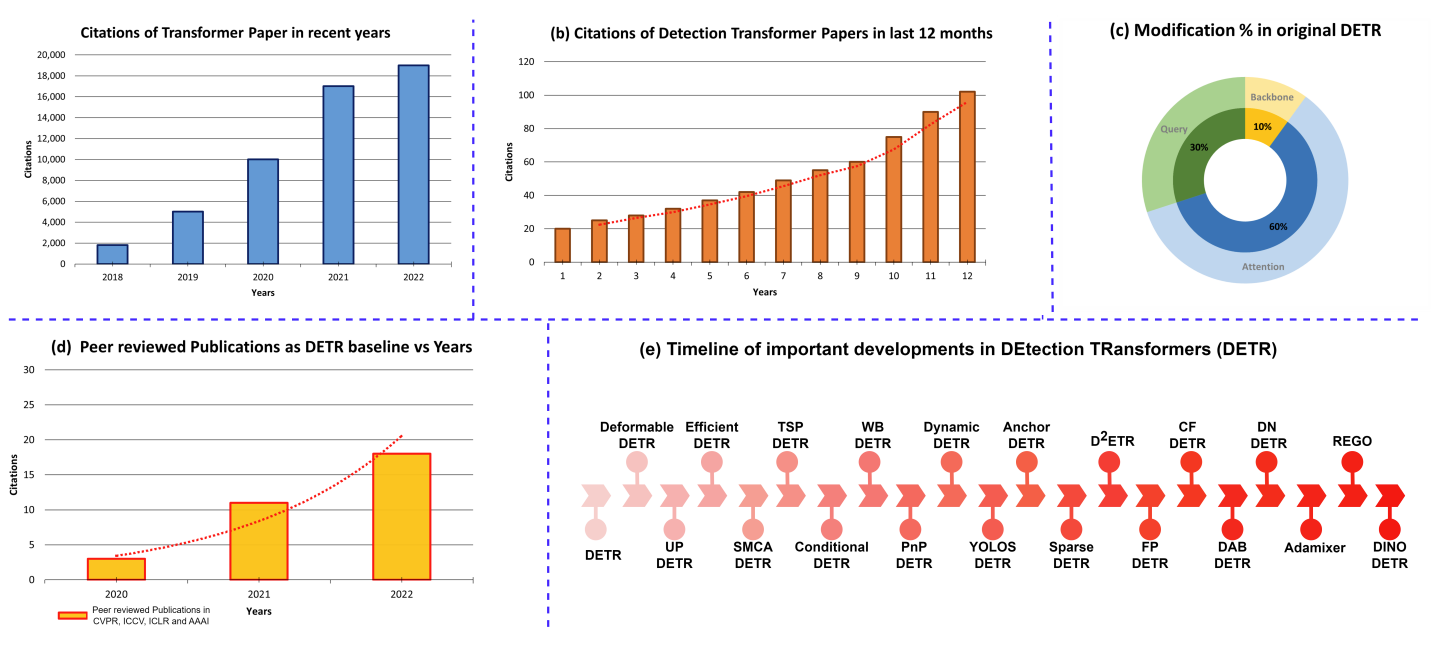
关于变形金刚的文献统计综述。
(a)每年Transformer论文的引用次数。
(b)过去12个月有关侦测变压器的论文的引用次数。
(c)为改进性能和培训一致性而对原始检测变压器(DETR)进行修改的百分比。
(d)每年使用DETR作为基线的同行评审出版物的数量。
(e)关于探测任务的DETR的重要发展的不详尽的时间表概述。
其中图c展示了DETR变体主要对Attention进行了修改,其次是query,最后是Backbone。
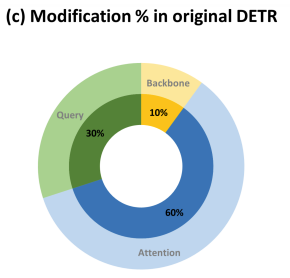
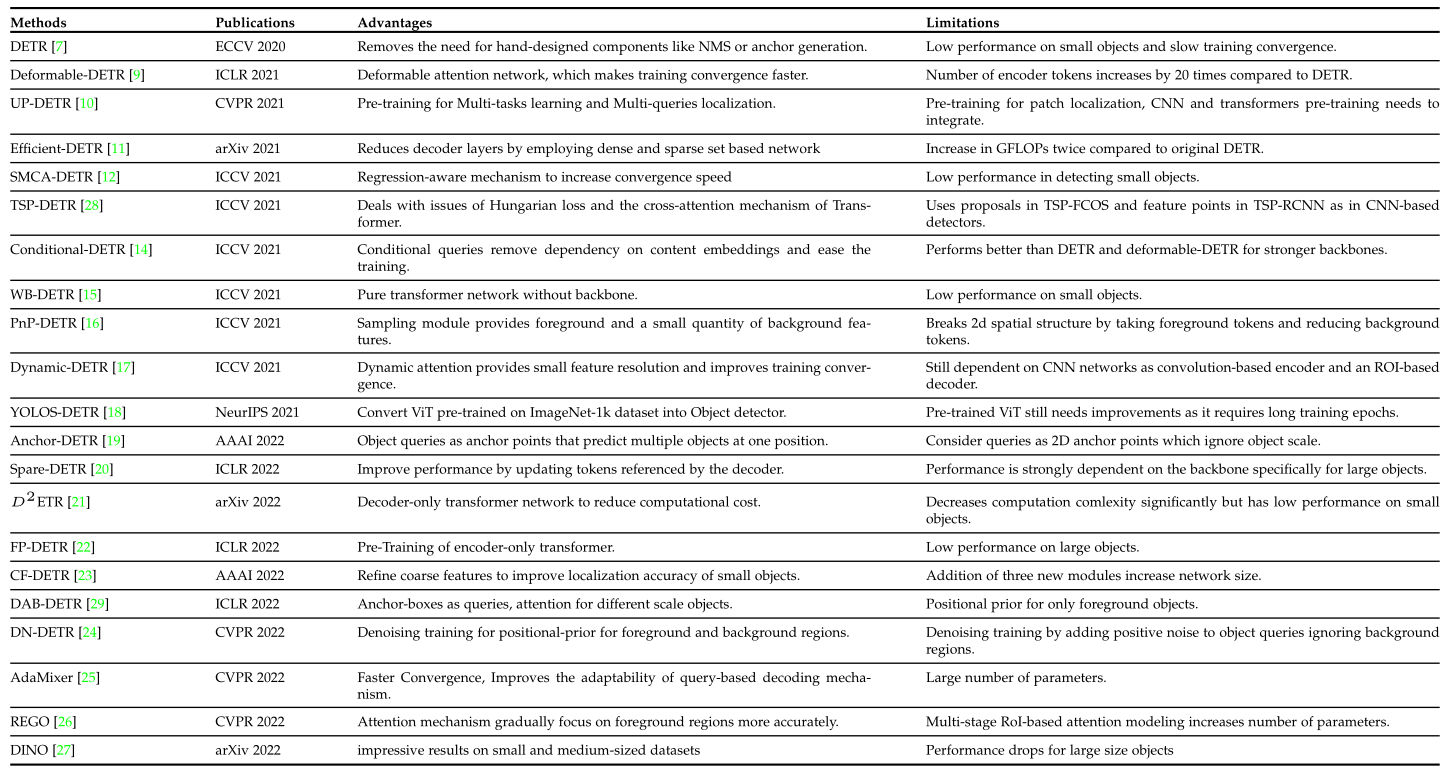
表1总结了相关变体的修改思路和亮点:
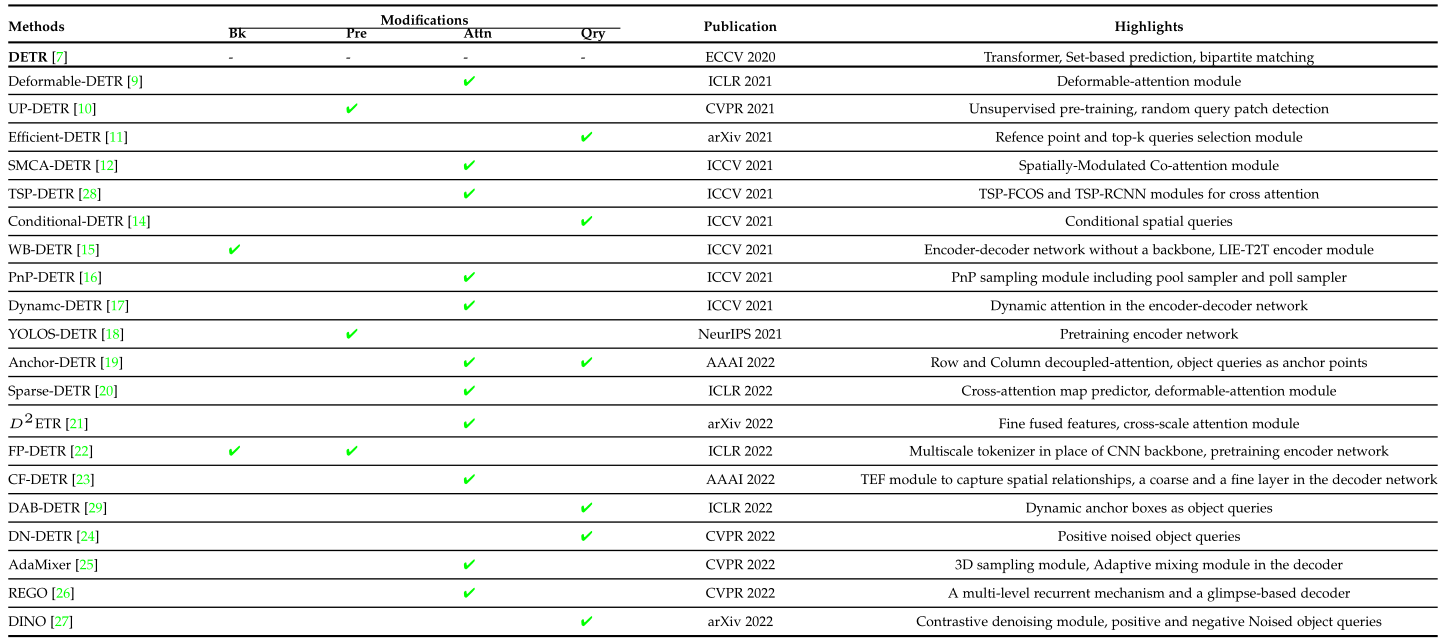
检测变压器(DETR)改进概述,使训练收敛更快,提高小目标的性能。式中,Bk表示骨干,Pre表示预训练,Attn表示注意,Qry表示变压器网络的查询。这里显示了对主要贡献的描述。
图2信息量较大,一图展示了多种变体的框架:

概述了检测变压器(DETR)及其改进的最新方法,以提高性能和训练收敛性。它将检测视为一组预测任务,并使用Transformer将网络从非最大抑制(NMS)等后处理步骤中解放出来。在这里,添加到DETR中的每个模块都用不同的颜色表示,并带有相应的标签(如右侧所示)。
该综述分别对图2中的方法进行了简要的介绍,并通过图3-9把图2中的子图抽离了出来对了些比对。
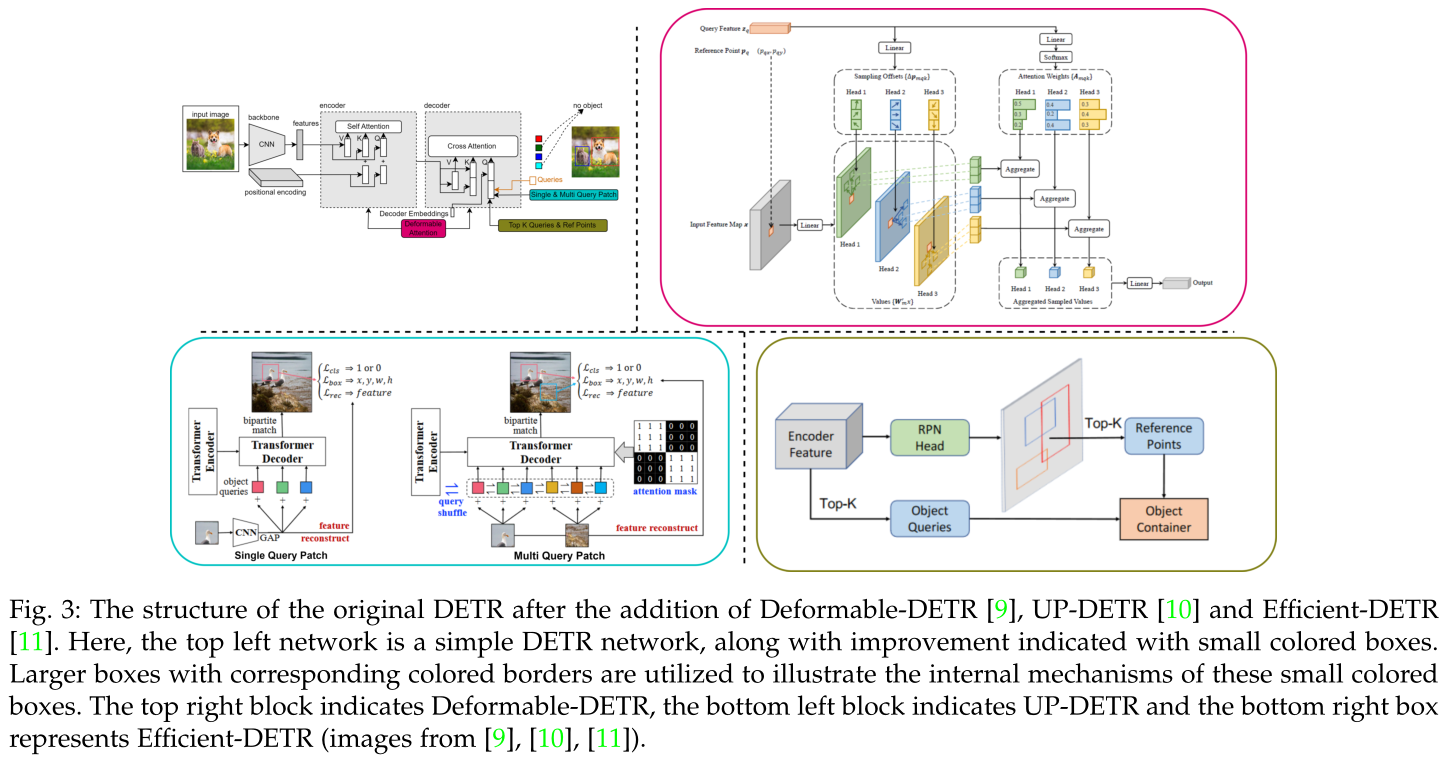
原DETR在加入deformation -DETR、UP-DETR、Efficient-DETR后的结构。这里,左上角的网络是一个简单的DETR网络,以及用小彩色框表示的改进。使用带有相应彩色边框的较大框来说明这些小彩色框的内部机制。右上方框为Deformable-DETR,左下方框为UP-DETR,右下方框为Efficient-DETR。
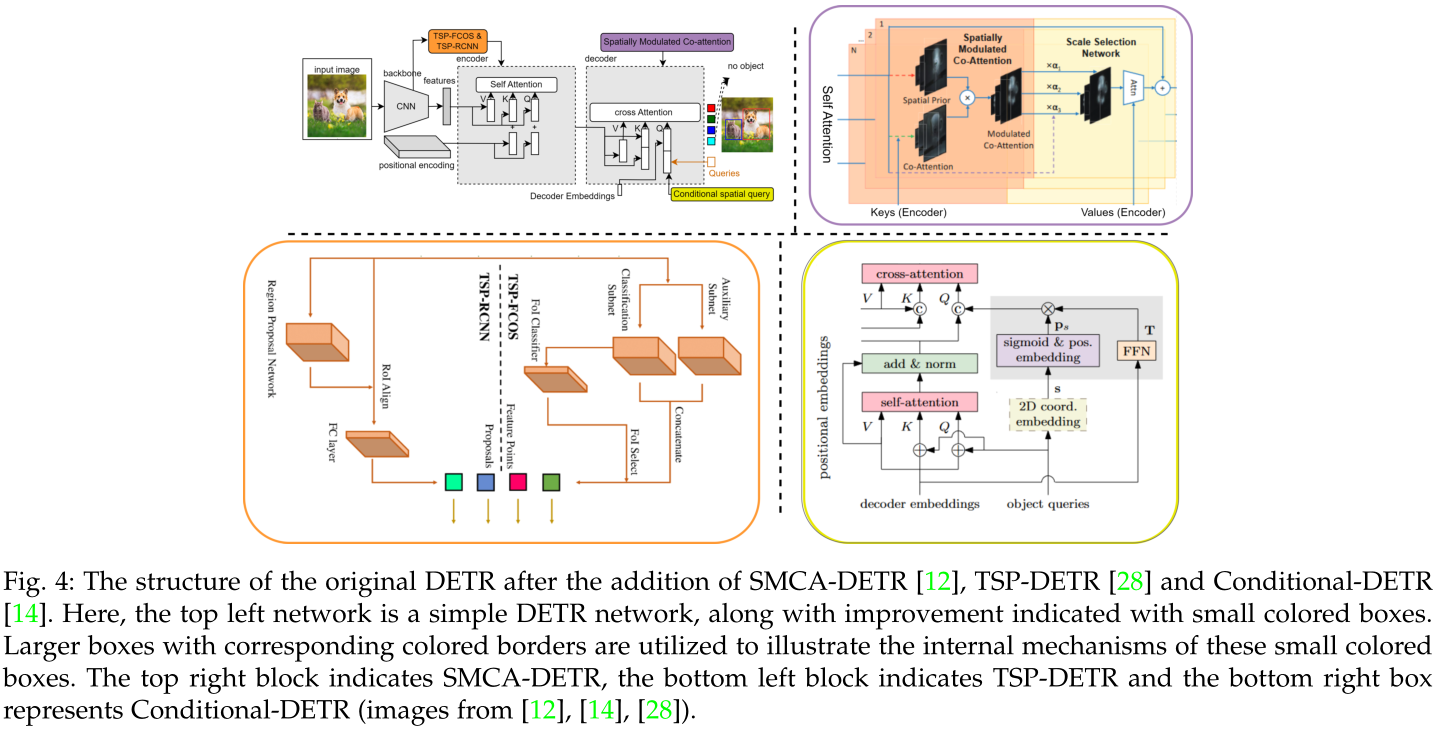
原DETR加入SMCA-DETR、TSP-DETR、condition -DETR后的结构。这里,左上角的网络是一个简单的DETR网络,以及用小彩色框表示的改进。
使用带有相应彩色边框的较大框来说明这些小彩色框的内部机制。右上方框表示SMCA-DETR,左下方框表示TSP-DETR,右下方框表示condition -DETR。
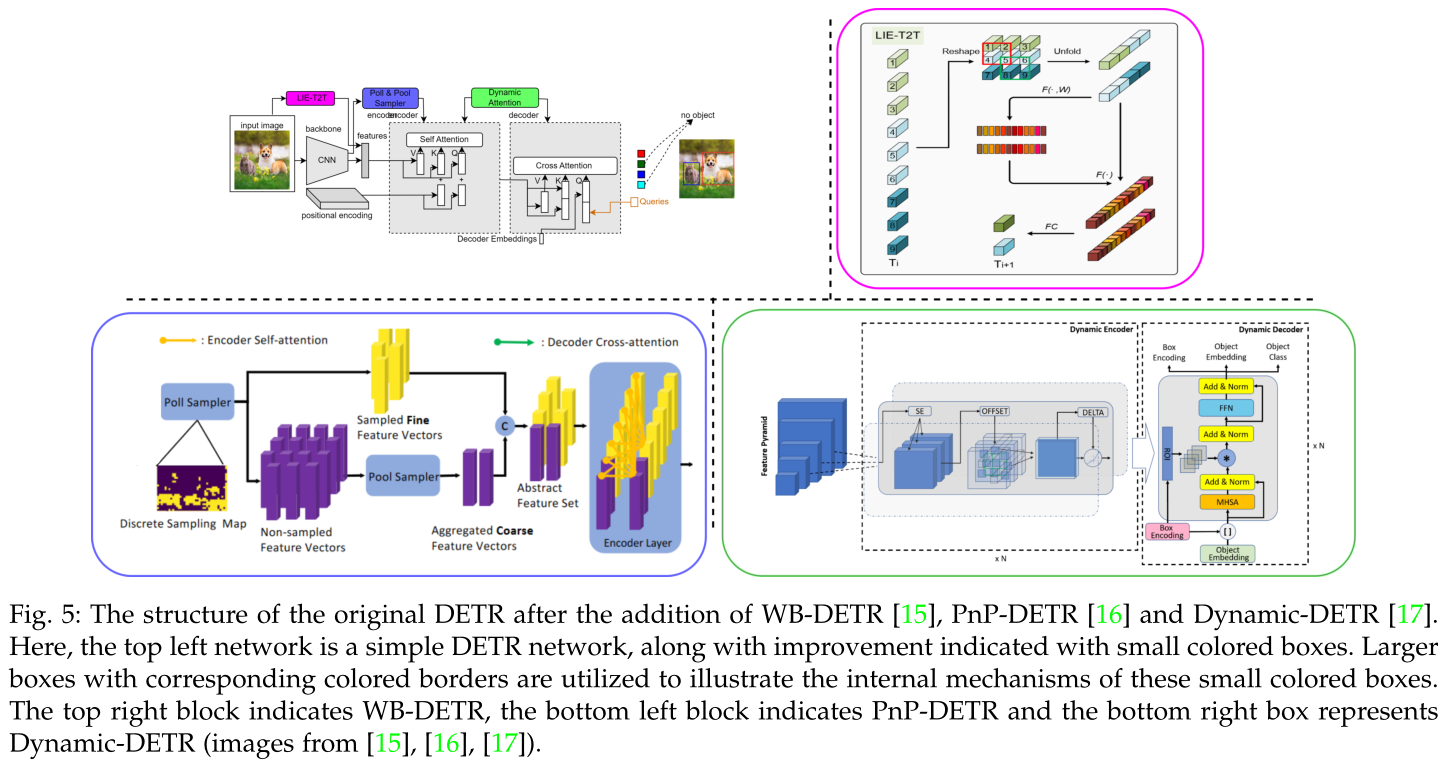
原DETR加入WB-DETR、PnP-DETR、Dynamic-DETR后的结构。
这里,左上角的网络是一个简单的DETR网络,以及用小彩色框表示的改进。使用带有相应彩色边框的较大框来说明这些小彩色框的内部机制。
右上方框为WB-DETR,左下方框为PnP-DETR,右下方框为Dynamic-DETR。
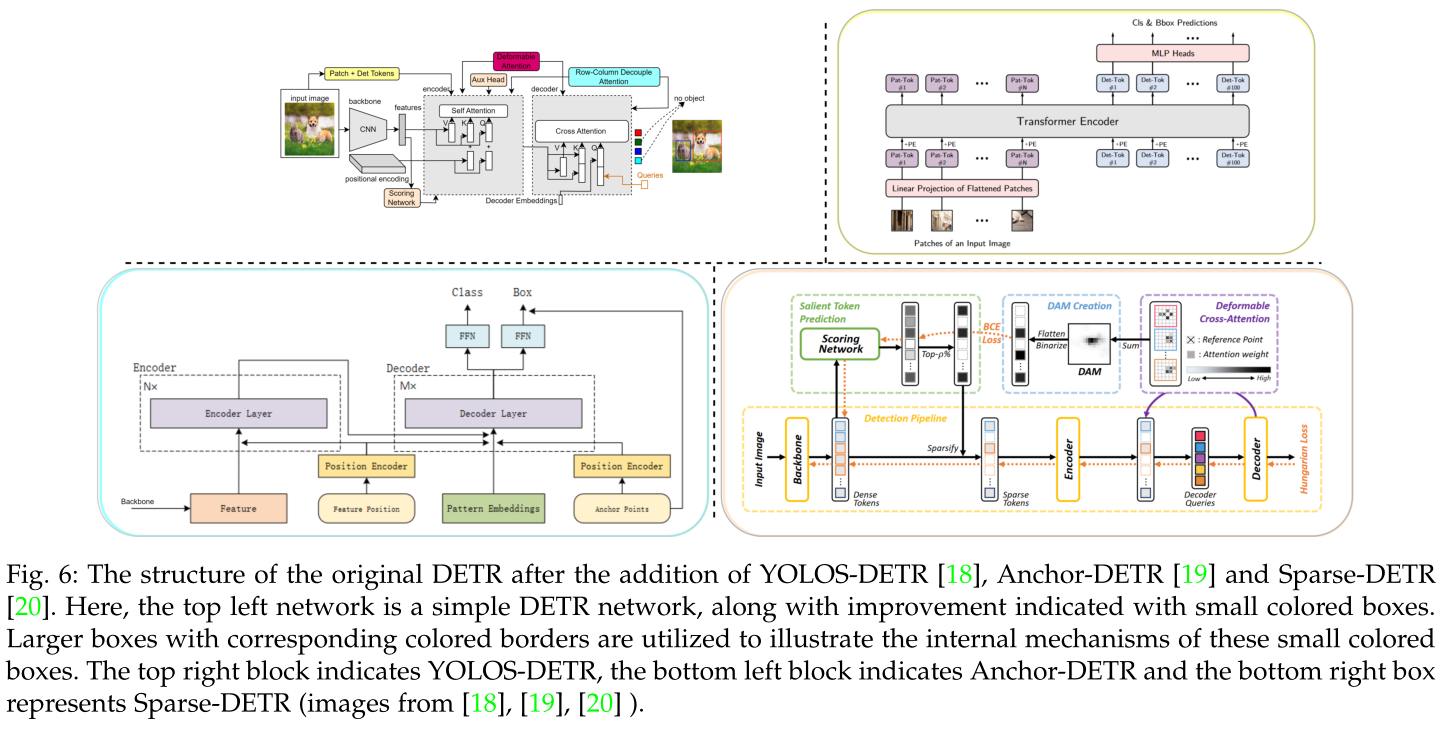
加入YOLOS-DETR、Anchor-DETR和Sparse-DETR后的原始DETR结构。这里,左上角的网络是一个简单的DETR网络,以及用小彩色框表示的改进。
使用带有相应彩色边框的较大框来说明这些小彩色框的内部机制。右上方框为YOLOS-DETR,左下方框为Anchor-DETR,右下方框为Sparse-DETR。
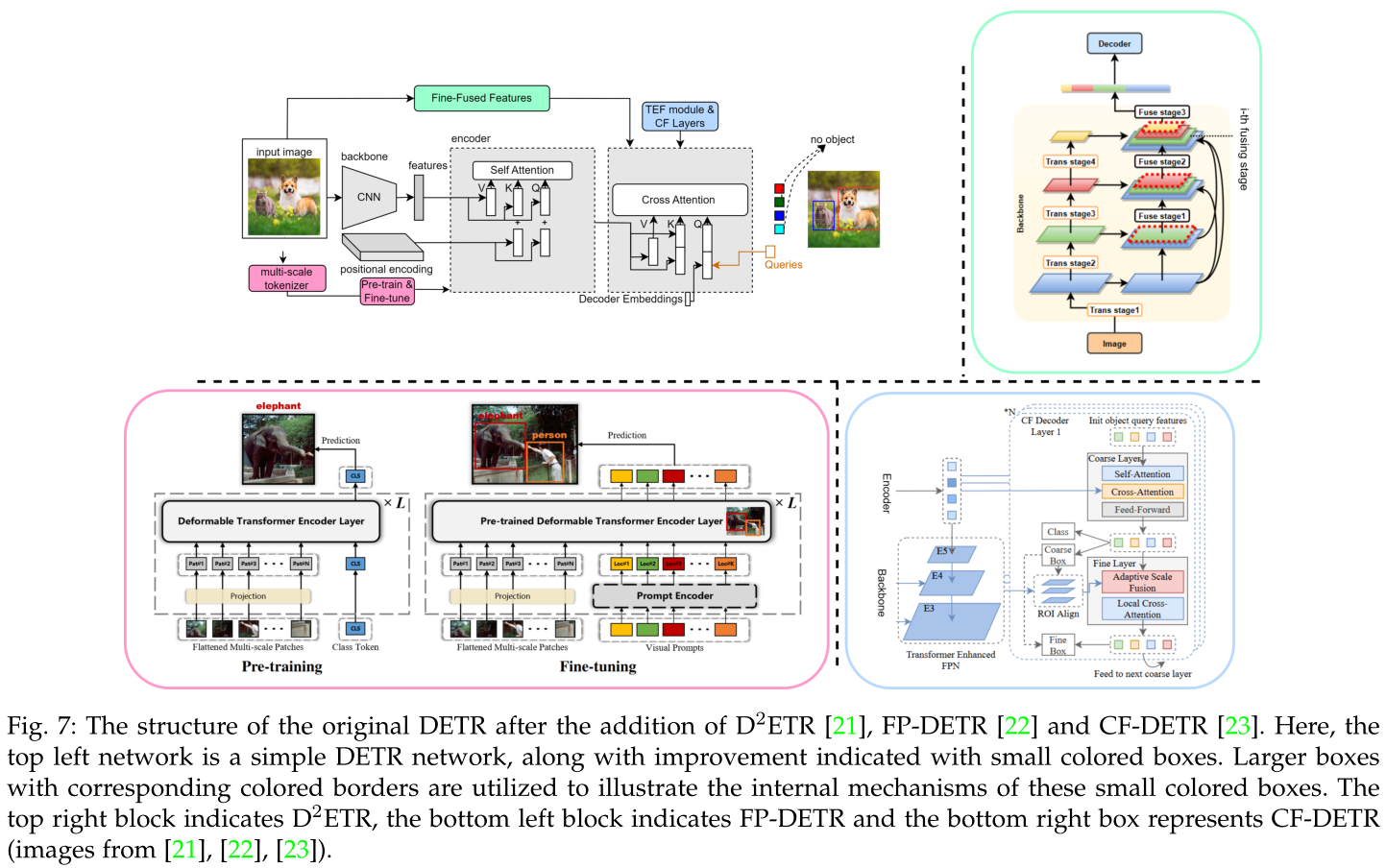
原DETR加入D2ETR、FP-DETR、CF-DETR后的结构。这里,左上角的网络是一个简单的DETR网络,以及用小彩色框表示的改进。使用带有相应彩色边框的较大框来说明这些小彩色框的内部机制。右上方框为D2ETR,左下方框为FP-DETR,右下方框为CF-DETR。
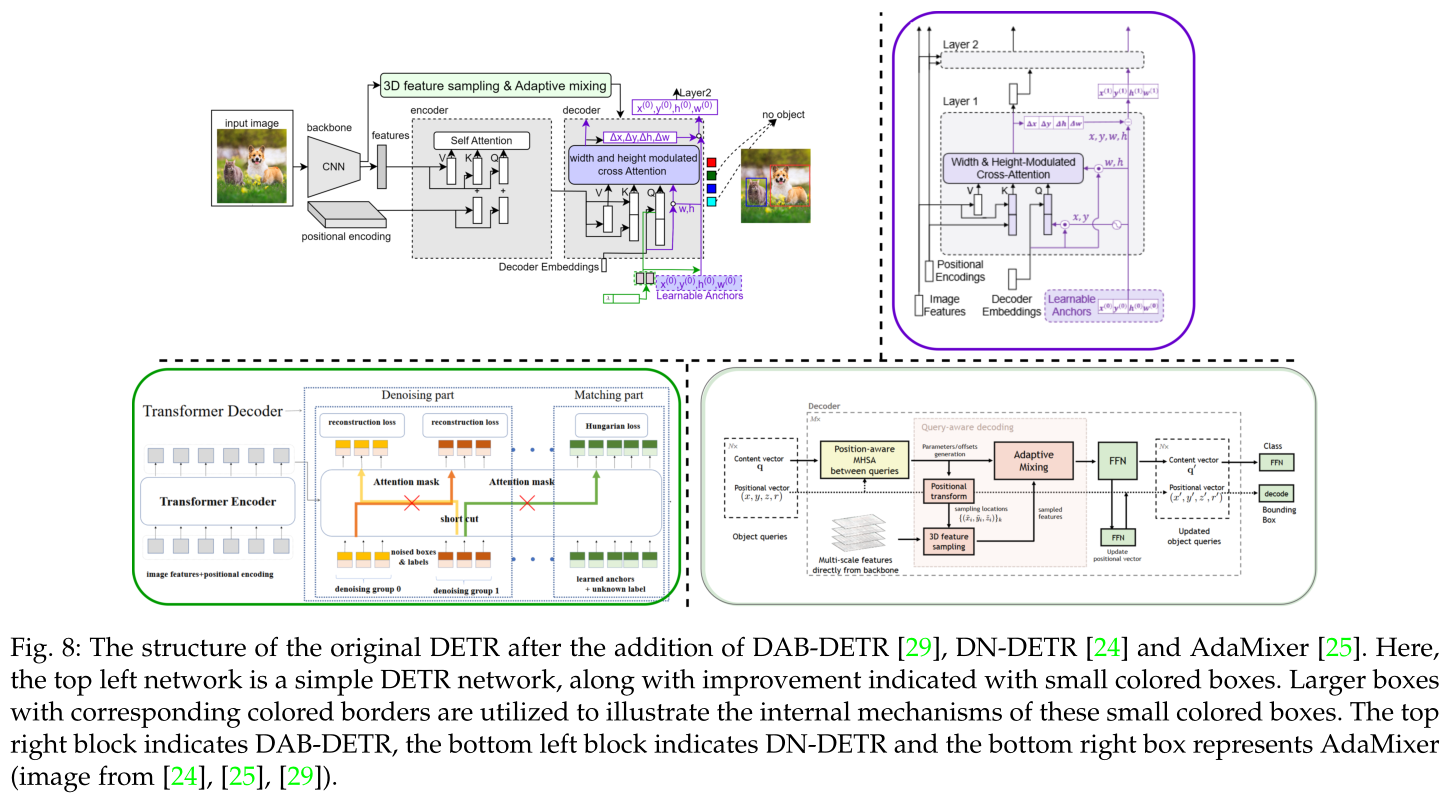
原DETR加入DAB-DETR、DN-DETR和AdaMixer后的结构。这里,左上角的网络是一个简单的DETR网络,以及用小彩色框表示的改进。使用带有相应彩色边框的较大框来说明这些小彩色框的内部机制。右上方框为DAB-DETR,左下方框为DN-DETR,右下方框为AdaMixer。
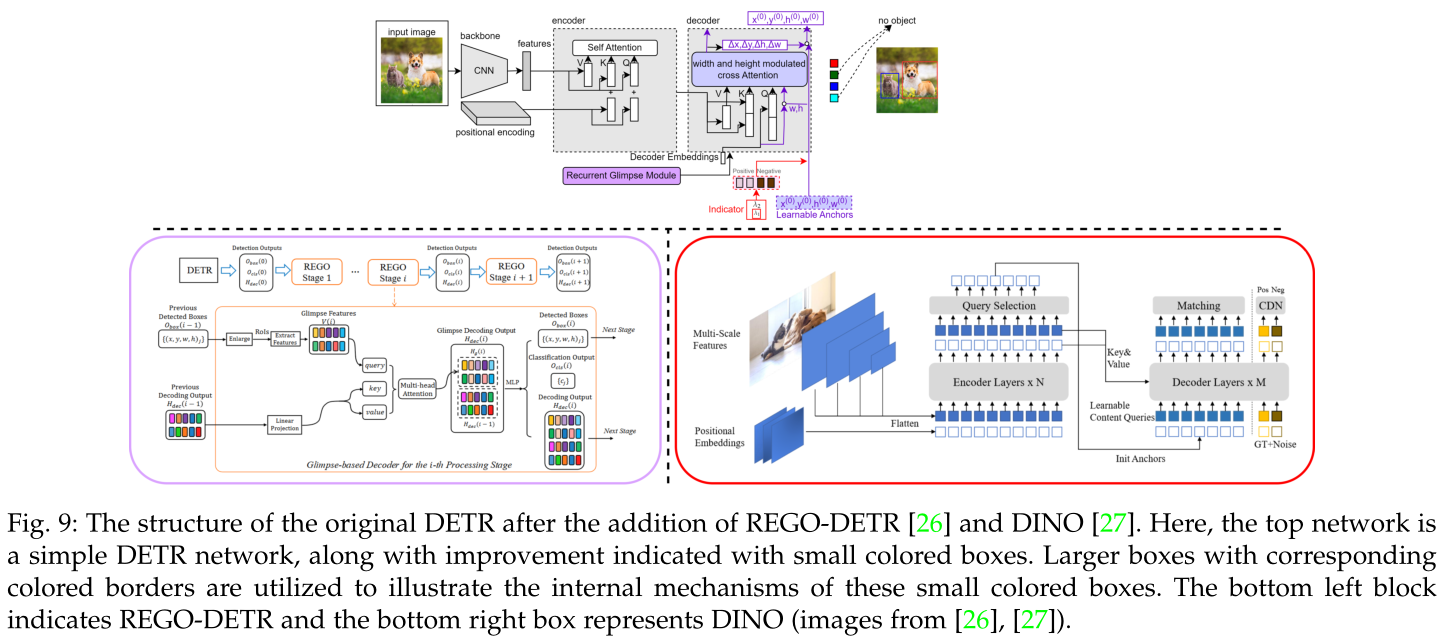
原DETR加入REGO-DETR[26]和DINO[27]后的结构。这里,顶部的网络是一个简单的DETR网络,以及用小彩色框表示的改进。使用带有相应彩色边框的较大框来说明这些小彩色框的内部机制。左下方框表示REGO-DETR,右下方框表示DINO。
表3将上述review的算法的性能进行了汇总:
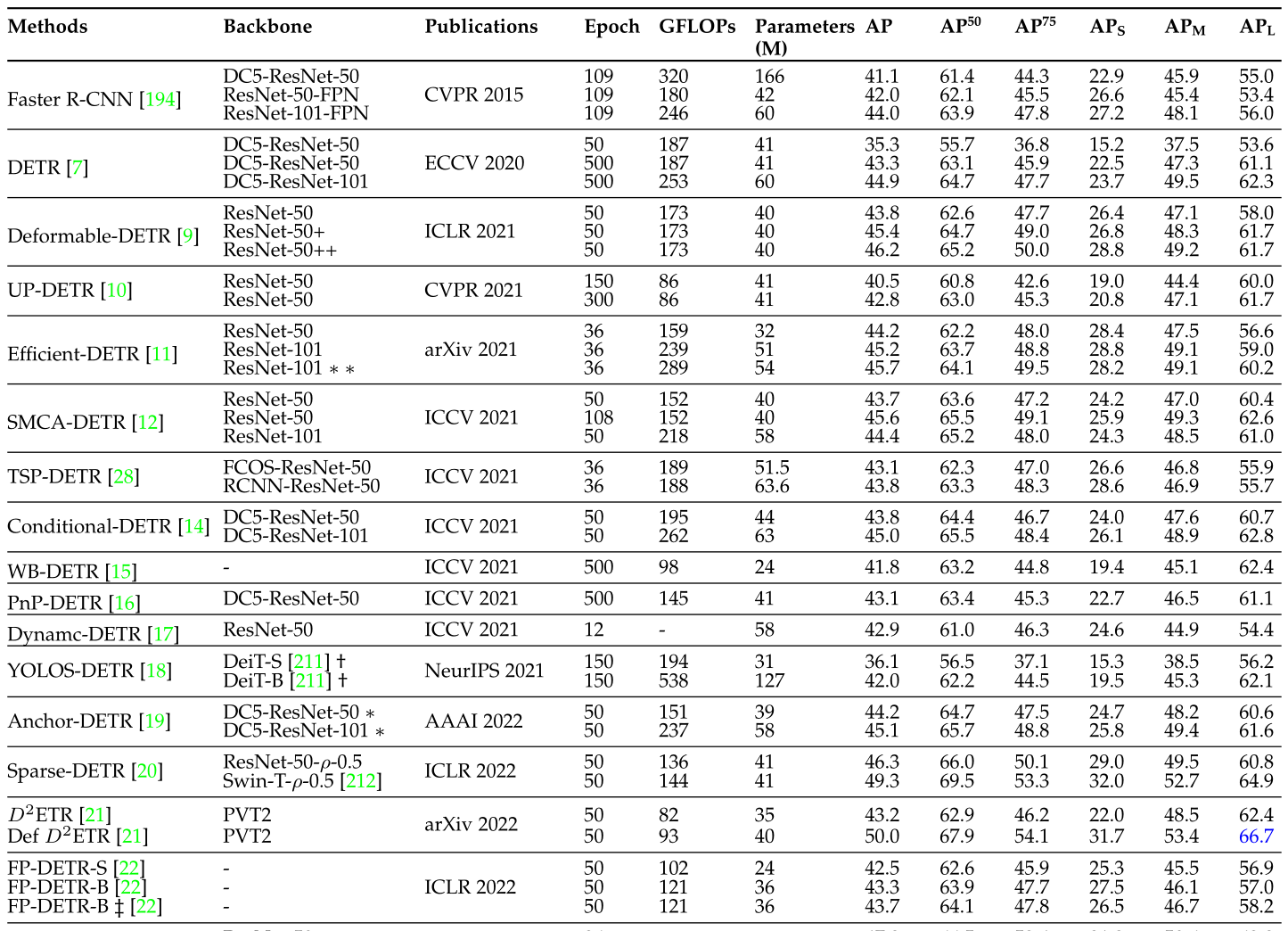
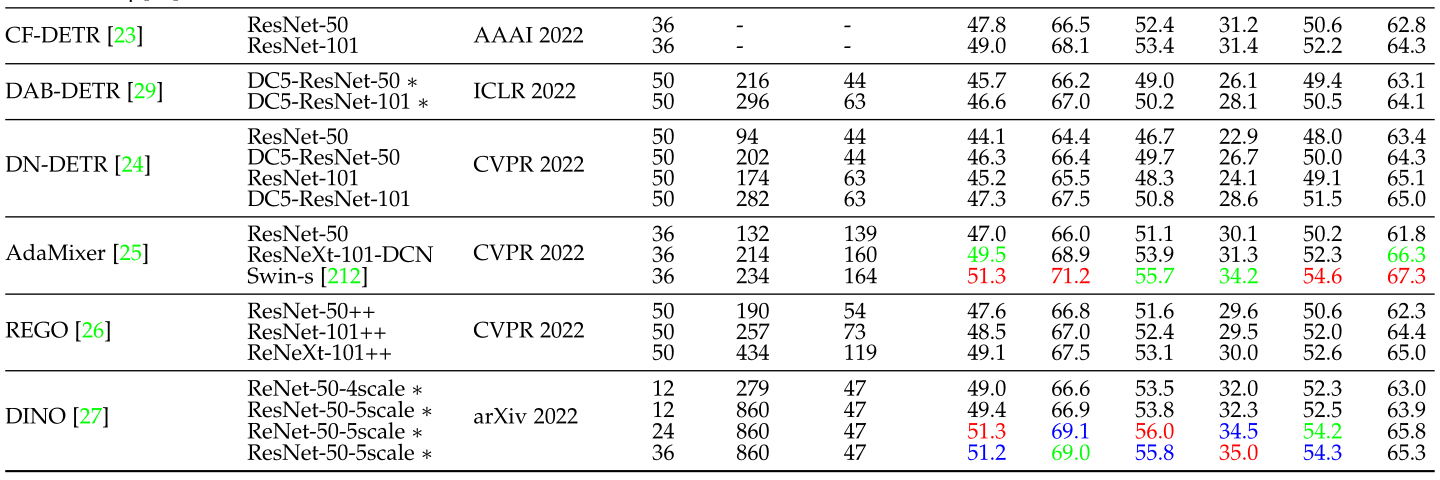
图10和图11分别对训练epoch和model size对结果的影响,算法对大中小目标的性能差异进行了对比:

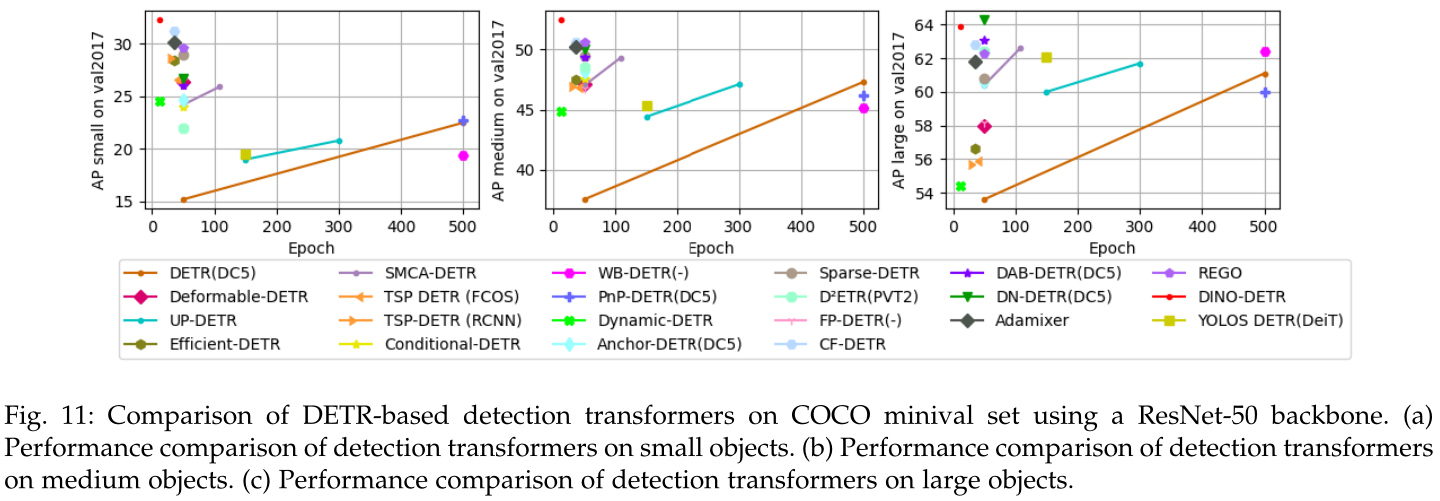
表4对各个算法的优势和局限性进行了总结: