在机器人和自动化中,控制回路是调节系统状态的非终止回路。比如恒温器,当你设定温度时,就是告诉恒温器你想要的状态,而实际室温为当前状态。恒温器通过打开或关闭设备,使当前状态更接近所需状态。
在Kubernetes中,控制器是监视集群状态的控制循环,然后根据需要进行更改。每个控制器都试图将当前群集状态变得到更接近所需状态。
Kubernetes中常见的控制器类型有:
- Deployment,无状态容器控制器,通过控制ReplicaSet来控制pod
- StatefulSet,有状态容器控制器,保证pod的有序和唯一,pod的网络标识和存储在pod重建前后一致
- DeamonSet,守护容器控制器,确保所有节点上有且仅有一个pod
- Job,普通任务容器控制器,只会执行一次
- CronJob,定时任务容器控制器,定时执行
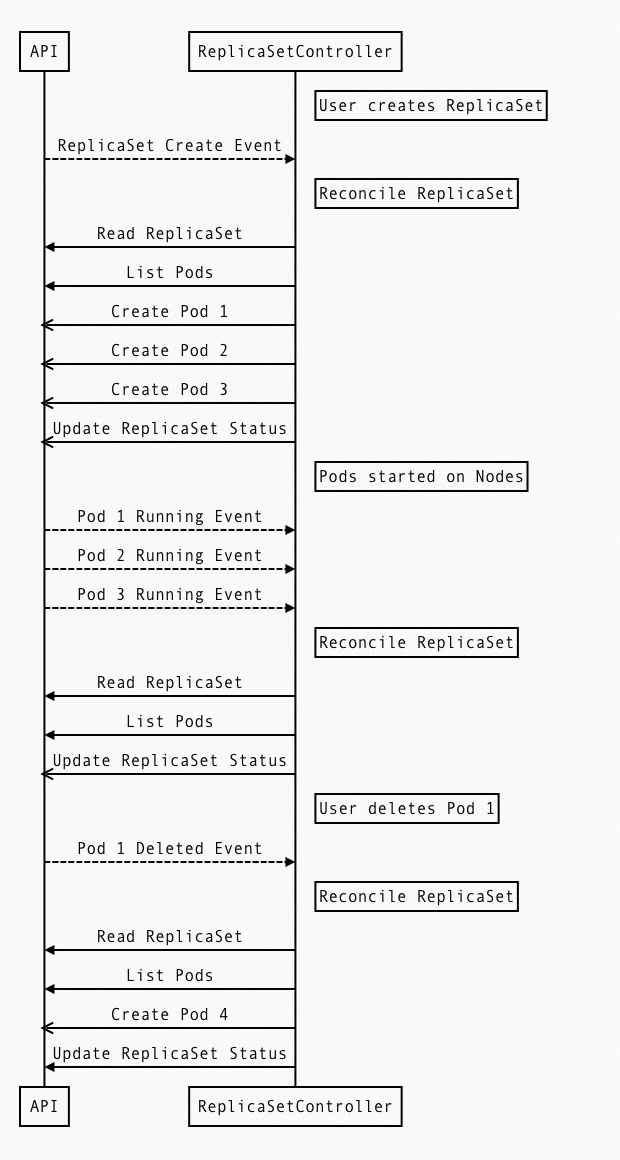
下图所示,就是用户创建一个3个副本的deployment的时候,ReplicaSetController所做的事情:
- List Pods感知Pod的数量
- 发现数量不一致的时候,开始创建/删除Pood
- 确保当前运行的Pod跟用户定义的一致
在Kubernetes中我们使用的Deployment,DamenSet,StatefulSet, Service,ConfigMap等这些都是资源,而对这些资源的创建、更新、删除的动作都会被称为为事件(Event),Kubernetes的Controller Manager负责事件监听,并触发相应的动作来满足期望(Spec),这种方式也就是声明式,即用户只需要关心应用程序的最终状态。但Kubernetes提供的资源,不能完全满足我们的需求,于是Kubernetes提供了自定义资源(Custom Resource)和K8s Operator为应用程序提供扩展。
K8s Operator和CR
Operator模式基于Kubernetes中的两个概念结合而成:自定义资源和自定义控制器。
自定义资源(Custom Resource)
在Kubernetes中,资源是Kubernetes API中的一个端点,用于存储一堆特定类型的API对象。它允许我们通过CRD向集群添加更多种类的对象来扩展Kubernetes。添加新种类的对象之后,我们可以像其他任何内置对象一样,使用kubectl 来访问我们自定义的API对象。
自定义控制器
Kubernetes的所有控制器,都有一个控制循环,负责监控集群中特定资源的更改,并确保特定资源在集群里的当前状态与控制器自身定义的期望状态保持一致。这种让关联资源的当前状态向期望状态迈进的过程叫reconcile。自定义控制器就是针对自定义资源的控制器,也称Operator。
Operator内部流程
生成Operator的代码的脚手架目前主要有两种,KubeBuilder和OperatorSDK,这里我们使用KubeBuilder生成的样例代码,进行介绍。
命令行如下:
// 初始化工程 kubebuilder init --domain my.domain --repo my.domain/demo // 创建API kubebuilder create api --group demo --version v1alpha1 --kind Mydemo // 创建Webhook kubebuilder create webhook --group demo --version v1alpha1 --kind Mydemo --defaulting --programmatic-validation
Operator代码结构简介
代码结构主体主要分为三部分:
- API定义与Webhook实现
- Operator安装部署所需的yaml定义
- 控制逻辑

代码里面最主要的需要实现的地方如下:
- CR字段定义与注册
mydemo_types.go:需要在MydemoSpec中定义资源所需的字段
// MydemoSpec defines the desired state of Mydemo type MydemoSpec struct { // INSERT ADDITIONAL SPEC FIELDS - desired state of cluster // Important: Run "make" to regenerate code after modifying this file // Foo is an example field of Mydemo. Edit mydemo_types.go to remove/update Foo string `json:"foo,omitempty"` } func init() { SchemeBuilder.Register(&Mydemo{}, &MydemoList{}) }
- webhook校验CR的接口
mydemo_webhook.go: ValidateCreate,ValidateUpdate和ValidateDelete函数分别可以进行资源创建、更新和删除时候的校验。
// ValidateCreate implements webhook.Validator so a webhook will be registered for the type func (r *Mydemo) ValidateCreate() error { mydemolog.Info("validate create", "name", r.Name) // TODO(user): fill in your validation logic upon object creation. return nil } // ValidateUpdate implements webhook.Validator so a webhook will be registered for the type func (r *Mydemo) ValidateUpdate(old runtime.Object) error { mydemolog.Info("validate update", "name", r.Name) // TODO(user): fill in your validation logic upon object update. return nil } // ValidateDelete implements webhook.Validator so a webhook will be registered for the type func (r *Mydemo) ValidateDelete() error { mydemolog.Info("validate delete", "name", r.Name) // TODO(user): fill in your validation logic upon object deletion. return nil }
- 控制逻辑实现:
mydemo_controller.go:Reconcile函数主要需要实现当前状态与目标状态的统一。对于K8s内部资源来说,比如Pod的数量,对于自定义资源来说,这个可能会跟第三方数据库中的资源绑定,比如对于Logtail来说,创建了一个CR,就等同于创建了一个采集配置,两个资源之间的统一性的处理,就需要在Reconcile函数中完成。
// Reconcile is part of the main kubernetes reconciliation loop which aims to // move the current state of the cluster closer to the desired state. // TODO(user): Modify the Reconcile function to compare the state specified by // the Mydemo object against the actual cluster state, and then // perform operations to make the cluster state reflect the state specified by // the user. // // For more details, check Reconcile and its Result here: // - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.12.1/pkg/reconcile func (r *MydemoReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { _ = log.FromContext(ctx) // TODO(user): your logic here return ctrl.Result{}, nil }
Operator内部处理流程

整体流程如下:
- Reflertor:reflector会执行Kubernetes List和Watch两种类型的API,从apiServer中获取资源对象以及监视变化的对象,然后将对象以及发生的事件放入DeltaFifo中。
- 先调用Kubernetes List API获得某种resource的全部Object,缓存在内存中
- 然后,调用Watch API 去watch这种resource,去维护这份缓存
- DeltaFifo:一个增量队列,是一个生产者-消费者模式的队列,Reflector是生产者,Informer是消费者。
- Informer:Informer会消费deltaFifo队列,获取对象,然后将最新的数据存储到线程安全的一个存储中以及调用资源事件处理器中的回调函数来通知controller进行处理。
- Indexer:Indexer就是存储 + 索引的组合,Indexer中包含了线程安全的存储,同时对存储创建了索引,通过该索引,可以加快数据的检索速度。
- ResourceEventHandler:资源事件处理器,是一个接口,里面定义了三个方法,OnAdd、OnUpdate和OnDelete,可以分别处理新增、更新和删除事件。Infomer从deltafifo中取出实例,根据实例发生的事件来对缓存中的数据进行更新,然后调用用户注册的资源事件处理器,放入workqueque中。
- workQueue:工作队列,由于事件产生的速度与我们进行处理的速度是不一致的,因此需要使用队列来进行缓冲。
- Reconcile:从workQueque中取出key后,可以从indexer中获取完整对象,然后进行一些处理。
Webhook
由第一部分代码简介得知,Operator内部除了对CR的操作之外,还有一部分数据针对CR的校验逻辑,就是通过webhook实现的。
Kubernetes中的Webhook主要分为两种:
- 验证性质的准入Webhook(Validating Admission Webhook),最主要的使用场景是在资源持久化到ETCD之前进行校验(Validating Webhook),不满足条件的资源直接拒绝并给出相应信息
- 修改性质的准入Webhook(Mutating Admission Webhook),最主要的使用场景是在资源持久化到ETCD之前进行修改(Mutating Webhook),比如增加init Container或者sidecar Container

Operator中使用到的Webhook主要还是验证性质的,作用就是校验对象的字段是否符合要求。当然修改性质的Webhook在Operator中也有非常好的应用场景,比如OpenTelmetery Operator中Sidecar模式的部署就是使用的就是通过Mutating webhooks来自动将OpenTelmetery Collector注入到Pod当中的。
Operator在开源采集器中的应用?
Fluent Bit && Fluentd
Fluent Bit使用c语言编写,配置主要包括input、filter、output等组件,主要特点是轻量性能高。fluentd使用ruby语言编写,最大特点是插件比较丰富,数据处理能力更强。
Fluent Bit |
Fluentd |
嵌入式Linux/容器/服务器 |
容器/服务器 |
C |
C & Ruby |
~650KB |
~40MB |
高性能 |
高性能 |
零依赖,除非一些特殊要求的插件。 |
基于Ruby Gem构建,依赖gem。 |
70左右 |
1000+插件 |
Apache License v2.0 |
Apache License v2.0 |
Fluent Operator
Fluent Operator是由KubeSphere社区于2021年捐献给Fluent社区的,最初是为了满足以云原生的方式管理Fluent Bit 的需求。Fluentbit Operator可以灵活且方便地部署、配置及卸载Fluent Bit以及Fluentd。同时, 还提供支持Fluentd以及Fluent Bit的插件,用户可以根据实际需求进行定制化配置。
Fluent Operator提供了多种部署模式供用户根据实际业务情况进行选择:
- Fluent Bit only模式:适用于采集日志后仅需要简单处理,即发送到第三方存储系统的场景。
- Fluent Bit + Fluentd模式:适用于采集日志后需要更高级处理,才发送到第三方存储系统的场景。
- Fluentd only模式:适用于以HTTP或Syslog等的方式接收日志,经过日志处理后,发送到第三方存储系统的场景。

Fluent Bit CRDs
Fluent Bit CRDs包含了如下几种类型:
- FluentBit: Fluent Bit DaemonSet配置定义。
- ClusterFluentBitConfig: 选择ClusterInput、ClusterParser、ClusterFilter、ClusterOutput,并生成配置存入Secret Config。
- ClusterInput: 集群粒度的Input插件配置。通过该插件,用户可以自定义采集的日志类型。
- ClusterParser: 集群粒度的Parser插件配置。通过该插件进行日志解析。
- ClusterFilter: 集群粒度的Filter插件配置。通过该插件进行日志的过滤。
- ClusterOutput: 集群粒度的Output插件配置。该插件主要负责将处理后的日志发送到第三方存储系统。
其中,每个ClusterInput、ClusterParser、ClusterFilter、ClusterOutput代表一个Fluent Bit配置段,之后Fluent Operator 根据ClusterFluentBitConfig的标签选择器进行选择。Fluent Operator将符合条件的CRD构建成最终的配置,并存入Secret Config中,最后挂在到Fluent Bit的DaemonSet中。

为了解决Fluent Bit不支持热加载配置的问题,添加了一个名为Fluent Bit watcher的包装器,用于检测到 Fluent Bit配置更改时立即重新启动Fluent Bit进程,而无需重新启动Fluent Bit的pod。

可以看到因为FluentBit是DaemonSet的部署模式,所以其配置都是集群粒度的。
Fluentd CRDs
Fluentd CRDs包含了如下几种类型:
- Fluentd: Fluentd Statefulset配置定义。
- FluentdConfig: 选择namespace粒度的ClusterInput、ClusterParser、ClusterFilter、ClusterOutput,并生成配置存入Secret Config。
- ClusterFluentdConfig: 选择集群粒度的ClusterInput、ClusterParser、ClusterFilter、ClusterOutput,并生成配置存入Secret Config。
- Filter: namespace粒度的Filter插件配置。
- ClusterFilter: 集群粒度的Filter插件配置。
- Output: namespace粒度的Ouptut插件配置。
- ClusterOutput: 集群粒度的Ouptut插件配置。
ClusterFluentdConfig为集群级别,具有watchedNamespaces字段,可以设置监听的namespace;如果不设置,则表示全局监听。FluentdConfig为namespace级别,只能监听所在的namespace的CR。通过ClusterFluentdConfig、FluentdConfig可以在namespace层面实现多租户日志隔离。
Logging Operator
Logging Operator是BanzaiCloud开源的一个云原生场日志采集方案,它整合了fluent社区的两个开源日志采集器FluentBit、Fluentd,以operator的方式自动化配置k8s日志采集pipeline。
CRD说明
- logging:定义了FleuntBit、Fleuntd的基础配置;可以指定controlNamespace和watchNamespaces。
下面是一个最简单的logging的CRD样例,controlNamespace绑定Fluentd和Fluentbit运行在logging这个namespace下,watchNamespaces指定日志只采集prod和test两个namespace。可以看到logging在namespace层面的隔离提供了相当高的灵活性。
apiVersion: logging.banzaicloud.io/v1beta1 kind: Logging metadata: name: default-logging-namespaced namespace: logging spec: fluentd: {} fluentbit: {} controlNamespace: logging watchNamespaces: ["prod", "test"]
- output:定义了namespace级别的日志输出配置。只有同一命名空间中的Flow才能访问它。
- flow:定义了namespaces级别的日志filters、outputs流。
- clusteroutput:定义了cluster级别的日志输出配置,相比output多了enabledNamespaces的字段用来控制不同namespace下的配置。
- clusterflow:定义了cluster级别的日志filters、outputs流。
这里output, flow, clusterouput以及clusterflow都是针对Fleuntd的配置,关于这几个之间的搭配关系,需要注意的一点:flow可以连接到output和clusteroutput,但clusterflow只能连接到clusteroutput。

Fluent Operator vs Logging Operator
- Logging Operator需要同时部署FluentBit和Fluentd,而Fluent Operator支持可插拔部署FluentBit与Fluentd,非强耦合,用户可以根据自己的需要自行选择部署Fluentd或者是FluentBit,更为灵活。
- 在Logging Operator中FluentBit收集的日志都必须经过Fluentd才能输出到最终的目的地,而且如果数据量过大,那么Fluentd存在单点故障隐患。FluentOperator中FluentBit可以直接将日志信息发送到目的地,从而规避单点故障的隐患。
- Logging Operator定义了loggings,outputs,flows,clusteroutputs以及clusterflows四种CRD,而FluentOperator定义了13种CRD。相较于Logging Operator,FluentOperator在CRD定义上更加多样,用户可以根据需要更灵活的对Fluentd以及FluentBit进行配置。
OpenTelemetry Collector
OpenTelemetry Collector致力于打造一个与厂商无关的统一的可观测数据采集器,用于接收,处理、输出观测数据,最大亮点是通过One Agent的形式实现了对Traces、Metrics和Logs的统一。使用OpenTelemetry Collector可以有效避免部署多个可观测采集器,支持对接各类开源可观测数据(例如Jaeger、Prometheus、Fluent Bit等)并统一发送到后端服务。

数据接收、处理和导出是采用Pipeline的形式。
Pipeline由三部分组成:Receivers用于接收数据;Processors负责处理数据;Exporters负责发送数据,定义了一条完整的数据流。Pipeline能够处理3种类型数据:Traces、Metrics和Logs。

一个Pipeline中可以有多个Receiver,每个Receiver接收的数据都会发送到第一个Processor中,并被后续Processor依次处理,Processor支持数据处理、过滤等能力,最后一个 Processor 使用fanoutconsumer将数据分发给多个Exporter,由Exporter发送到外部服务。
工作模式
- Agent 模式:将 OpenTelemetry Collector 作为本地 Agent 运行,接收来自业务进程上报的可观测数据,经处理后发送到后端服务。主机场景以守护进程形式部署,K8s 以 Daemonset 或 Sidecar 方式部署。

- Gateway 模式:OpenTelemetry Collector 作为网关实例运行,可以多副本部署及支持扩缩容。接收来自 Agent 模式的 Collector 或使用 Library 直接产生的可观测数据,或者由第三方在协议支持前提下发出的数据。

OpenTelemetry Operator 是OpenTelmetery项目遵循K8s Operator的实现。其主要功能有两点:
- 管控OpenTelmetery Collector
- 探针自动注入
CRD说明
CRD详细配置可以参考API文档,总的类型主要有两种:
- Instrumentation:主要指的是Opentelmetery Collector的探针的配置,可以自动注入探针和配置。
- OpenTelemetryCollector:直接部署OpenTelmetery Collector,同时设置Pipline的配置。
这两种CRD跟上面提到的OpenTelmetery的工作模式也是有关联的。
管控OpenTelmetery Collector
安装部署
下面这个样例yaml,将创建一个名为simplest的OpenTelemetry Collector实例,里面包含了Receiver,Processor和Exporter
kubectl apply -f - <<EOF apiVersion: opentelemetry.io/v1alpha1 kind: OpenTelemetryCollector metadata: name: otel spec: config: | receivers: otlp: protocols: grpc: http: processors: memory_limiter: check_interval: 1s limit_percentage: 75 spike_limit_percentage: 15 batch: send_batch_size: 10000 timeout: 10s exporters: logging: service: pipelines: traces: receivers: [otlp] processors: [] exporters: [logging] EOF
部署之后,可以看到Collector上被加上了一些标签,其中比较有作用的标签是:app.kubernetes.io/managed-by:opentelemetry-operator,这个标签会在后面升级管控中起作用。

升级管控
OpenTelemetry Operator会自动扫描带有"app.kubernetes.io/managed-by": "opentelemetry-operator"这个Label的Collector,如果发现Collector的版本不是最新版本,就会升级到最新版本。
可以通过.Spec.UpgradeStrategy参数控制当前Pod的Collector是否升级
- automatic-升级
- none-不升级
部署模式管控
通过.Spec.Mode参数,可以控制Collector的部署模式。Collector支持三种部署模式,DaemonSet, Sidecar, or Deployment(默认)。
DaemonSet和Deployment的部署方式比较简单,就是直接启动一个Pod
Sidecar模式比较特殊,可以看下如下Sidecar模式部署的样例:
kubectl apply -f - <<EOF apiVersion: opentelemetry.io/v1alpha1 kind: OpenTelemetryCollector metadata: name: sidecar-for-my-app spec: mode: sidecar config: | receivers: jaeger: protocols: thrift_compact: processors: exporters: logging: service: pipelines: traces: receivers: [jaeger] processors: [] exporters: [logging] EOF kubectl apply -f - <<EOF apiVersion: v1 kind: Pod metadata: name: myapp annotations: sidecar.opentelemetry.io/inject: "true" spec: containers: - name: myapp image: jaegertracing/vertx-create-span:operator-e2e-tests ports: - containerPort: 8080 protocol: TCP EOF
如果应用想要使用Sidecar模式部署Collector,那么
- 需要先定义好Sidecar的OpenTelemetryCollector对象,
- 应用需要添加一个annotation:sidecar.opentelemetry.io/inject(该注解可取值为true,false或者OpenTelemetryCollector的名字)
Operator在扫描到annotation为true的时候,会自动找到对应的OpenTelemetryCollector对象,并以该配置为业务Pod以SideCar的方式启动Collector。
探针自动注入
探针主要用在OpenTelemetry Collector的代理模式中,Collector作为一个接受加转发的角色,探针则是产生数据、发送数据的角色。
下面是一个Instrumentation配置的样例,exporter中定义了探针数据要发送的Collector的地址。
kubectl apply -f - <<EOF apiVersion: opentelemetry.io/v1alpha1 kind: Instrumentation metadata: name: my-java-instrumentation spec: exporter: endpoint: http://otel-collector:4317 propagators: - tracecontext - baggage - b3 java: image: ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-java:latest nodejs: image: ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-nodejs:latest python: image: ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-python:latest dotnet: image: ghcr.io/open-telemetry/opentelemetry-operator/autoinstrumentation-dotnet:latest env: - name: OTEL_RESOURCE_ATTRIBUTES value: service.name=your_service,service.namespace=your_service_namespace EOF
创建好Instrumentation之后,就需要在业务Pod中添加annotation,OpenTelemetry Operator会自动扫描带有特定annotation的Pod,然后自动注入探针以及相应的配置。annotation可以添加到namespce中,或者通过将添加至Pod中。
各个语言的annotation如下:
Java:
instrumentation.opentelemetry.io/inject-java: "true"
NodeJS:
instrumentation.opentelemetry.io/inject-nodejs: "true"
Python:
instrumentation.opentelemetry.io/inject-python: "true"
DotNet:
instrumentation.opentelemetry.io/inject-dotnet: "true"
SDK:
instrumentation.opentelemetry.io/inject-sdk: "true"
annotation的值可以有:
- "true":如果探针配置(Instrumentation)有加载namespace上,那么在pod中注解设置成true,即可注入该Instrumentation
- "false":不注入
- "my-instrumentation":当前namespce下的探针配置
- "my-other-namespace/my-instrumentation":其他namespce下的探针配置
Java应用实战
我们以一个Java应用为例:

添加annotation之后,查看业务容器的Deployment我们可以看到OpenTelemetry Operator主要做了这样几件事:
- 注入了一个initContainer,image使用的是Instrumentation中定义的java的image
- 将自己容器中的javaagent.jar拷贝到了/otel-auto-instrumentation目录中
- 将自己容器中的/otel-auto-instrumentation目录挂载了出去,从而使得业务容器也可以访问该目录下的jar包
- 业务容器中注入了几个OpenTelemetry的环境变量,其中JAVA_TOOL_OPTIONS是最关键的,该变量决定了业务进程启动的时候会运行javaagent


由此,业务容器重启之后,业务进程启动的时候,就会自动带上OpenTelemetry的Java Agent,从而开始产生和发送监控数据。
Operator在Logtail中的应用展望

AliyunLogController是Logtail下的K8s Operator的实现,主要功能有
跟Fluent的Operator以及Opentelemetery Operator相比,还有如下可以演进的功能点:
- namespace级别的配置隔离
AliyunLogController目前只支持一个CRD,且为集群级别的。比如一个集群,有多个团队在用,A团队用的是namespaceA,B团队用的是namespaceB,这种场景下,集群级别的CRD可能就不太适用。
- CRD数据字段的校验
需要引入Webhook机制,来对用户定义的CRD进行字段校验,有问题可以及时反馈给用户。
- Logtail安装部署的管控,尤其是sidecar模式的安装部署优化
目前Logtail的sidecar模式部署,还是需要用户手动创建安装部署模版,可以参考Opentelemetery Operator的实现,自动注入。
- 第三方组件以及探针管控
Logtail也正在不断对接第三方组件,以及一些开源的探针或者SDK(比如OpenTelemetry的探针和SDK以及Pyroscope的探针和SDK)等,Operator是一个比较好的进行统一管控的方案。

