1. 数据需求产生 
猿辅导成立多年,早期是基于关系型的 MySQL 数据库来做数据的需求。随着业务的发展,多个服务在一个 DB 去做数据的汇总,以及一些微服务架构的产生,使得数据逐渐走向分裂,很难在 MySQL 里完成统一的数仓。
因此在 2014 年,公司开始了统一数仓的建设,采用的是比较成熟的 Hadoop体系。虽然是用 Hive、MapReduce 做离线的批量的 ETL,但是为了保证用户交互足够快、延迟足够短,还是会把最终的应用层的数据放在 MySQL 里来做。包括现在很多离线需求也仍是这样一个链路。
随着公司业务的快速增长,以及一些新的业务形态的出现,以 MySQL 作为 BI 存储底座的瓶颈愈发明显。2020 年,新冠疫情爆发,公司业务出现了爆发式的增长,原本的离线T+1 的链路已无法满足业务上的数据需求。当时,我们做了很多实时的需求,有一条离线链路,一条实时链路,在应用层的存储上完成实时和离线的统一。为了应对不同的业务场景,又引入了很多新的 OLAP 引擎来做不同的需求。我们希望能够有一个引擎,可以完成在 AP 场景下的统一,这时就发现了 StarRocks。目前,除了自建的 一些 StarRocks 集群,我们也在跟阿里云团队合作,使用云上 EMR 的集群,是一个混合云多集群的的模式。
2. OLAP 选型
接下来介绍在 OLAP 选型时,我们考虑的一些点。
猿辅导 OLAP 支撑的场景,包括商业分析、广告转化、业务监控、还有一些用户触达等等,很多 BI 应用还是在用 MySQL 来做底座。所以需要去兼容原本 MySQL 的协议,也需要兼顾到查询的性能。我们的需求主要有八点:
- 亚秒级的数据查询延迟;
- 支持大宽表以及多表 join;
- 具备高并发的能力;
- 支持数据的流式和批式摄入;
- 支持标准化的SQL;
- 具备高性能的精准去重能力;
- 低的运维成本;
- 能够灵活地横向扩缩容,
- 并且对于业务是无感知的。

开源 OLAP 引擎分为 MOLAP 和 ROLAP,前者属于预计算方式,后者是关系型的模型,ROLAP 又可以分为基于 MPP 的和 DAG 的基于 Hadoop 底座的这部分。

我们对比了不同引擎的优缺点。可以看到 Spark、 Presto 、Trino 引擎,更适合去做批处理,做一些查询的加速,但是在并发的场景下,支撑的能力是不够的。Druid、Kylin 引擎,因为是构建于预计算的物化的能力,数据的重放的成本会非常高,同时对数据开发人员的要求也会相对较高。而 Doris 和 Clickhouse 的 MPP 架构的引擎,相比较下更能够满足当时的 BI 需求。考虑到运维的成本以及多样化的模型,当时选择了 Doris。随后又发现 Doris 跟 StarRocks 相比,性能上还是会有一些差别。
下图是我们当时做的一个Benchmark,主要是拿猿辅导内部的一些 BI 场景的SQL 来做了一个对比。可以发现当时 StarRocks 借助于它本身优秀的向量化引擎的能力,能够在大部分场景下比 Doris有 2 到 3 倍的性能提升(这里的性能主要指查询的延迟)。因此我们决定将更多的场景基于 StarRocks 来做。

3. StarRocks 的优势
StarRocks 最大的优势就是极致性能。主要得益于列存,高效的 IO,高效的编码的存储,丰富的索引加速(包括前缀索引、Bitmap倒排索引),物化视图的加速查询,全面的向量化,以及它的 MPP 的架构,通过并行执行中间结果不落盘的方式,能够让结果更快地跑出来,并且能够在集群规模扩大的时候带来性能的线性提升。
第二个优势是模型丰富。在猿辅导主要用到的是更新模型,目前在做的是把更多的场景逐渐往主键模型上过渡,因为我们的很多场景依赖于实时 CDC 的数据,它对 CDC 流有着更好的实时更新性能。另外,它原生的分区分桶设计架构,能够利用到数据的冷热的存储,能够利用分区裁剪的性能去更好地提升查询性能。
另外 StarRocks 也在快速迭代,经常能给我们带来很多新的特性。比如 CBO,对比原本在之前的查询优化和 CPU 的优化器,在一些的场景下,可以看到3 到 5 倍的性能提升。第二个是 Catalog,因为数据底层存在很多不同的数据引擎,所以希望在 Catalog 这一层能够去融合更多的数据,包括 Hive、MySQL、ES,以及 StarRocks 的其他集群,都可以在 Catalog 这层去做统一。第三是资源管理,可以用到 StarRocks 的资源管理的能力,做不同场景的大小查询的一个隔离,可以做到查询的熔断,可以在 CPU 、内存包括并发上做一些限制。另外一个是异步多表物化视图,这也是最近想去尝试的一个特性,跟现在一些场景下的演进有关系,希望把更多的逻辑通过物化视图来实现。
4. 业务场景和技术方案
下面介绍一些在公司内落地的场景。 首先来介绍一下整体的数据架构。

我们比较少用 StarRocks 来做数据计算,更多的还是将其作为数据应用的存储底座。
现在 StarRocks 最重要的一个场景,就是 BI 报表、多维分析的场景。

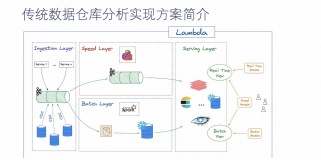
它还是一个 Lambada 架构,会有一些原始数据,比如业务 DB,有一些业务的日志埋点数据,实时这部分链路是 Kafka 到 Flink,最终到 StarRocks,是分钟级的数据;离线部分是 Hive 架构,主要是以天级和小时级的数据放到 StarRocks,上层去对接报表的应用。

上图是一个多维分析报表,它是基于后台写的一个 SQL,在前台的报表进行多维的分析。原本是用 MySQL 做 BI 报表的底座,但是在数据规模超到超过百万,遇到一些高技术维度、多维度的数据的时候,查询性能就会比较慢。所以用 StarRocks 替代 MySQL 来做多维分析,带来的提升非常明显。

上图也是一个 BI 的场景,是完全基于 StarRocks 做的一个指标平台。它是一个 NOSQL 的方案,会由数仓的同学首先去预先定义好一些维度和指标,用户在使用的时候,会先定义一个数据源,选择一些维度,选择一些指标,基于数据源再去生成一些单图,再把它做成看板。当用户自助地去生成一些图表的时,后台会转化成一个 SQL 来执行。

上图是一个简单的例子,上图左上角是定义一些维度表,左下角是指标的定义,包括其查询条件和计算方式。右边可以看到在实际执行的 SQL。这里的数据还是以离线数仓为主,因为需要对模型有一个明确的定义。

上图是一个用户的行为分析。主要是基于客户端的用户行为埋点数据。最早的时候,是通过 Druid 来做的, Druid 在时序化数据方面的性能还是非常不错的。但是有一些事情它做不了,比如对于一些复杂的查询,它本身能提供的算子是比较有限的。另外希望对维度数据能做一些组合,Druid 也是无法实现。所以我们用 StarRocks 把用户行为分析进行了重构。利用到 StarRocks 查询加速的能力,去给用户提供事件的聚合数据,能提供UserTrack 的一个能力。

它的链路也比较简单,会把埋点数据往 Kafka 里放一份,在 Flink 这一层去增加一些维度的信息,包括产品线、埋点的元数据。在 StarRocks 里会先尝试做一层明细表,按照天做分区,按照用户 ID 去做分桶。在 UserTrack 场景下,以用户维度去看这部分数据的时候,主要利用到分区分桶的能力,利用它的前缀索引和 Bloomfilter 过滤器,去实现快速地点查,以及高并发查询的要求。在事件分析的场景,主要是用到了小时的物化视图,去加速查询,利用 Bitmap 做精准的用户的去重计算,用 HLL 来做设备维度的模糊去重。

上图展示的是研发的一个监控看板,场景是实时采集引擎指标,进行数据分析,也有一些主题化定制的报表。数仓的粒度分得比较粗放,会放一层明细,有一些维度的数据,再做一些聚合。

值得一提的是,这套架构相对较复杂,因为有一部分数据是通过湖式的数据来做第一层数据接入,会先往 Iceberge 里存一次,中间通过 Spark 、 Flink 的引擎去计算,再往 StarRocks 里放,并且会在 Hive 和 StarRocks 去做数据的双写。
另外,互联网教育直播课堂有一个特点是它的波峰波谷特别明显,因为孩子们大部分是在同一个时间段上课,比如在周五下午上课,在上课的这两三个小时里面的数据量是非常爆炸的,平时的时候就没有什么流量。它带来的一个问题是,StarRocks 的表都是按照天、小时去做分区的,波峰时段的单个分区的数据就会非常多,分区里的 template 会非常大,那么在这个时候做compaction,对集群的性能消耗就会非常严重。所以这里做了一个自适应的处理,会去动态调整partition 的bucket,保证整个的查询性能能够保持在一个比较平稳的水平上。

上面是一个B端的业务后台,主要是给老师的一些数据看板,叫斑马数据看板。它主要是做督学看板、学情沟通,帮助老师去做学生上课情况的一些追踪,去做一些反馈。

它的特点主要是以小时的数据为主,也会有一些实时的用户行为的数据。这也是一个比较经典的链路,数仓的数据会放到 Hive 里,以小时级放到 StarRocks,直接透到业务的后台去查询。它几乎涵盖了目前斑马所有的业务场景,包括课程的体验、电商的增长,以及一些辅导的服务等等。

上面是猿辅导的一个 B 端的场景,是辅导老师工作台。它的特点是重度依赖于数仓的加工数据,大部分的数据源是由数仓同学先加工好的比较标准的数据,并且指标和维度都是经过明确定义的。

链路中,上面有一部分用到离线数仓的数据,也有一部分用到实时数仓的数据,这些数据还是通过天级、小时级、分钟级的粒度同步到 StarRocks 里。这里用到了 Catalog 做外表,因为对于分区裁剪的性能没有很高要求,数据量不大的情况下,通过 Catalog 外表能够更敏捷、更快速地在业务上使用仓库的数据。
上图中下边这条链路,叫 EtLT 的架构。第一个小 t 的 transform 里面做一些字段的裁剪、数据的过滤等非常轻的数据清洗和同步。把更多的数据计算逻辑放到 StarRocks 的下游,在 SQL 里是通过物化视图方式来做。它可以把业务的数据,主要是 MySQL 的数据,通过 CDC 数据同步到 StarRocks ,把更多的逻辑放到业务的后台。这样做的好处是可以在数据加工上大幅节省人力成本,能够让业务更快地去实验,更快地跑起来。

飞象星球是公司一个比较新的产品线,它是给学校以及政府教育相关部门提供的教育产品,飞象 BI 产品主要是把抽象化的数据通过可视化的报表提供给客户,它也是完全基于StarRocks 的底座来实现的。图中可以看到,除了一些可视化的能力以外,它还支持用户按照表和字段去定义后台的数据源模型,通过 NOSQL 的方式,让大家自己去配置数据看板。

它的链路相对来讲也比较简单,主要是业务 DB,先同步到 Hive 里,再同步到 StarRocks ,最近也在推动 CDC 同步的事情,希望未来能够完全实现从业务 DB 直接到StarRocks 的同步的方式,减少中间的链路。

最后一个案例是比较新的一个链路,它是一个电商场景,做用户支付成功率的监控,帮助电商的同学去做问题的排查。特点是实时性要求比较高,原本的业务 DB 的数据量非常大,业务的 DB 会做一些分库分表的架构,也有一些多表 Join 的需求,所以业务的数据是没有办法直接来做分析的。所以我们把它通过 CDC 的方式同步到 StarRocks 里,统一用 StarRocks 去处理。目前来看跑的效果非常好,由业务的研发同学直接来主导,不需要数据开发同学来介入。
5. 基础建设
再简单介绍一下我们做的基础建设。

我们有一些平台化的工具,比如统一的元数据、权限管理平台。还有一套 adHoc 平台,帮助用户做数据的分析和数据的提取。 DDL 工单系统,主要是帮用户去做数据的规范和权限的约束。另外,还有基于原生的系统去做监控大盘和告警,基于审计日志去做慢查询的监控,帮助用户持续优化查询性能。
目前正在推进中的工作包括,首先是从 UNIQ 模型去往 PRI 模型演进;第二是希望把 MySQL 到 StarRocks 同步的链路做得更轻、更快,通过一个平台化的工具把这条链路打通,能够实现离线的快照,也能够实现实时的同步;另外,因为整个 StarRocks 的集群非常多,大概有七八个集群,新的业务将会开更多的集群,所以需要有一些跨集群的数据同步的能力。
再来讨论一下自建和上云。如果仅从从机器层面来考虑,那么自建集群的成本是更低的。但如果结合人力和机器成本来看的话,阿里云EMR 则有一些优势。公司本身在大数据上的团队规模不是很大,大家要维护的组件和服务非常多, EMR 就能够提供一个比较好的协助和补充。首先是弹性的能力,当一些业务需要快速地去开一个集群,需要快速地去扩缩容的时候,可以利用到弹性的能力去实现,并且可以随时地去释放;另外,StarRocks 社区迭代非常快,我们在快速跟进和学习的过程中,难免会遇到一些问题,可能没有办法很快地得到社区的反馈,这时与阿里云的团队合作,就能够得到一个比较好的专家支持服务。现在我们是以自建和 EMR 集群混合云的模式,去支撑业务需求。对于一些业务上跑得比较快,尤其是一些 B 端的,隔离性要求非常高的场景,更倾向于在阿里云上直接开 EMR 的集群。

最近也在跟阿里云 EMR 合作去测试 Serverless- StarRocks 的产品。在新的产品形态下面能够提供给用户的,首先是诊断分析的能力,能够帮助用户可视化地去检索到慢 SQL,从而可以对 SQL 进行针对性优化。第二是它能够提供一个比较好的用户管理和权限管理的的能力,提升运维同学的工作效率。另外,也希望借助未来 StarRocks 3.0 以上存储分离的架构,节省更多的成本。
以上就是本次分享的内容,谢谢大家。
作者:申阳 猿辅导大数据平台团队负责人
EMR Serverless StarRocks 公测: 点此了解详情
我们会在钉钉群定期推送精彩文章,邀请技术大牛直播分享。
欢迎钉钉扫码加入产品交流群一起参与讨论~