Empirical Methods in Natural Language Processing (EMNLP)是由国际计算语言学协会(Association for Computational Linguistics, ACL)举办的自然语言处理和人工智能方面的重量级国际会议,历届会议都会受到全球各地人工智能领域人士的广泛关注。
近期,阿里巴巴达摩院语音实验室的论文“Speaker Overlap-aware Neural Diarization for Multi-party Meeting Analysis”被EMNLP 2022 主会长文接收。该论文展现了达摩院语音实验室在多方会议分析领域的最新成果,是对“如何有效建模说话人重叠”这一基础性问题的探索,接下来对其进行简要解读。
/作者:杜志浩,张仕良,郑斯奇,鄢志杰
论文地址:http://arxiv.org/abs/2211.10243
▏研究背景
在多方会议分析中,准确地识别出说话人的身份信息尤为重要。近期,研究者们提出了各种各样的说话人日志技术来解决这一问题,它们大致可以分为三类,分别是基于聚类的算法、端到端的模型化方法,以及这两者的混合系统。
图1:基于聚类的说话人日志技术流程图
基于聚类的说话人日志技术主要包括三个部分,分别是语音分割Segmentation、嵌入码提取Embedding Extraction和聚类算法Clustering Algorithm。其中较为关键的是聚类算法的选择,例如,K-means、谱聚类SC、多层次聚类AHC等。
此前,达摩院语音实验室对说话人日志中的聚类算法进行探索,提出了能够利用语音拓扑结构信息的社群检测聚类算法并被语音领域顶级会议ICASSP 2022接收,详情参见论文“Reformulating speaker diarization as community detection with emphasis on topological structure”[1]。然而,基于聚类的说话人日志技术存在两个问题,一是聚类算法多是无监督的,并没有直接最小化说话人识别错误;二是聚类算法通常建立在分段内说话人唯一这一假设上,无法应对重叠语音。
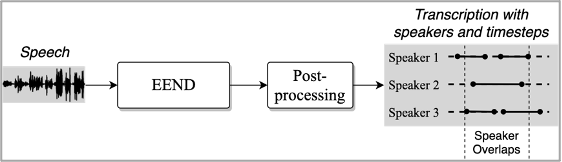 图2:端到端模型化说话人日志技术流程图
图2:端到端模型化说话人日志技术流程图
为解决这两个问题,端到端模型化的说话人日志技术(EEND)成为一个新的研究热点。在EEND中,说话人日志被建模成一个多标签预测(Multi-label prediction)任务,其模型的目标是对每个说话人单独预测一组二值化的标签,来代表该说话人是否在这一时刻存在语音活动。Fujita等人提出使用句子级置换不变损失(uPIT)来训练模型,这样能够直接最小化说话人识别错误,也能够应对语音重叠问题 [2]。虽然研究者们在端到端的模型上付出了很多努力,例如EEND-EDA [3]、RSAN [4]等,但由于uPIT的指数爆炸问题,EEND仍然很难应用在说话人数量较多的场景(大于4人)。此外,在处理较长的语音会议时,EEND对内存和长时建模能力也提出了难以满足的要求。
 图3:基于谱聚类和TSVAD的说话人日志混合系统
图3:基于谱聚类和TSVAD的说话人日志混合系统
为了兼顾长时会议的处理能力和重叠语音的建模能力,混合系统(Hybrid system)将聚类算法和基于神经网络的说话人日志模型相结合,是一种极具潜力的说话人日志技术。在现有的混合系统中,首先使用聚类算法对语音片段进行合并得到若干说话人的声纹信息(Speaker Profile),而后将这些声纹信息和语音片段一同送入目标说话人语音检测模块(TSVAD),分别对各个说话人的语音活动进行检测。
容易看出,不管是EEND还是TSVAD都将说话人日志任务建模为多标签预测问题(Multi-label prediction, MLP),通过单独对每个说话人的语音活动进行检测来隐含地处理语音重叠问题。这样的建模方式忽略了说话人之间的关联性,同时也缺少对重叠语音的显式建模。
针对这些问题,我们提出了一种全新的建模方式,即通过幂集编码将说话人日志任务建模为单标签分类问题(Single-label classification, SLC)。在SLC中,不同的说话人组合用一个唯一的幂集编码来表示,通过对幂集编码的预测来显示的建模说话人之间的关联性和语音重叠。除了在现有的TSVAD模型验证这种建模方式的有效性外,我们还进一步提出了Speaker Overlap-aware Neural Diarization(SOND)模型来更加充分地挖掘显示建模说话人重叠所带来的好处,接下来分别对这两点进行展开介绍。
▏基于单标签分类的说话人日志模型
 图5:三个人的幂集编码示例我们使用幂集(Power set,PS)来对说话人的组合进行编码,从能够显式的对说话人的语音重叠和关联关系进行建模。给定 N 个说话人 {1,2,...,N} ,它们的幂集 PS 定义为:
图5:三个人的幂集编码示例我们使用幂集(Power set,PS)来对说话人的组合进行编码,从能够显式的对说话人的语音重叠和关联关系进行建模。给定 N 个说话人 {1,2,...,N} ,它们的幂集 PS 定义为:
其中,φ表示空集,也就是没有任何说话人。从幂集的定义可以看出,其每个元素表示一种说话人组合,并且包含所有可能的组合。因此,我们将其中的元素看做分类类别,从而实现将说话人日志建模为单标签分类任务的目的。通过将多标签 yn,t 看做指示向量,我们可以得到幂集的唯一编码y~t:
使用幂集对 N 个说话人编码可能得到 2N 个可能的类别,当 N 较大时,这对模型建模来说很不友好。事实上,实际生活中很少出现N 个人同时说话人的情况,一般情况下只会有K(通常2至4人)个人同时讲话。结合实际情况,类别的数量可以大大缩减:

例如,在16人以下的中小型会议中,最多存在4个人同时讲话,那么模型需要建模的类别数从 216 锐减为1820类。图5给出了N=k=3 时幂集编码的示例。
▏建模说话人重叠的SOND模型
图6:建模说话人重叠的SOND模型
为了更好的建模说话人重叠,我们提出了Speaker Overlap-aware Neural Diarization(SOND)模型。如图6所示,SOND包括对语音信息进行编码的Speech encoder、对说话人信息进行编码的Speaker encoder、上下文依赖的打分器CD scorer、上下文无关的打分器CI scorer以及预测幂集编码的说话人混合网络SCN。
Speech encoder采用说话人识别任务中常用的ResNet34网络结构,并使用CN-Celeb和Alimeeting [5]等数据集进行预训练。与说话人识别任务不同的是,我们采用windowed statistic pooling来得到每个时刻的语音表示 :

Speaker encoder采用3层全连接网络来对说话人的声纹信息 v- 进行映射,使其与 ht在同一个特征空间。
上下文无关的打分器CI scorer通过对比目标说话人与训练集中其他说话人的不同来学习全局的说话人区分性,从而能够对目标说话人进行检测和追踪。在本文中,我们采用余弦相似度来估计说话人n在 t 时刻讲话的概率大小:

而上下文依赖的打分器CD scorer则通过对比目标说话人与上下文中其他说话人的不同来学习局部的说话人区分性,从而能够对目标说话人进行检测和追踪。我们采用基于多头自注意力(MHSA)的深度神经网络[6]来估计说话人 n 在整个上下文中讲话的概率大小:

在得到CI和CD打分之后,我们将其逐帧地拼接在一起,送入说话人混合网络SCN,来对不同的说话人组合进行建模。SCN包括对说话人组合建模的前馈映射和对序列上下文建模的记忆网络[7]:

我们将上述的网络结构多次堆叠提高模型的建模能力,并最终采用Softmax激活函数来对幂集标签进行预测:
▏实验结果
我们在AliMeeting数据集[5]上对所提出的方法和模型进行了验证。AliMeeting是达摩院语音实验室开源的、真实场景录制的多方会议语音,其训练集、验证集和测试集分别包含约104小时、4小时和10小时的数据,每段音频约15到30分钟。

表1:不同方法在Eval和Test上的DER (%)性能
如表1所示,与聚类方法VBx相比,我们的方法获得了极大的性能提升,这得益于我们的模型能够处理语音重叠问题,而VBx则不能。与其他基于神经网络的说话人日志方法相比,引入幂集编码PSE能够提升TSVAD模型对重叠语音的建模能力。而将SOND引入则能够进一步发挥SLC建模方式的优势,获得了最优的性能。

表2:SOND不同模块的重要性
此外,我们还进行了消融实验来评估SOND中每个模块的重要性。从表2可以看出,所提出的模块对最终的性能都有正向的帮助,其中上下文依赖的打分器CD scorer和说话人混合网络SCN的作用尤其明显,不可或缺。

表3:不同模型对说话人声纹信息准确性的依赖度
我们进一步评估了不同模型对说话人声纹信息准确性的依赖度。从表3可以看出,所提出的SOND对人声纹信息准确性的依赖程度更低,从理想(Oracle)声纹切换到聚类(Clustering)声纹,性能损失小于TSVAD模型,而SOND对声纹信息的鲁棒性则主要得益于说话人编码器Speaker encoder和上下文独立打分器CI scorer的引入。
▏Future Work
本文提出的SOND的代码和模型近期会在ModelScope开源,欢迎大家前往达摩院模型开源社区ModelScope体验多种语音AI模型。社区官网链接:modelscope.cn

参考文献:
[1] Siqi Zheng and Hongbin Suo. 2022. Reformulating speaker diarization as community detection with emphasis on topological structure. In ICASSP.
[2] Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Kenji Nagamatsu, and Shinji Watanabe. 2019a. End-to-end neural speaker diarization with permutation-free objectives. In INTERSPEECH, pages 4300–4304.
[3] Shota Horiguchi, Yusuke Fujita, Shinji Watanabe, Yawen Xue, and Kenji Nagamatsu. 2020. End-to- end speaker diarization for an unknown number of speakers with encoder-decoder based attractors. In INTERSPEECH, pages 269–273.
[4] Keisuke Kinoshita, Lukas Drude, Marc Delcroix, Tomohiro Nakatani. 2018. Listening to Each Speaker One by One with Recurrent Selective Hearing Networks. In ICASSP, pages 5064-5068.
[5] Fan Yu, Shiliang Zhang, Yihui Fu, Lei Xie, Siqi Zheng, Zhihao Du, Weilong Huang, Pengcheng Guo, Zhijie Yan, Bin Ma, Xin Xu, and Hui Bu. 2022a. M2met: The icassp 2022 multi-channel multi-party meeting transcription challenge. 6171. IEEE.
[6] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NIPS, pages 5998–6008.
[7] Shiliang Zhang, Ming Lei, Zhijie Yan, and Lirong Dai. 2018. Deep-fsmn for large vocabulary continuous speech recognition. In ICASSP, pages 5869–5873. IEEE.

