第三章、数据存储与检索
笔者按:
- Format:单纯的格式,有 txt、parquet、orc;hudi有点类似格式组件;有行存列存,更有一些行列混合;一般是计算引擎可以直接使用或者生成的。
- StorageEngine:加一些集成,支持细粒度的写入、查询,如 innodb,RocksDB,HFile等;
- StorageService:再进一步就是套上分布式管理,有查询模型(SQL&JSON),容灾管理等存储服务,如:MySQL、HBase等
其本身理论万变不离其宗,一个是以B-trees在关系型应用比较广的原地更新派,一个是LSM的日志结构再合并的流派。
本章节主要探求单机存储引擎的结构。
3.1、索引
索引是基于原始数据派生出来的额外的数据结构。
3.3.1、Hash索引:
一般以Key、Value为主,Key为索引可以全部存储在内存中,比如Bitcask系统;
系统一般还需要考虑删除记录、崩溃恢复、并发控制(可以一个线程写)等问题。
缺点:
- 区内查询性能不高;
- Hash一般在内存维护,在磁盘维护代价很高;
- Hash变满时,Hash冲突时间需要复杂的逻辑;
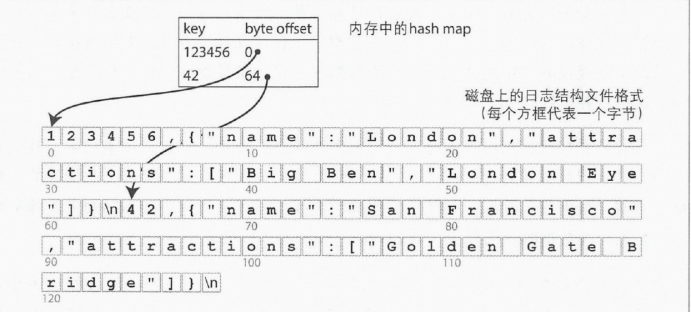
Value可以追加分段写在磁盘中,分段后可以合并。

3.3.2、SSTables与LSM-Tree
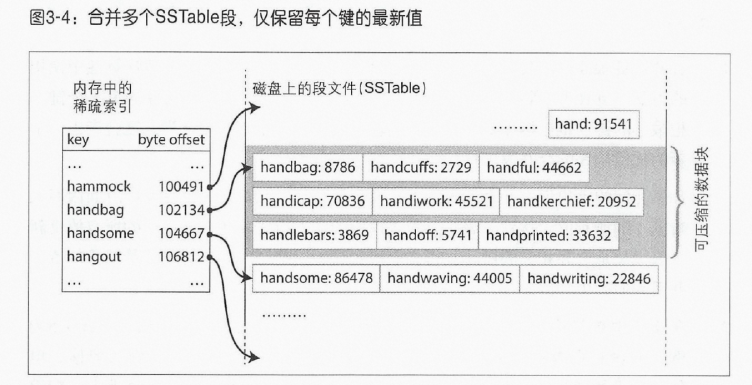
- 把Key与Value一起存入磁盘中,在内存中维护稀释索引;
- LSM-Tree存储引擎:基于合并和压缩排序文件原理的存储引擎;代表:RocksDB、LevelDB、HBase、Cassandra等
- 基本写读的基本顺序:
- 当写入时,将其添加到内存中的平衡树数据结构中(列如红黑树)。这个内存中的树有时被称为内存表。
- 当内存表大于某个闹值(通常为几兆字节)时,将其作为SSTabl e文件写入磁盘。
- 为了处理读请求,首先尝试在内存表中查找键,然后是最新的磁盘段文件,接下来是次新的磁盘段文件,以此类推,直到找到目标(或为空)。
- 后台进程周期性地执行段合并与压缩过程,以合并多个段文件,并丢弃那些已被覆盖或删除的值。
- Lucene全文索引比keyvalue索引复杂一些,其字典也是采取了类似的LSM-Tree的方案;
- 性能优化:隆过滤器 判断不在,则可以快速返回;另外可以分层压缩,基于大小、新旧等不同的compation压缩算法;
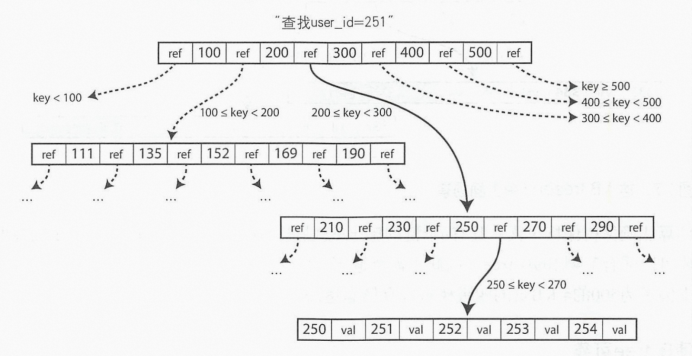
3.3.3、B-trees
最为常见的索引方式,开始于1970年代;几乎是所有的关系型数据库的标准实现;具有n个键的B-tree总是具有O ( log n ) 的深度。
B-tree 底层的基本写操作是使用新数据覆盖磁盘上的旧页。它假设覆盖不会改变页的磁盘存储位置, 也就是说, 当页被覆盖时,对该页的所有引用保持不变。与 LSM-tree追加文件形成鲜明的对比。
为了让其从破溃中恢复,也可以写预写日志( write-ahead-log, WAL ),也称为重做日志。
LSM |
B-trees |
Hash索引 |
|
描述 |
数据在磁盘 内存有稀释查询表 |
数据在磁盘 |
key在内存,value在磁盘 |
代表引擎 |
RocksDB&LevelDB |
MySQL-innodb |
Bitcask |
查询性能 |
mlog(n) |
log(n) |
O(1) |
写入性能 |
O(1)+m |
log(n)+m |
O(1) |
空间(压缩算法) |
更好支持压缩,结构紧凑 |
有碎片 |
更好支持压缩,结构紧凑 |
影响响应时间 |
由于compactor,对IO消耗较高 99.9% 时间不稳定 |
比较稳定 |
比较稳定 |
故障恢复 |
WAL |
WAL |
|
事务支持 |
支持比较复杂 由于keyvalue存在多个io块,需要从上层加锁来实现 |
这些锁可以直接定义到树中,比较容易实现 |
3.3.4、其它索引
- 二级索引:可以容易地基于Keyvalue索引来构建;
- 聚集索引(在索引中直接保存行数据)和非聚集索引(仅存储索引中的数据的引用);
- 多列索引:如果需要同时查询表的多个列;
- 级联索引:它通过将一列追加到另一列,将几个字段简单地组合成一个键;
- 多维索引:在地理信息查询比较常见,使用空格填充曲线将二维位置转换为单个数字;
- 全文搜索和模糊索引:全文搜索引擎通常支持对一个单词的所有同义词进行查询,井忽略单词语毯上的变体,在同一文档中搜索彼此接近的单词的出现, 井且支持多种依赖语言分析的其他高级功能;
3.3.5、在内存中保存所有内容
在内存中保存所有的数据,查询与写入性能是最高的。但存储空间与故障恢复是挑战点。
如Memcached/Redis缓存版本是全部hold在内存的,可以丢失数据。
如RAMCloud/Redis持久化版本是部分数据存在磁盘的,有故障恢复的机制。
non-volatile memory是未来一个新的研究领域。
3.2、事务处理与分析处理
3.2.1、区别
类型 |
OLTP |
OLAP |
主要读特征 |
基于健,每次查询返回少量记录 |
对大量记录进行汇总 |
主要写特征 |
随机访问,低延迟写入 |
批量写入或者事件流 |
电信使用场景 |
终端用户,通过网络应用程序 |
内部分析师,为决策提供支持 |
数据表征 |
最近的数据状态 |
随着时间的变化的所有时间历史 |
数据规模 |
GB到TB |
TB到PB |
3.2.2、流程
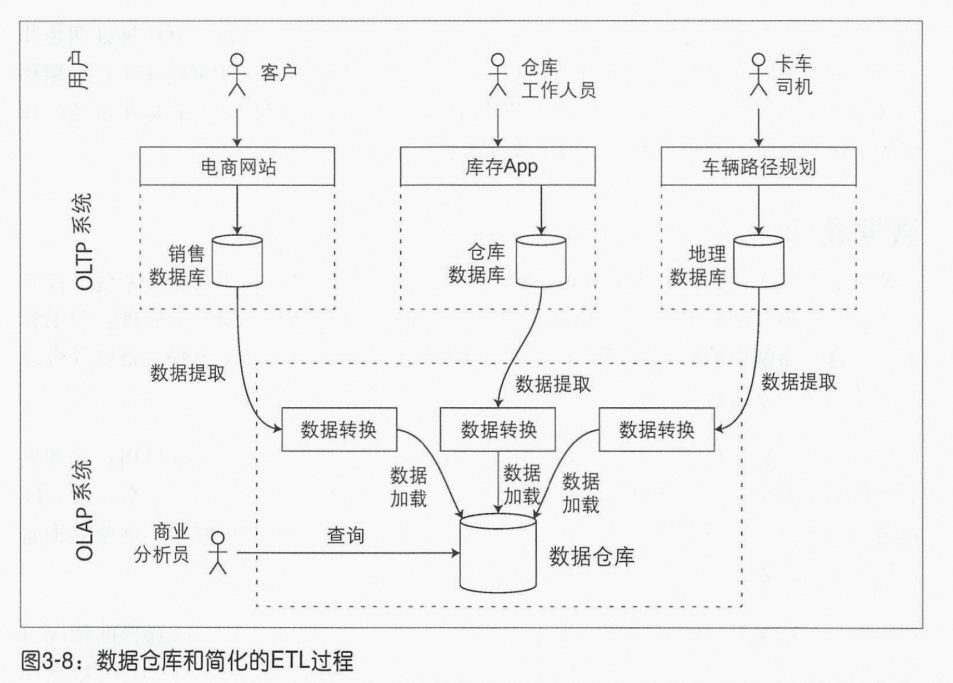
一些数据库(Microsoft SQL Server和SAP HANA ) 在同一产品中支持事务处理和数据仓库。然而,它们越来越成为两个独立的存储和查询引擎,这些引擎恰好可以通过一个通用的SQL界面进行访问;
3.2.3、星型与雪花型分析模式
星型模式:事实表位于中间,被一系列维度表包围,这些表的连接就像星星的光芒。该模板的一个变体称为雪花模式,其中维度进一步细分为子空间。雪花模式比星型模式更规范化,但是星型模式通常是首边,主要是因为对于分析人员,星型模式使用起来更简单。一般数仓中,事实表可能会超过百列。
3.3、列式存储
- 面向列的存储,将每列中的所有值存储在一起。Parquet是基于Google的Dremel的一种支持文档数据模型的列存储格式。
- 面向列的存储非常适合压缩。
- HBase与Cassandra是面向列族,并非面向列,其本质还是面向行的。
- 列存储中的排序可以获得很多的压缩效果,一般针对前几列进行排序。
- 列存储的写操作:一般采取LSM的写入方式,在内存中排序号,写入磁盘。查询时,检查磁盘的列数据和内存中最近写入的数据。
3.3、聚合:数据立方体与物化视图
数据仓库查询通常涉及聚合函数,例如SQL 中的COUNT 、SUM 、AVG 、MIN或MAX。可以提前构建一些聚合的缓存,要么存在磁盘,要么存在内存之中;变种有类似的数据立方体,可以把每个维度的聚合构建出来。这样查询就相对非常快。最简单的就是把每个表的count构建出来。