前话:
最近基于LLM的AIGC应用涌现,大家都在探索如何快速利用LLM去构建自己业务领域的应用。我们早前做了LLM应用框架这方面的一些调研,发现有一款LLM开发框架Langchain在开源社区异常火爆,短短5个月的时间已经达2w+star。于是我们针对该框架做了系统性的调研梳理,并沉淀到了语雀文档,当时只是为了方便团队成员理解和快速做业务Demo。最近有很多同学搜到了这篇调研文档,频繁要求帮忙开下文档权限,于是我就将该调研文档发在ATA,方便大家查阅。(注:些文章基于个人和团队成员对LLM的精浅理解,如果有误还望指出)
1. 什么是LangChain
LangChain是一个基于大型语言模型(LLMs)构建应用的框架。它可以帮助你实现聊天机器人、生成式问答、文本摘要等功能。它的核心思想是可以将不同的组件“链接”起来,创建更高级的LLMs应用.
核心关键词: LLM 编程框架(也叫模型编排工具:Tooling Orchestration)

1.1 现有的NLP的技术栈
NLP 开发人员都一直依赖于传统优化 NLP 任务的技术栈,如
-
文本分类 (text classification)
-
命名实体识别 (Named Entity Recognition)
-
命名实体消歧 (Named Entity Disambiguation)
这种技术栈通常由数据预处理管道(data preprocessing pipeline)、机器学习管道(machine learning pipeline)和各种存储嵌入和结构化数据的数据库组成。

.2 新兴的大语言(LLM)技术栈
与之前的技术栈相比,该技术栈着重于实现文本生成——与早期的机器学习模型相比,现代 LLM 最擅长这项任务。宏观来说,新的技术栈由四个主要部分组成:
-
数据预处理管道(data preprocessing pipeline)
-
嵌入终端(embeddings endpoint )+向量存储(vector store)
-
LLM 终端(LLM endpoints)
-
LLM 编程框架(LLM programming framework)

1.3 旧的技术栈和新的技术栈之间有几个很大的不同之处:
-
首先,新的技术栈 不那么强依赖存储结构化数据的知识图谱 (如三元组),因为诸如 ChatGPT、Claude 和 Flan T-5 等 LLM 比早期的 GPT 2 等模型编码了更多的信息。
-
第二,较新的技术栈 使用现成的 LLM 终端(LLM endpoint)作为模型,而不是定制的 ML 管道(ML pipeline)(至少在刚开始时)。 这意味着今天的开发人员花费更少的时间来训练专门的信息提取模型(例如命名实体识别、关系提取和情感分析),并且可以在比较少的时间(和成本)内启动解决方案。
2. LangChain的主要功能及模块
Langchain提供的主要功能

LangChain提供的主要模块:
-
Prompts: 这包括提示管理、提示优化和提示序列化。
-
LLMs: 这包括所有LLMs的通用接口,以及常用的LLMs工具。
-
Document Loaders: 这包括加载文档的标准接口,以及与各种文本数据源的集成。
-
Utils: 语言模型在与其他知识或计算源交互时往往更强大。这可以包括Python REPLs、嵌入、搜索引擎等。LangChain提供了一大批常用的工具。
-
Indexes: 语言模型在与自己的文本数据结合时往往更强大 - 这个模块涵盖了这样做的最佳实践。
-
Agents: Agents涉及到一个LLM在选择要执行的动作、执行该动作、看到观察结果,并重复这个过程直到完成。LangChain提供了代理的标准接口,可供选择的代理,以及端到端代理的示例。
-
Chat: Chat模型是一种与语言模型不同的API - 它们不是处理原始文本,而是处理消息。LangChain提供了一个标准接口来使用它们,并做所有上面提到的事情。
2.1 LLMs 和 Prompts
2.1.1 名词解释
-
LLMs: 这包括所有LLMs的通用接口,以及常用的LLMs工具。
-
Prompts:Prompts是一种用于生成文本的模板,可以在训练LLMs时使用。Prompts可以是单个句子或多个句子的组合,它们可以包含变量和条件语句。Prompts是训练LLMs的重要组成部分,因为它们可以帮助模型学习特定领域的语言和知识。
2.1.2 功能
通过管理 Prompt、优化 Prompt与LLM交互,可以以各种方式自定义prompt。 

其他用法:
-
Dyanamic Prompts 可以检查 Prompt 的长度,然后调整 few-shots 给出的示例数量
-
Example Generation 可以检查 Prompt 里 token 数量还有剩余的话就再多生成些示例
2.2 Chain
2.2.1 名词解释
Chains:Chains是一种将多个代理连接在一起的工具,以实现复杂的任务。Chains可以包含多个代理,每个代理都执行一个特定的任务,并将结果传递给下一个代理。Chains还可以与Prompts、Indexes和Memory一起使用,以实现更复杂的任务。
2.2.2 功能
chain将 LLM 与其他信息源或者 LLM 给连接起来,比如调用搜索 API 或者是外部的数据库等。LangChain 在这一层提供了与大量常用工具的集成(比如上文的 Pincone)、常见的端到端的 Chain。
LangChain 封装的各种 Chain 已经非常强劲,一开始 300 页 PDF 的案例中用到的是它的 QA Chain.
举例:SelfAskWithSearchChain

2.3 Agent
2.3.1 名词解释:
Agents是一种使用LLMs做出决策的工具,它们可以执行特定的任务并生成文本输出。Agents通常由三个部分组成:Action、Observation和Decision。Action是代理执行的操作,Observation是代理接收到的信息,Decision是代理基于Action和Observation做出的决策。Agents还可以与Prompts、Indexes、Memory和Chains一起使用,以实现更复杂的任务。
2.3.2 功能
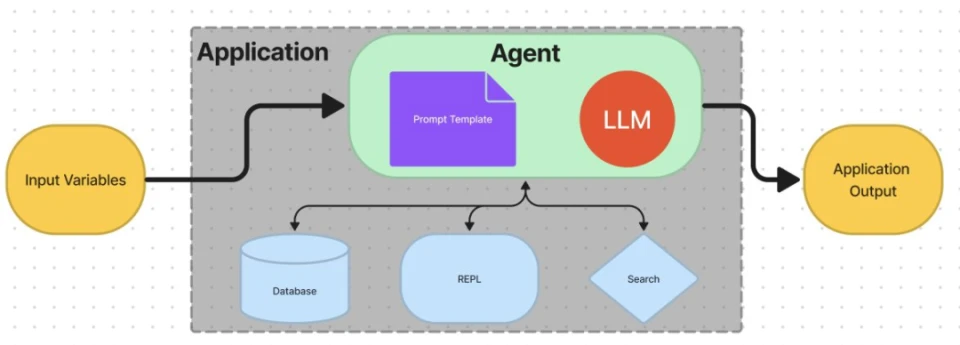
作为 Agent 的 LLM 深度体现了思维链的能力,充当了交通指挥员或者路由者的角色。Agent 封装的逻辑和赋予 LLM 的“使命”比 Chain 要更复杂。在 Chain 里,数据的来源和流动方式相对固定。而在Agent 里,LLM 可以自己决定采用什么样的行动、使用哪些工具,这些工具可以是搜索引擎、各类数据库、任意的输入或输出的字符串,甚至是另一个 LLM、Chain 和 Agent。
2.4 Memory
2.4.1 名词解释
Memory是一种用于存储数据的工具,它可以帮助代理在多次调用之间保持状态。Memory可以存储任何类型的数据,并且可以与Prompts、Indexes、Chains和Agents一起使用。
2.4.2 功能
类chatgpt的session功能,用于存储每个session问题的上下文信息。


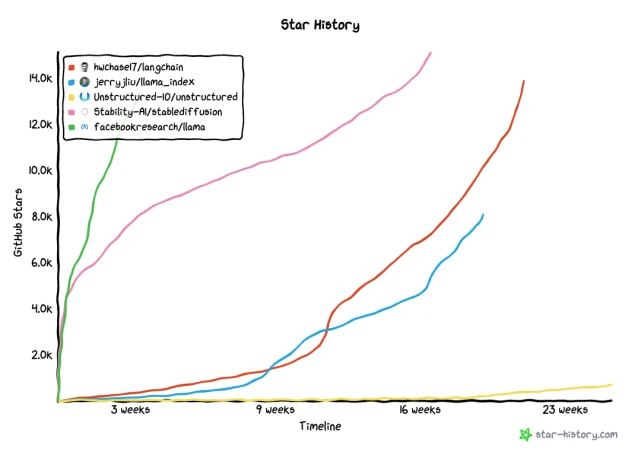
LangChain 是目前 LLM 领域最热门的开源项目之一,从下面可以看出今年以来的曲线和绝对 Star 数跟最热门的开源模型 LLama 相比也不遑多让,发布不到 5 个月已经拥有了超过 1 万个 Github Star。
2.1 LangChain的相关文档
-
LangChain官方文档: https://langchain.readthedocs.io/en/latest/index.html
-
LangChain GitHub仓库: https://github.com/hwchase17/langchain
-
LangChain Blog: https://blog.langchain.dev/
3. LangChain应用场景
LangChain可以用来实现以下几种应用:
-
特定文档的问答。例如,从Notion数据库中提取信息并回答用户的问题。
-
聊天机器人。例如,使用Chat-LangChain模块创建一个与用户交流的机器人。
-
代理。例如,使用GPT和WolframAlpha结合,创建一个能够执行数学计算和其他任务的代理。
-
文本摘要。例如,使用外部数据源来生成特定文档的摘要。
3.1 文本摘要功能
相关文本摘要的资料
-
LangChain文本摘要教程: https://www.pinecone.io/learn/langchain-prompt-templates/
3.2 特定文档问答
3.2.1 Pdf文本阅读问答:
-
LangChain向量数据库问答示例: https://kleiber.me/blog/2023/02/25/question-answering-using-langchain/
3.2.2 PDF读取问答流程
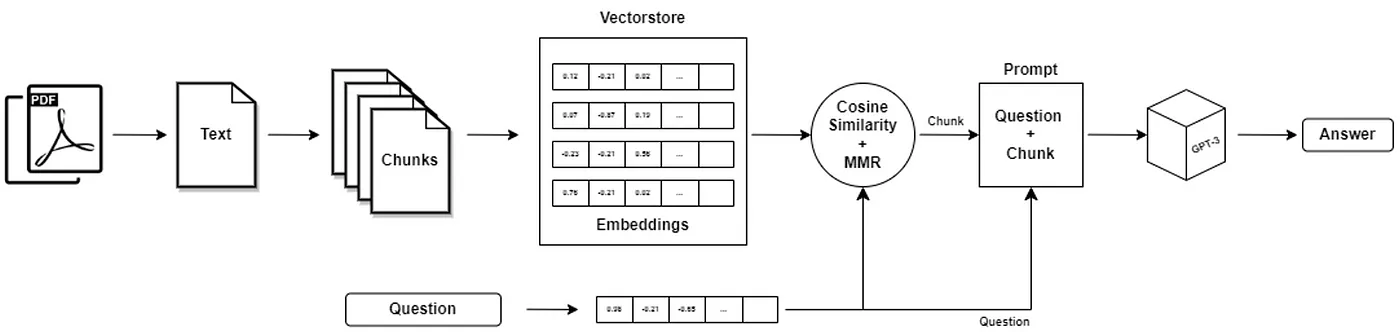
3.2.3 Pdf相关读取问答相关库
-
kaixindelele /ChatPaper
4. LangChain竞品
这些框架的目的是为 LLM 交互创建一个底层编排引擎,并通过 API 进行呈现
名称 |
语言 |
时间 |
文档 |
优缺点 |
LangChain |
Python Js/Ts |
2022.11 |
优点:提供了标准的内存接口和内存实现,支持自定义大模型的封装。 缺点:评估生成模型的性能比较困难。 |
|
Dust.tt |
Dust |
优点:提供了简单易用的API,可以让开发者快速构建自己的LLM应用程序。 缺点:文档不够完善。 |
||
Semantic-kernel |
TypeScript |
2023.3 |
优点:轻量级SDK,可将AI大型语言模型(LLMs)与传统编程语言集成在一起。 缺点:文档不够完善。 |
|
Fixie.ai |
Python |
优点:开放、免费、简单多模型(images, audio, video, binary, JSON,) 缺点:paas平台,需要在平台部署 |
||
Cognosis |
TypeScript |
优点 缺点:没啥资料 |
||
GPT-Index |
Python |
专注数据层。处理外部数据跟LLM连接的接口。 |
4.1 Dust.tt
Dust 是一个围绕大型语言模型(LLMs)构建的框架,它提供了一个基于 Web 的 GUI,用于配置块并将这些块串联或并联。与 LangChain 类似,Dust 的目的是为 LLM 交互创建一个底层编排引擎,并通过 API 进行呈现。
LangChain 和 Dust 都可以用于聊天机器人、生成式问答(GQA)、摘要等等。这两个框架的核心思想都是我们可以将不同的组件“链接”在一起,围绕 LLMs 创建更高级的用例。
Dust.tt 是最早的开源人工智能框架之一。 它是用 Rust 编写的,允许开发人员使用其他工具链接调用 LLM,以提取所需的输出。 Dust.tt 使用 OpenAI、AI21 和 Cohere 等语言模型,并具有用于 Google 搜索、curl 和网络抓取(包装 browserless.io)的集成块。
关键概念:Dust.tt 应用程序包含一系列按顺序执行的块。 每个块都会产生输出,并且可以引用先前执行的块的输出。 Dust.tt 应用程序开发人员定义每个块的规范和配置参数。
4.2 Semantic Kernel
Semantic Kernel 是一个轻量级的 SDK,它可以让您轻松地将传统编程语言与最新的大型语言模型(LLM)AI“提示”混合使用,具有模板、链接和计划功能。它提供了一种灵活地将 LLM AI 集成到现有应用程序中的方法。
-
详细调研文档参考: https://yuque.antfin-inc.com/zur0oy/data-operation/urf0o7gdwgvvgan7?singleDoc#《语义内核(semantic-kernel)调研》
4.3 GPTIndex
GPTIndex是一款基于GPT模型的文本索引工具,可以实现快速高效的文本搜索和匹配。使用GPTIndex,您需要首先准备好需要索引的文本数据,并将其导入到GPTIndex中进行处理和索引。接着,您可以使用GPTIndex提供的API接口,对索引进行查询和搜索,以实现各种文本处理和分析任务。GPTIndex具有高效的搜索速度和准确度,适用于各种文本数据处理和分析场景,如文本分类、关键词提取、实体识别等。
4.4 Fixie.ai

Build natural language agents that connect to your data, talk to APIs, and solve complex problems。We're a cloud-based platform-as-a-service that allows developers to build smart agents that couple LLMs with back-end logic to interface to data, systems, and tools.
一个LLM的自动化平台。Fixie.ai是一个用于构建、托管和扩展智能代理的平台,可以通过连接到个人数据源、系统和工具来扩展llm的功能。首先他是一个PAAS平台,在这个平台上你可以构建了自己的人工智能代理,并将它们与不同的api或数据流集成。
4.4.1 demo
-
step(1) Installing the Fixie CLI
-
step(2) Building agents locally
-
step(3) Deploying agents
Deploying agents will automatically upload your agent to the Fixie cloud and start serving it immediately on the platform.
4.6 LlamaIndex
LlamaIndex是外部数据和 LLM 之间的一个简单、灵活的接口。可以实现为您现有的数据源和数据格式(API、PDF、文档、SQL 等)提供数据连接器。为您的非结构化和结构化数据提供索引,以便与 LLM 一起使用。
-
以易于访问的格式存储上下文以便快速插入。
-
当上下文太大时处理提示限制。
-
处理文本拆分。
-
为用户提供查询索引(输入提示)并获得 知识增强输出的界面。
-
为您提供全面的工具集,权衡成本和性能。
使用LlamaIndex可以根据自己的数据建立自己的问答聊天机器人。LlamaIndex做的其实就是使用一种算法来搜索文档并挑选出相关的摘录,然后只将这些相关的语境与我的问题一起传递给GPT模型。
4.6.1 原理
LlamaIndex所做的是将你的原始文档数据转换成一个矢量的索引,这对查询来说是非常有效的。它将使用这个索引,根据查询和数据的相似性,找到最相关的部分。然后,它将把检索到的内容插入到它将发送给GPT的prompt中,这样GPT就有了回答你问题的背景。
4.6. 2 工作工程
-
用LlamaIndex为你的文档数据建立一个索引;
-
用自然语言查询该索引;
-
LlamaIndex将检索相关部分并将其传递给GPT prompt;
-
向GPT询问相关的上下文并构建一个回应;
简单说就是,LlamaIndex将接受你的prompt,在索引中搜索相关的块,并将你的prompt和相关块传递给GPT
5. 其他
5.1 LLM应用模式对比
LLM使用模式 |
方法 |
优点 |
缺点 |
直接使用 |
框架+LLM+自有数据 |
应用快 |
效果差 |
微调或重训练 |
LLM用自有数据fine Tuning |
效果好 |
成本高 |
-
模式一:通过LLM 编程框架,将自有数据与预训练的 LLM 相结合;
-
从好的方面来说,即开即用,应用落地速度非常快,落地时间小时级;
-
坏的方面来说,效果较差,难以在要求比较高的垂直场景使用
-
模式二:在自有数据上对 LLM 进行微调;
-
从好的方面来说,它减少了对这种编排的逻辑,直接调用即可;
-
坏的方面来说,它的成本和时间花费都比较高,而且需要定期进行调整以保持更新;
5.2 未来的看法
5.2.1 未来公司的三种走向:
-
Level1:大模型模型底座的基础设施公司 --- 类比一个拥有比较强通用能力的人
-
Level2:基于大模型底座结合场景进行商业化应用的公司(以应用为主,没有微调) --- 类比通用能力的人去一些场景打工挣钱
-
Level3:基于大模型底座+领域场景数据微调形成更强领域能力的产品商业化并持续形成数据闭环 --- 类比一个领域专家
5.2.2 未来的工作状态:
-
Level1的公司:大厂负责预训练模型底座的公司,首先肯定是积极的拥抱新范式,复现ChatGPT工作。其次,显然这个通用的模型离最后的AGI还有距离,未来还有很多问题:
-
效果上:大模型的持续更新,大模型生成时能否引入fact reference实现更好的事实性回答等等。
-
成本上:训练和推理的成本都非常高,尤其是推理上,降低推理成本等等。
-
Level2的公司:如果你是原本在负责自己公司上的一些NLP任务的研发。
-
首先大概率一时半儿会不用那么担心失业,OpenAI的API很贵,大概500汉字要0.14元(prompt+answer),所以你的场景全部的任务都用可能不一定划算,但是建议还是要积极拥抱,看看是否在高价值的场景可以引入,积极创造价值。其次,多关注下外部开源的大模型上的finetune,10B的模型的训练、推理等技术和1B及以内的技术差别很大(单卡放不下的模型),开源的国内的清华唐杰老师的GLM模型效果不错,其他开源的也可以关注,虽然都还在GPT-3那代。
-
Level3的公司:积极拥抱统一大模型,现在开始调研至少1.5B以上的模型底座,在自己场景下结合高质量的数据进行finetune的路。不要再在过多单任务上的研究投入太多。