04
缓存更新平台
缓存更新平台主要有下面两大功能:
- 执行实际的缓存增、删、改命令;
- 缓存内容发生了变更后通知业务方;
由于缓存更新平台汇总了所有的缓存更新操作,所以它能够在缓存发生变更后,通过广播消息及时通知业务方,业务方拿到该消息后可以判断是否要做处理。目前这个功能主要用于解决热点key的内容更新问题,这在前文热点key处理的相关章节已做了详细说明,后文不再赘述。
后文主要介绍该平台的第一点功能。
前文有讲到,我们为了规避并行操作同一个key导致缓存中存储旧值而非最新值的问题,从而引入消息机制将缓存操作串行化。该缓存更新平台就用于串行的从消息队列消费缓存操作消息。
所以我们的核心需求是:单线程处理同一个key的缓存操作消息且不让旧的缓存覆盖新的缓存。
基于上面的需求,产生了四个问题:
- 怎么判断多个消息属于同一个key的缓存消息?
- 缓存操作的消息量级非常大(峰值情况下几十万条/分钟),怎么快速消费完?
- 怎么知道缓存内容是新还是旧,是否该对该消息进行处理?
- 由于基于消息,如何保障消息一定会被处理?
1、怎么判断多个消息是属于同一个key的缓存消息?
针对这个问题,我们通过在消息中携带缓存的key来解决这个问题,这样做带来了几个好处:
1)将业务和缓存更新平台解耦,key的内容由业务全权决定;2)通过首先计算key的hash值,然后对其取模,可以将相同的key分配到相同的线程处理(见后文);3)可扩展性强,针对后续热点key的分析和自动化加载热点key也起到了关键作用(后续迭代计划的功能);
2、怎么快速消费消息?
由于核心需求是单线程的处理同一类key的消息,所以不同key的消息由不同的线程处理既能很好的解决性能问题,又不会产生逻辑问题。我们采取了如下架构去消费产生的消息:
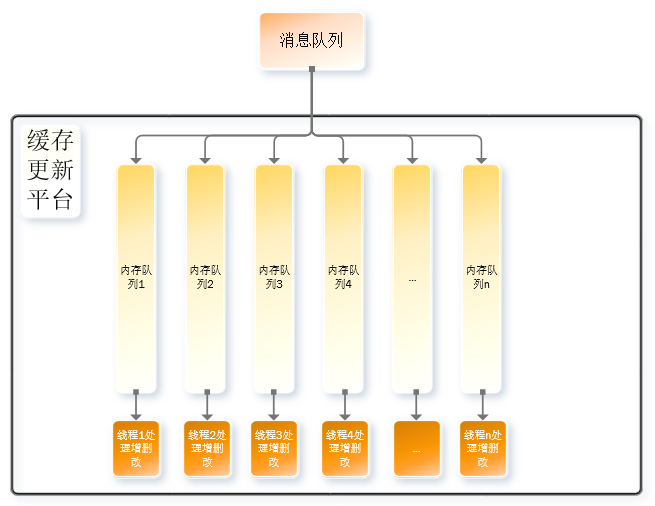
同一类key通过计算其hash值,然后再对结果进行取模,可以保证它们进到同一个内存队列和线程,从而规避并行操作同一个key的问题。通过这个架构,如果某个key的消息消费过慢,也不会影响其他key的消费进度,从而既保障了消费速度也满足了需求。
实践下来,目前我们仅用了两台机器就能做到每分钟消费几十万条消息,且远未遇到瓶颈。
3、怎么知道缓存内容是新还是旧,是否该对该消息进行处理?虽然我们做到了同一类key的单线程处理,并且,我们使用的公司的消息队列能保障消息的有序性。但依然有个问题没解决,那就是旧的缓存可能会覆盖新的缓存,因为我们没法保障新的缓存消息一定在旧的缓存消息产生之后再产生。考虑下面这个场景:
| 时刻(由近及远) | 线程1 | 线程2 | 线程3 |
| T1 | 基于key,读到DB中的值为v1 | ||
| T2 | 基于key,更新DB中的值为v2 | ||
| T3 | 基于key,读到DB中的值为v2 | ||
| T4 | 投递缓存内容为key<->v2的消息 | ||
| T5 | 投递缓存内容为key<->v1的消息 |
从上面可以看到,由于线程3的key<->v2消息先产生,所以它会被先消费,此时缓存的数据会变为v2, 然后缓存更新平台再处理key<->v1这条消息,从而导致v1覆盖缓存中的v2,出现旧值覆盖新值的问题。在这里,我们引入了缓存版本的概念来解决这个问题,我们认为每条缓存的数据都应该有一个版本号(业务提供,例如可以是修改数据的时间戳,只要满足单调递增即可)。基于此,缓存的增、删、改操作全部基于这个版本号来进行判断是否执行操作。具体的判断逻辑,在后文介绍。
1)缓存的增、删、改流程
- 删除缓存流程
先看下面流程图:

我们整个流程上是基于消息通知,这个消息生产的时机是只要业务删除了数据库中的数据就可以向缓存更新平台发送一条删除缓存消息。从流程上可以看到,针对该消息的处理,流程里面并不是简单的删除一个key,而是将删除的内容标记一下存入缓存。这样做带来了如下的好处:
1)能够避免缓存穿透;2)能够避免缓存“复活”已经删除的数据;
如果我们简单的删除缓存中的内容而不是将被删除的内容标记起来存入缓存,那么当出现下面这个场景时,缓存中就会长期存在已经删除的数据,从而导致数据使用方误认为该数据仍然有效。
首先假设现在某个key在缓存中不存在。线程先消费了删除该key的消息且删除的数据版本是v1,然后消费了存储缓存key<->v1的消息,这个时候就会将key<->v1写入缓存,但其实这个数据已经被删除了。但即便将删除的内容放入缓存,考虑极端情况,仍然可能会有问题,考虑下面这个场景:
有两条邻近产生的消息:
消息1:删除key<->v1的缓存消息消息2:新增key<->v1的缓存消息
假设消费完消息1后,因为某种原因(如平台宕机或者消息队列出问题等等),消息2过了很久(缓存key已经过期)才被消费到,这时在缓存中存入该消息也会导致被删除的数据“复活”。所以针对这类情况,有两种措施:
1)缓存永久有效2)超过一定时间未处理的消息就不处理了(我们采取的方案)关于删除缓存消息中的版本,前文有提到,我们认为每条缓存数据都是有版本的。所以即便业务要删一条数据,那么被删的数据肯定也是有版本号的,而这个版本就是该条消息的版本。我们借助这个版本,就知道缓存中的数据是否是更新的版本,是否可以被覆盖并且被标记为删除了。
- 新增&修改缓存流程
新增缓存消息的处理流程和修改缓存消息的处理流程一致,见下:

首先,消息的生产时机是:
新增缓存消息:
- 业务往数据库中插入数据
- 业务流程因为缓存缺失导致直接访问到数据库的数据
修改缓存消息:
业务修改了数据库中的数据流程上可以看到,当缓存更新平台收到新增/修改缓存消息时,拿着消息中的key去查缓存,如果没有,则直接存入缓存;如果缓存中存在,则拿着缓存中的数据版本与消息的数据版本进行对比,如果消息中的数据版本更高(即更新),那么就可以安全覆盖缓存中的数据;反之,则不应该覆盖。通过这个流程,就可以很好的避免传统缓存更新里面经常出现的低版本数据覆盖缓存中高版本的数据。新增&修改缓存流程与删除缓存流程大体一致,仅有一个区别点,如下:
新增&修改缓存:

删除缓存:

删除流程中关心的是消息中的版本是否大于等于缓存中的版本,而新增&修改缓存流程只关心消息中的版本是否大于缓存中的版本,为什么删除流程要关心版本相同的情况而新增&修改流程不关心呢?
针对删除,假设删除的数据对应的版本是3,而缓存中正好也有这个数据且数据版本也是3,这说明删除操作其实针对的是最新的数据,所以可以将缓存标记为删除态。
针对新增&修改,假设某条数据修改后,数据版本为3。此时缓存里面正好也有版本为3的数据,那么缓存中的这条数据会有下面两种情况:
- 该数据在缓存中被标记为删除态了(即被业务删除了该数据)
若此时写入缓存,会导致删除态数据重新“复活”
- 该数据处于正常状态
若此时写入缓存,没有任何意义。
综上,无论针对上述哪种情况,只要不对这条消息进行处理,就不会有任何问题。所以,修改流程只有当消息中的版本高于缓存中的版本时才设置缓存。4、如何保障消息一定会被处理?由于整个平台依赖于消息队列中间件,那么如果消息队列中间件出了问题(如宕机/网络问题/消息投递失败等等)导致消费变得很慢或漏掉消息,怎么办?前文提到,我们提供的缓存访问组件内部会将每条消息记录到业务DB。缓存更新平台通过业务提供的接口增量轮询该表,确保所有消息都被及时消费掉。通过这样的容错措施,确保不会因为单点故障导致缓存来不及更新。
05
小结
可以看到,通过上述的缓存访问组件和缓存更新平台,可以做到缓存与数据库数据的快速一致,从而既保障了性能同时又最大程度的降低了用户看到过期数据的可能性。
接下来,我们将继续迭代,解决1)减少缓存访问组件在业务代码上的侵入性;2)在缓存更新平台引入缓存key的分析机制,可以自动判定是否是热点key等问题。

