@[toc]
我为什么要写这篇
我们都知道,21世纪是数据科学的时代,而统计学则是数据科学的基础,任正非在一档访谈节目中也着重谈到了统计学在大数据时代的重要性。大数据不能被直接拿来使用,统计学依然是数据分析的灵魂。

总论
全章概览图
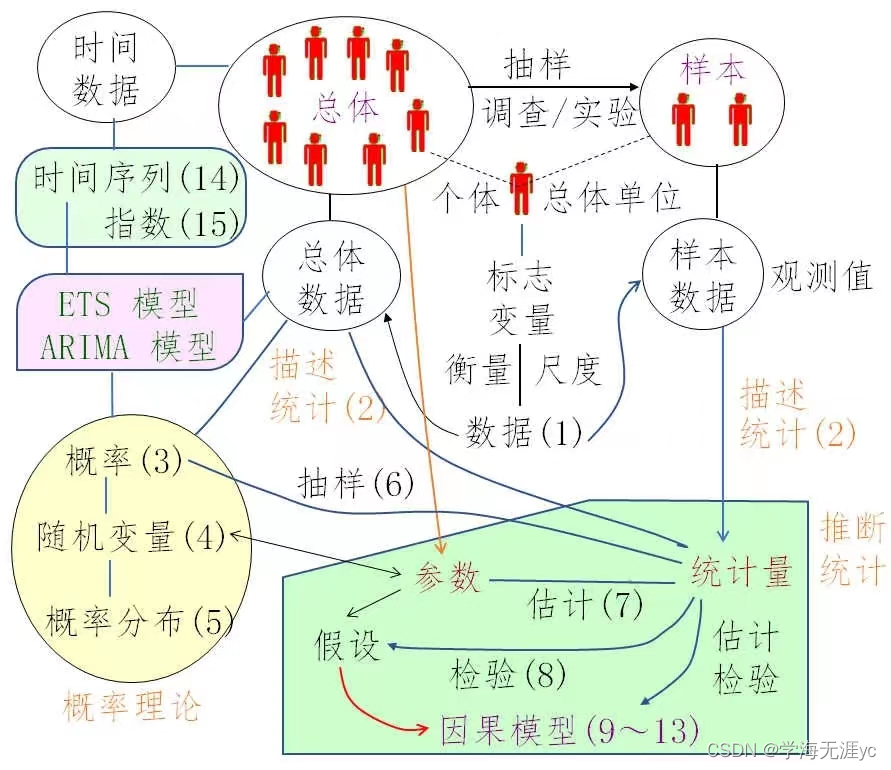
1.1统计学是什么
“统计学”是兼具“数学计算”与“图形显示”的课程,所有的统计软件(如SPSS),并非计算机辅助教学(CAI),因为它们并非“教你学会统计”,而是应该在“学会了统计”以后,再来用它。本书就是这样一本让你从零开始接触统计学,并将其真正应用到工作中的一本书,稳步跟进大数据时代。
本书前后连贯,各章之间也是先后呼应。例如:从概率到抽样,从描述到推断,从检验到因果;每章也是连贯的,开关有引言、观念图,结尾有流程图、思维导图;书中有许多阶层图、分类图、关联图、步骤图、流程图,以及因果表、比较表、决策法则表等。
本书专门的配套软件(中文统计)是在Excel(2003~2016版本适用)环境下,安装一个“加载项”,输入统计资料,就可以得到统计结果。“中文统计”可以公开下载,仅提供给合法取得本书之读者使用。
本书适合所有想掌握统计学的读者,也可以作为高校教材,

统计一次,包括:统计工作,统计数据和统计学。内容的重点是统计学
- 统计工作:统计的实践,应用统计问题,统计设计,搜索,整理,分析。
- 统计数据:统计工作获得的各种相关数据信息,没有数据,就没有统计。
- 统计学:统计理论,分析数据,选择分析模型,了解计算结果,获得信息价值。应用最多的领域就是管理,所需要的就是 测量—>数据—>统计—>管理—>衡量—>绩效统计学的目的有四个:
- 了解现象:描述统计是了解数据的呈现与性质,如集中趋势的代表值或变异程度的离差值;时间序列和指数是了解变化因素的幅度
- 推测总体:统计校验和估计是推测总体
- 知道因果:两总体校验,方差分析,回归分析是知道因果
- 预测未来:时间序列是预测未来
- 例题 统计与统计学的源流(了解现象,推测总体)
统计学的产生和发展是以研究实际数据的统计实践活动为基础的,而统计实践活动注定与人类社会活动浑然一体,不可分割。人类的生存与发展大概离不开三个最基本的数:人口、土地和财富,统计也确实是从这三方面的调查开始的。
这方面的功能主要体现在科学评估(评价)和预测未来上,即作为评估与预测的工具。如今,通过运用现代统计手段测量评估社会绩效、发展潜力、竞争优势、生存质量、社会变革、生活条件、福利水平等已经司空见惯。亨利认为,统计学可以广泛运用于政策研究和评价研究,即通过向社会公众展现统计信息以避免混淆视听,并且认为制定和展现统计数据有三个基本原则:可理解性、可解释性和可比较性。可理解性保证了不需要掌握专业的统计方法就能理解统计信息;可解释性保证了统计信息可以用熟悉、具体的数据单位来解释;可比较性保证了统计信息有标准的度量尺度,可以做出横向和交叉比较。哈尔则高度认可统计的预测功能,认为统计是可以预测未来的无价之宝。可见,统计承担着通过搜集和筛选信息来说明社会现状、并对未来走势进行预测的重任
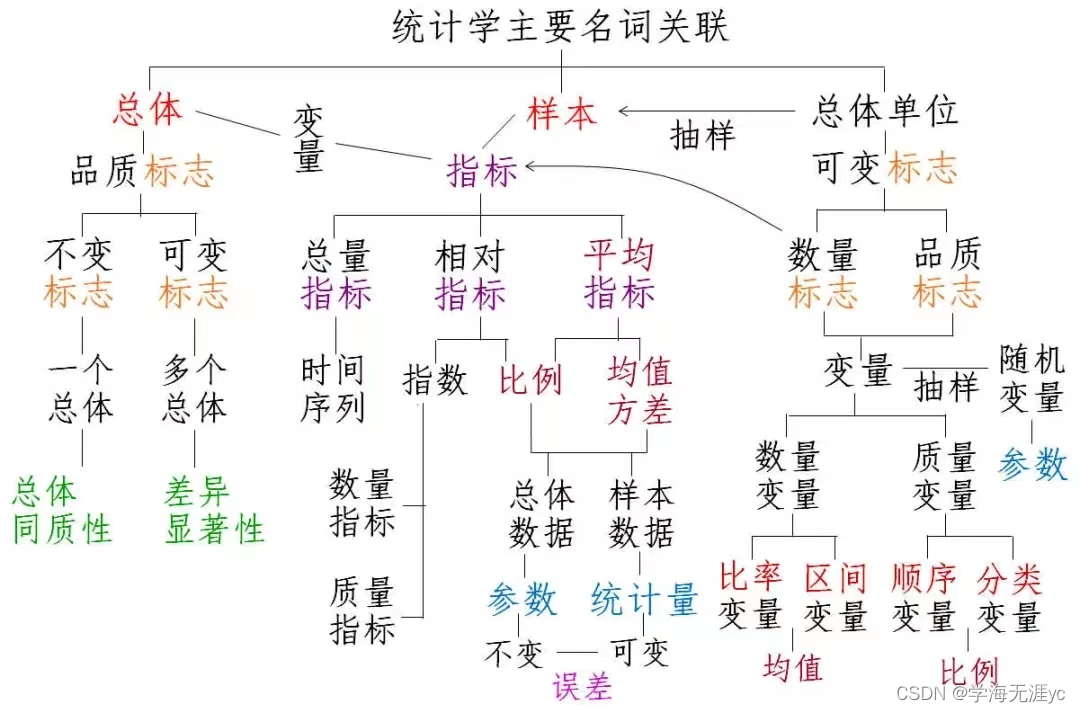
1.2 统计学的基本概念
1、个体:个体是指统计分析根据研究目的所确定的最基本的研究对象单位,所以个体又称为观察单位
例:分析业务人员的报销费用,则人为观察单位
2、变量:根据研究目的确定研究对象,然后对研究对象的某项目的或研究指标进行观察(或测量),这种观察项目或研究指标称为变量(variable);
- 连续变量(continuous variable):也叫区间变量。取值范围是一个区间,可以在该区间中连续取值,并且一般有度量单位。例:身高、体重、金额
- 特点:有大小之分,各取值之间的间距明确
- 离散型变量(discrete variable):取值范围是有限个值或者一个序列构成的。
- -分类变量:表示分类情况的离散型变量又称为分类变量
- 有序分类变量:例:服务满意度(满意、一般、不满意)
- -特点:有大小之分,但是各类别间的间距大小不明。比如“高”和“中”之间的差距与“中”和“低”之间的差距我们无法判断相差多少
- 无序分类变量:例:血型(A、O)、民族(汗、满)
- -- 特点:无大小之分,仅知道属于不同类别
- 两分类变量(单独摘出):性别(男、女)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-awLsHTny-1654679551057)(C:\Users\萧\AppData\Roaming\Typora\typora-user-images\image-20220608163935691.png)]](https://ucc.alicdn.com/images/user-upload-01/d9ede55dc4ba44b2851fa6c82b3106bf.png)
连续变量、有序变量、无需变量间的信息量越来越少,在丢弃一部分信息量的前提下,可以将变量向信息量减少的方向转换。类别超过5类的时候可以把类别编码做逆向转换。
3、变异:同质个体的某指标(变量)值的差异称为个体变异(individual variable)
- 统计学就是研究变异规律的学科,不存在变异的问题不属于统计学的研究范畴。或者说正是因为存在变异,才有了统计学的用武之地。
- 对于无变异的常量问题,或者严格的数学函数问题,并非统计学的应用领域。
4、总体(population):根据研究目的确定的同质所有个体某指标观察值(测量值)的集合。
- 有限总体(finite population):数量稳定
- 无限总体(infinite population):不知道数量,例:糖尿病人口 可能在随时发生变化
5、样本(sample):在一个较大范围的研究对象中随机抽出一部分个体进行观察或测量,这些个体的测量值构成的集合被称为样本。
6、随机抽样(random sampling):在抽样研究中随机抽出一部分个体进行观察或测量的过程称为随机抽样。
- 本质:每个个体最终是否入选在抽样进行前是不可知的,但是其入选可能性是确切可知的(多数情况下为等概率)
- 注意:随机 != 随便
7、统计量(statistic):刻画样本特征的统计指标称为统计量。(平均水平、离散程度)
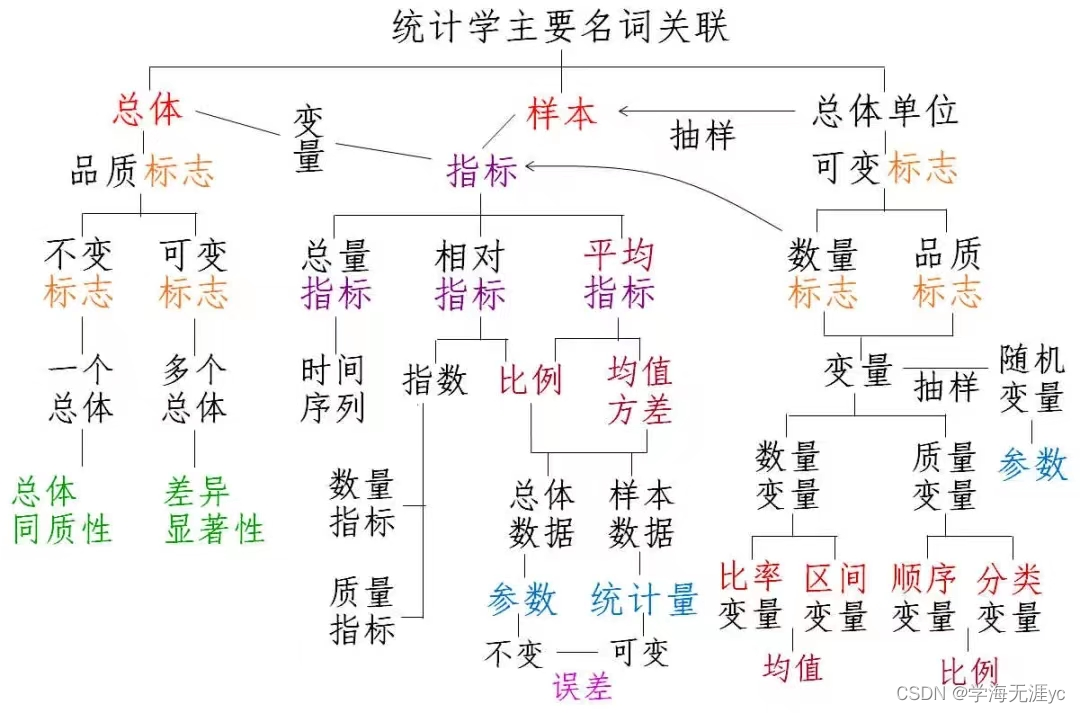
8、总体参数(parameter):刻画总体特征的指标称为总体参数,例如总体中某个指标的个体变量值的平均数称为总体平均数。
9、推估:从样本的统计量回推总体参数。
10、抽样误差(simple error):许多总体指标是未知的,需要用相应的样本统计量对其进行估计。由随机抽样造成的样本统计量与总体指标之间的差异称为抽样误差。
11、随机事件:随机现象某个可能的观察结果称为一个随机事件。如:扔一次硬币正面朝上,这个结果就是一次随机事件。
12、频率(frequency):观察到的随机事件某个结局的出现频次/比例。
13、概率(probability):刻画随机事件发生可能性大小的指标,其取值介于0和1之间。不能被直接观察到,但可以通过频率估计,实验次数越多,估计约精确。
14、小概率事件:在统计学中,如果随机事件发生的概率小于或等于0.05,则认为是一个小概率事件,表示该事件在大多数情况下不会发生,并且一般认为小概率事件在一次随机抽样中不会发生,这就是小概率原理。小概率原理是统计推断的基础。
15、频数(Frequency):又称“次数”。指变量值中代表某种特征的数(标志值)出现的次数。按分组依次排列的频数构成频数数列,用来说明各组标志值对全体标志值所起作用的强度。各组频数的总和等于总体的全部单位数。频数的表示方法,既可以用表的形式,也可以用图形的形式
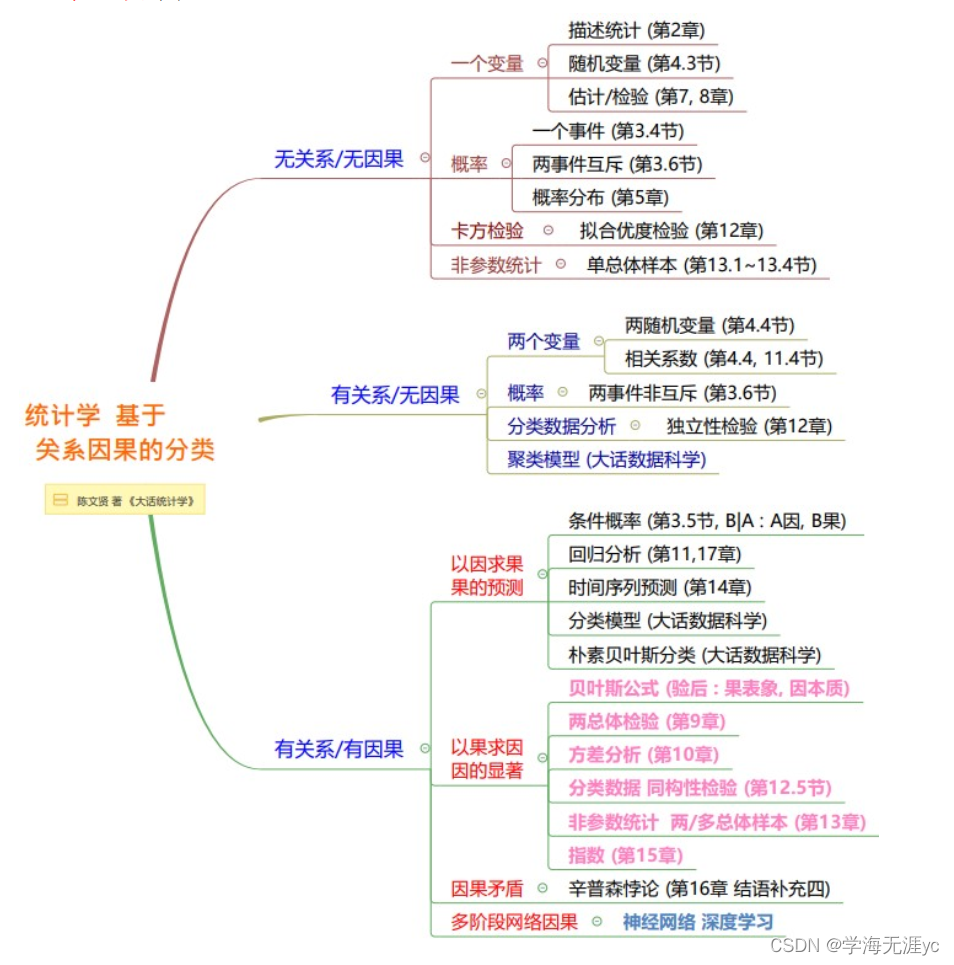
基于关系和因果的统计学分类
第二话
数据的描述
- 用图表描述:①统计类: table() 生成频数分布表 prop.table() 将频数分布表转化为比例 addmargins() 给频数分布表添加边际和或边际比例 barplot() 生成条形统计图
pie() 生成饼图
②分布类:hist() 生成直方图,观察变量内的分布
stem() 生成茎叶图,观察变量内的分布
boxplot() 生成箱线图,观察变量内的分布或对象间的变量水平比较
plot() 生成散点图,观察变量间的分布关系
radarchart() 生成雷达图,观察样本间的相似性。package(fmsb)
用统计量描述:
①水平的描述mean() 均值,易受极端值影响median() 中位数,不受极端值影响quantile() 分位数summay() 描述统计量,输出数据的基本描述信息
②差异的描述max()-min() 极差,易受极端值的影响,不能全面反映差异的情况quantile(x,0.75)-quantile(x,0.25) 四分位差,又称内距、四分间距,不受极端值影响var() 方差,数据离散程度的度量,比极差、四分位差更全面具体,但受数据取值大小的影响,无量纲sd() 标准差,方差开方,有量纲,性质同方差
③分布形态的描述skewness() 偏斜系数,其绝对值越接近0偏斜程度越低数据分布越对称,小于0.5位轻微偏斜,在0.5到1之间为中等偏斜,大于1为严重偏斜。值>0时右偏,均值大于中位数;值<0则左偏,均值小于中位数。package(agricolae)kurtosis() 峰度系数,数据分布峰值的高低。其值>0时为尖峰分布,数据相对聚集;<0时为扁平分布,数据相对分散。标准正态分布峰度系数为0。package(agricolae)
分布
- 概率分布:①函数开头的字母d = 密度函数(density)p = 分布函数(distribution function)q = 分位数函数(quantile function),给定累计概率、均值、方差求所在的分位数r = 生成随机数(随机偏差)
②一些常用分布函数(开头要加上d、p、q、r)binom() 二项分布geom() 几何分布pois() 泊松分布norm() 正态分布unif() 均匀分布
③数据的正态性评估先qqnorm(y = 数据),后qqline( y = 数据 ) 生成Q-Q图,直线表示理论正态分布线,各观测点越接近直线且呈随机分布,表明数据越接近正态分布
- 统计分布:①函数开头的字母:同概率分布的d、p、q、r一样
②三个统计分布(变量均基于正态分布。开头要加上d、p、q、r)t() t分布,随自由度越大越尖越接近标准正态分布,当正态总体标准差未知时,小样本条件下对总体均值的估计和检验要用到t分布
chisq() 卡方分布,通常为不对称的右偏分布,自由度越大则越趋于平坦对称。概率为曲线下的面积。在总体方差的估计和非参数检验中常用到卡方分布
f() F分布,两个相互独立的随机变量的卡方分布除以各自的自由度之比,图像类似卡方分布,形状取决于两个相互独立的随机变量的卡方分布的自由度,其概率为曲线下的面积,通常用于比较不同的总体的方差是否有显著差异
# R 语言绘图
if(!require(profvis)){install.packages("profvis")} ; library(profvis)
if(!require(aplpack)){install.packages("aplpack")} ; library(aplpack)
if(!require(ggplot2)){install.packages("ggplot2")} ; library(ggplot2)
if(!require(graphics)){install.packages("graphics")} ; library(graphics)
if(!require(lattice)){install.packages("lattice")} ; library(lattice)
if(!require(RColorBrewer)){install.packages("RColorBrewer")} ; library(RColorBrewer)
if(!require(qcc)){install.packages("qcc")} ; library(qcc)
x = read.csv("C:/大话统计学 网络资源/StatData/Chap2_1.csv",header=F)
代码展示
x1 <- x[,1] # x1 是数据框 x 的第1列数据 (x1是向量数值格式)
breaks <- seq(from=min(x1), to=max(x1), length=8) # 分成 8-1 = 7 组
freq <- cut(x1, breaks=breaks, right=TRUE, include.lowest=TRUE)
table(freq) ; hist(x1, breaks=breaks, col='pink') # 频数分布表 与 直方图
pause(10) # 等候 10 秒钟
hist(x1, freq=FALSE, col='light green') ; lines(density(x1), lwd=3, col='blue')
pause(10) # 等候 10 秒钟
brk <- c(20,35,40,50,65,70,80,90,100)
hist(x1,breaks=brk, col='yellow') # 不同组宽 直方图
pause(10) # 等候 10 秒钟
n <- length(x1) ; plot(sort(x1),(1:n)/n,type="s",ylim=c(0,1) , col='purple') # 累积频率图
pause(10) # 等候 10 秒钟
boxplot(x1, col="yellow", main=paste("例题2.1 箱线图")) # 箱线图
pause(10) # 等候 10 秒钟
plot(ecdf(x1), main=paste("例题2.1 累积概率函数"), col.hor='#3971FF',
col.points='#3971FF')
pause(10) # 等候 10 秒钟
bound <- hist(x1, right=TRUE, plot=FALSE )$breaks
plot(bound, ecdf(x1)(bound), type="l", main = "例题2.1 累积频率图", ylab= "频率",
xlab= "分数", col="red", lwd=3) #累积频率图
pause(10) # 等候 10 秒钟
stem.leaf(x1, style="bare") # 茎叶图
class <- hist(x1, right=TRUE, freq=FALSE, col="green")
pause(10) # 等候 10 秒钟
class <- hist(x1, right=F, freq=F, col="yellow", main="例题2.1 直方图", xlab="人数")
pause(10) # 等候 10 秒钟
class <- hist(x1, right=TRUE, freq=F,col="yellow", main="例题2.1 多边形图", xlab="人数")
middles <- class$mid ; mlon <- length(middles) ; densities <- class$density
pause(10) # 等候 10 秒钟
segments(middles[1:mlon-1],densities[1:mlon-1], middles[2:mlon],densities[2:mlon],
col=rgb(0.4196078, 0.4196078, 0.1372549,0.9), lwd=3, main=paste("例题2.1 多边形图"))
pause(10) # 等候 10 秒钟
x2 = read.csv("C:/大话统计学 网络资源/StatData/Chap2_4_1.csv",header=TRUE)
# 读入 Chap2_4_1.csv
table(x2) ; col2 = c("red", "yellow", "blue")
barplot(table(x2), bes=TRUE, col=col2, legend.text = T, args.legend = list(x = "top",
inset = c(- 0.15, 0)), main=paste("例题2.4 条形图")) # 両个定类变量条形图
col1 = c("red", "yellow", "blue", "sandybrown", "olivedrab", "purple", "green", "orange")
pause(10) # 等候 10 秒钟
x = read.csv("C:/大话统计学 网络资源/StatData/Chap2_6.csv",header=TRUE)

