












视觉智能平台常见问题之本地私有化部署如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之服务部署在pdd的服务器上调用会报错如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之人脸比对1:1的服务离线使用如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之ReturnForm返回的都是黑白的跟官方示例不符如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之车辆损伤识别接口用不了如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之视频封面输出的图片会出现过曝如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之使用人脸及身份证采集如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之无法购买服务如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之demo签名验证提示失败如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之通用抠图老是ssl错误如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之分割后的图片尺寸会变得比较大如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之体验产品的美颜测试关掉如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之用到人脸1:1加上活体需要单独收费如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之调用人像素描接口传全身照时报错如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之人脸人体的sdk返回报错如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之使用智能分镜功能拆分镜头丢失部分镜头如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之唤起失败如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之通用抠图老是ssl错误如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之人脸人体开通点立即开通页面一直不变如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之金融级人脸检测返回错误码z8121如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
AI技术引领视频去水印新时代
随着数字媒体的飞速发展,视频已成为我们获取信息、娱乐休闲的主要方式。然而,视频中的水印往往影响了观看体验,甚至阻碍了内容的传播。幸运的是,在人工智能(AI)技术的引领下,我们迎来了视频去水印的新时代。

FFmpeg开发笔记(十八)FFmpeg兼容各种音频格式的播放
《FFmpeg开发实战》一书中,第10章示例程序playaudio.c原本仅支持mp3和aac音频播放。为支持ogg、amr、wma等非固定帧率音频,需进行三处修改:1)当frame_size为0时,将输出采样数量设为512;2)遍历音频帧时,计算实际采样位数以确定播放数据大小;3)在SDL音频回调函数中,确保每次发送len字节数据。改进后的代码在chapter10/playaudio2.c,可编译运行播放ring.ogg测试,成功则显示日志并播放铃声。
CSS 常见的选择器
CSS 选择器是一种用于在 CSS(层叠样式表)中选择特定 HTML 元素的语法。它允许开发者指定要应用样式的特定元素或元素组。CSS有很多种选择器,下面我们列出30种,有很多是大家平常用的少,但确实好用的

FFmpeg开发笔记(十三)Windows环境给FFmpeg集成libopus和libvpx
本文档介绍了在Windows环境下如何为FFmpeg集成libopus和libvpx库。首先,详细阐述了安装libopus的步骤,包括下载源码、配置、编译和安装,并更新环境变量。接着,同样详细说明了libvpx的安装过程,注意需启用--enable-pic选项以避免编译错误。最后,介绍了重新配置并编译FFmpeg以启用这两个库,通过`ffmpeg -version`检查是否成功集成。整个过程参照了《FFmpeg开发实战:从零基础到短视频上线》一书的相关章节。

FFmpeg开发笔记(十二)Linux环境给FFmpeg集成libopus和libvpx
在《FFmpeg开发实战》一书中,介绍了如何在Linux环境下为FFmpeg集成libopus和libvpx,以支持WebM格式的Opus和VP8/VP9编码。首先,下载并安装libopus。接着,下载并安装libvpx。最后,在FFmpeg源码目录下,重新配置FFmpeg,启用libopus和libvpx,编译并安装。通过`ffmpeg -version`检查版本信息,确认libopus和libvpx已启用。
sql导入数据库命令
在SQL Server中,数据库导入可通过多种方式实现:1) 使用SSMS的“导入数据”向导从各种源(如Excel、CSV)导入;2) BULK INSERT语句适用于导入文本文件;3) bcp命令行工具进行批量数据交换;4) OPENROWSET函数直接从外部数据源(如Excel)插入数据。在操作前,请记得备份数据库,并可能需对数据进行预处理以符合SQL Server要求。注意不同方法可能依版本和配置而异。

FFmpeg开发笔记(九)Linux交叉编译Android的x265库
在Linux环境下,本文指导如何交叉编译x265的so库以适应Android。首先,需安装cmake和下载android-ndk-r21e。接着,下载x265源码,修改crosscompile.cmake的编译器设置。配置x265源码,使用指定的NDK路径,并在配置界面修改相关选项。随后,修改编译规则,编译并安装x265,调整pc描述文件并更新PKG_CONFIG_PATH。最后,修改FFmpeg配置脚本启用x265支持,编译安装FFmpeg,将生成的so文件导入Android工程,调整gradle配置以确保顺利运行。

FFmpeg开发笔记(四)FFmpeg的动态链接库介绍
FFmpeg是一个强大的多媒体处理框架,提供ffmpeg、ffplay和ffprobe工具及八个库:avcodec(编解码)、avdevice(设备输入输出)、avfilter(音视频滤镜)、avformat(格式处理)、avutil(通用工具和算法)、postproc(后期效果)、swresample(音频重采样)和swscale(视频图像转换)。这些库支持定制化开发,涵盖了从采集、编码、过滤到输出的全过程。了解详细FFmpeg开发信息,可参考《FFmpeg开发实战:从零基础到短视频上线》。

FFmpeg开发笔记(三)FFmpeg的可执行程序介绍
FFmpeg提供ffmpeg、ffplay和ffprobe三个可执行程序。ffmpeg用于音视频转换和查询支持信息,如编解码器、文件格式和协议。ffplay是一个简单的播放器,支持播放音视频并显示相关信息。ffprobe用于分析多媒体文件参数和数据包详情。《FFmpeg开发实战:从零基础到短视频上线》一书提供更深入的开发知识。

Android开发之OpenGL的画笔工具GL10
这篇文章简述了OpenGL通过GL10进行三维图形绘制,强调颜色取值范围为0.0到1.0,背景和画笔颜色设置方法;介绍了三维坐标系及与之相关的旋转、平移和缩放操作;最后探讨了坐标矩阵变换,包括设置绘图区域、调整镜头参数和改变观测方位。示例代码展示了如何使用这些方法创建简单的三维立方体。
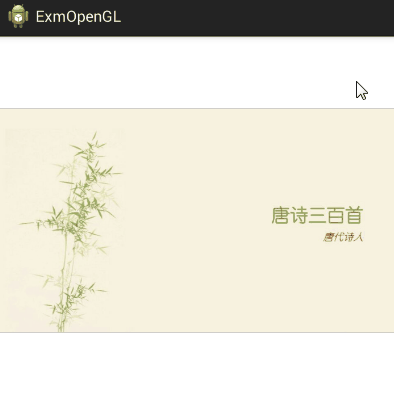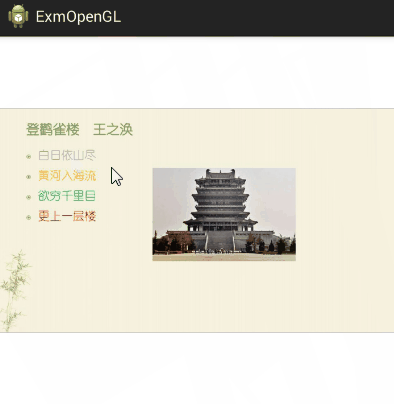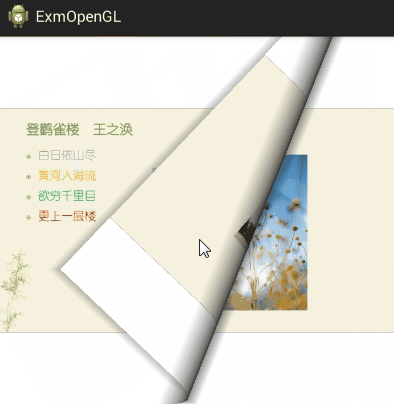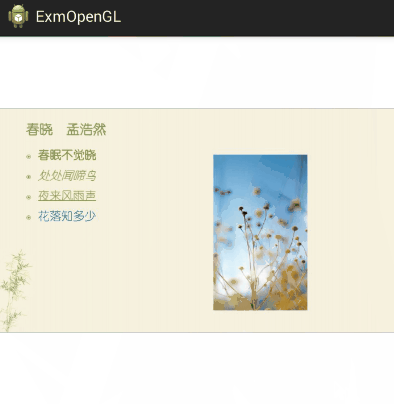
Android开发之使用OpenGL实现翻书动画
本文讲述了如何使用OpenGL实现更平滑、逼真的电子书翻页动画,以解决传统贝塞尔曲线方法存在的卡顿和阴影问题。作者分享了一个改造后的外国代码示例,提供了从前往后和从后往前的翻页效果动图。文章附带了`GlTurnActivity`的Java代码片段,展示如何加载和显示书籍图片。完整工程代码可在作者的GitHub找到:https://github.com/aqi00/note/tree/master/ExmOpenGL。
文字识别OCR常见问题之处理产品图片识别如何解决
文字识别OCR(Optical Character Recognition)技术能够将图片或者扫描件中的文字转换为电子文本。以下是阿里云OCR技术使用中的一些常见问题以及相应的解答。

文字识别OCR常见问题之识别一些截图的模式如何解决
文字识别OCR(Optical Character Recognition)技术能够将图片或者扫描件中的文字转换为电子文本。以下是阿里云OCR技术使用中的一些常见问题以及相应的解答。
文字识别OCR常见问题之发票真伪查询有接口如何解决
文字识别OCR(Optical Character Recognition)技术能够将图片或者扫描件中的文字转换为电子文本。以下是阿里云OCR技术使用中的一些常见问题以及相应的解答。
文字识别OCR常见问题之调试一直报401错如何解决
文字识别OCR(Optical Character Recognition)技术能够将图片或者扫描件中的文字转换为电子文本。以下是阿里云OCR技术使用中的一些常见问题以及相应的解答。
视觉智能平台常见问题之使用人脸及身份证采集如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之人脸美颜增强关闭如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之“图像生产”功能开通时一直开通不成功如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之判断摄像头抓拍到包含人脸的照片如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之实现卡通效果图如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
视觉智能平台常见问题之图像生产功能开通时一直开通不成功如何解决
视觉智能平台是利用机器学习和图像处理技术,提供图像识别、视频分析等智能视觉服务的平台;本合集针对该平台在使用中遇到的常见问题进行了收集和解答,以帮助开发者和企业用户在整合和部署视觉智能解决方案时,能够更快地定位问题并找到有效的解决策略。
AI视频大模型Sora新视角:从介绍到商业价值,全面解读优势
Sora是OpenAI于`2024年2月16日`发布的文生视频模型,`能够根据用户输入的提示词、文本指令或静态图像,生成长达一分钟的视频`,其中既能实现多角度镜头的自然切换,还包含复杂的场景和生动的角色表情,且故事的逻辑性和连贯性极佳。
OpenAI sora 是什么
Sora 能够根据文字描述生成长达一分钟的高清视频 Sora 的技术基础是 DALL-E 3 的技术,也就是 GPT4 现有的能力 Sora 的能力还有待提升,我们看到的视频是经过筛选的,并不是其典型能力

AiChat—智能办公助手
AiChat办公助手是具备大语言模型能力的人工智能应用,为用户提供智能文档写作、阅读理解和问答、智能人机交互能力,让用户在办公、写作、文档处理等方面实现更智能的体验

