
llm预训练第一个eporch的loss没怎么下降属于正常情况吗
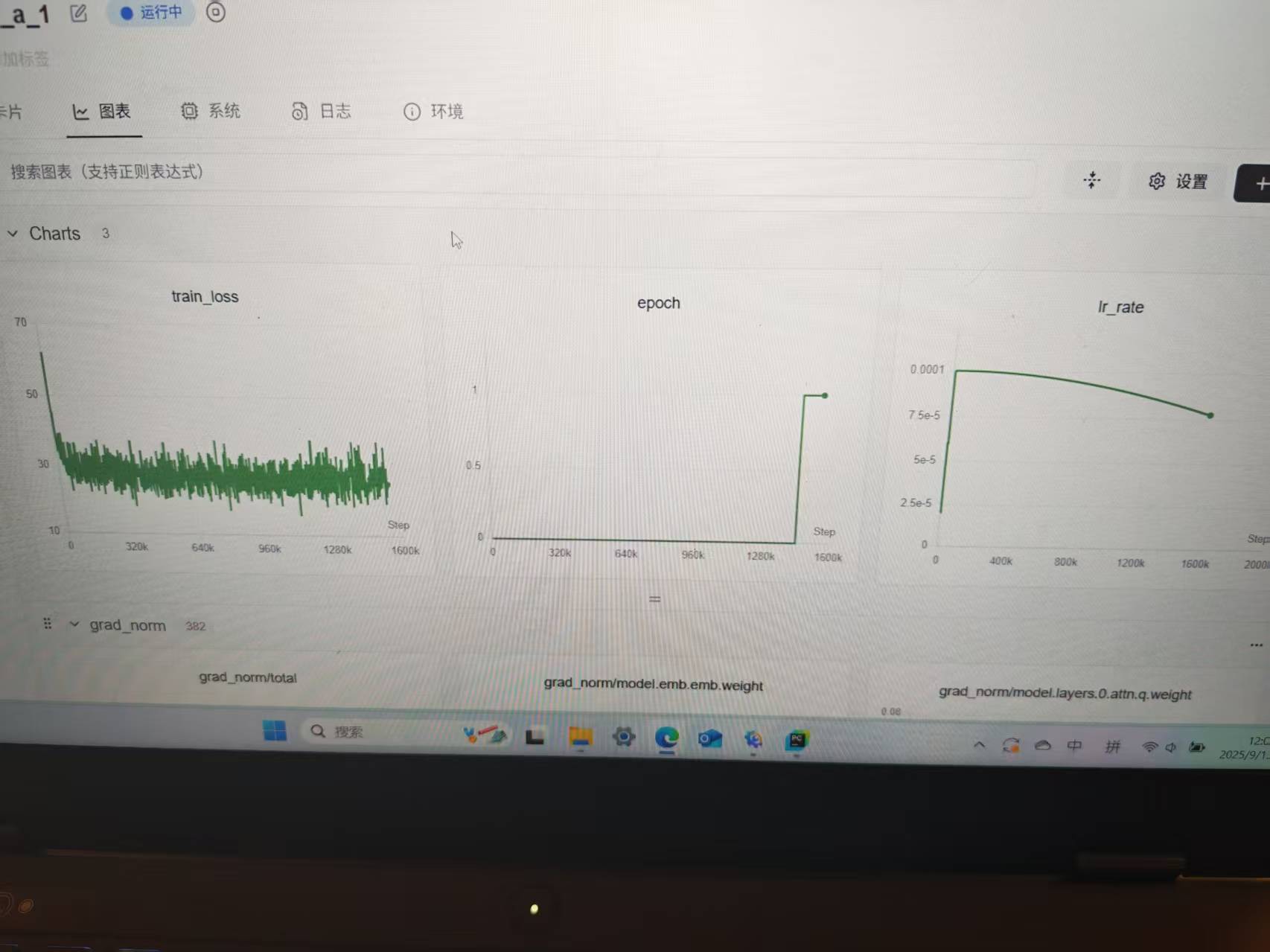
模型参数大概0.7B,训练长度512,batch_size是9,最大学习率是1e-4,余弦衰减,文本采用通用猴子数据集,有大佬能帮忙看一下是不是代码方面有什么问题呢,训练代码和训练模型代码:1,训练代码:import torch
torch.set_float32_matmul_precision('medium')
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
import transformers
from datasets import load_dataset
from train_model import Transformer, ModelArgs
from transformers import get_cosine_schedule_with_warmup
import torch.nn.functional as F
from torch import utils,optim
tokenizer = transformers.AutoTokenizer.from_pretrained("./tokenizer/tokenizer", device_map="auto")
tokenizer.bos_token = "<|begin▁of▁sentence|>"
tokenizer.eos_token = "<|end▁of▁sentence|>"
tokenizer.pad_token = "<|▁pad▁|>"
dataset = load_dataset("json", data_files="/root/autodl-fs/mobvoi_seq_monkey_general_open_corpus.jsonl", streaming=True)
def add_special_tokens(example):
bos = tokenizer.bos_token
eos = tokenizer.eos_token
return {"text": f"{bos}{example['text']}{eos}"}
train_data = dataset["train"].map(add_special_tokens)
print(next(iter(train_data["text"])))
tokenized_datasets = train_data.map(
lambda x: tokenizer(x["text"], padding="max_length", truncation=True, max_length=512, return_tensors="pt",
add_special_tokens=False),
batched=True,
batch_size=100,
remove_columns=["text"]
)
train_loader = utils.data.DataLoader(tokenized_datasets,
batch_size=9,
num_workers=0,
pin_memory=True,
drop_last=True,
)
print(next(iter(tokenized_datasets)))
print(train_loader)
import lightning as L
class Lit_structure(L.LightningModule):
def init(self):
super().init()
self.args = ModelArgs()
self.model = Transformer(self.args)
def training_step(self, batch, labels=None, **kwargs):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
logits = self.model(input_ids, attention_mask)
labels = input_ids.clone()
labels[labels == tokenizer.pad_token_id] = -100
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss = F.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1),
ignore_index=-100
)
self.log("train_loss", loss)
self.log("epoch", float(self.current_epoch))
self.log('lr_rate', self.trainer.optimizers[0].param_groups[0]['lr'], prog_bar=True)
grad_norms = {}
total_grad_norm = 0.0
for name, param in self.named_parameters():
if param.grad is not None:
grad_norm = param.grad.data.norm(2).item()
grad_norms[f'grad_norm/{name}'] = grad_norm
if param.grad is not None:
total_grad_norm += param.grad.data.norm(2).item() ** 2
self.log('grad_norm/total', total_grad_norm, on_step=True, on_epoch=False)
self.log_dict(grad_norms, on_step=True, on_epoch=False, prog_bar=False)
return loss
def configure_optimizers(self):
optimizer = optim.AdamW(
self.parameters(),
lr=1e-4,
betas=(0.9, 0.999),
weight_decay=0.01,
eps=1e-8
)
total_steps = self.trainer.max_steps
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=5000,
num_training_steps=total_steps
)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": scheduler,
"interval": "step",
"frequency": 1
}
}
model = Lit_structure().to(torch.bfloat16)
trainer = L.Trainer(devices="auto",
accelerator="gpu",
precision="bf16-mixed",
gradient_clip_val=1.0,
gradient_clip_algorithm="norm",
log_every_n_steps=1000,
max_steps=4875000,
max_epochs=5,
min_epochs=3,
overfit_batches=0,
callbacks=[
L.pytorch.callbacks.ModelCheckpoint(
dirpath="/root/autodl-fs",
every_n_train_steps=5000,
save_top_k=3,
monitor="train_loss",
filename="model-{step}-{train_loss:.2f}",
save_last=True,
save_on_train_epoch_end=True
)
]
)
trainer.fit(model=model, train_dataloaders=train_loader)
2,模型代码:import torch
from torch import nn
from torch.nn import functional as F
from dataclasses import dataclass
@dataclass
class ModelArgs:
max_batch_size: int = 8
max_seq_len: int = 2048
vocab_size: int = 150000
# GQA
dim: int = 1152
n_heads: int = 8
groups: int = 4
head_dim: int = dim // n_heads
n_layers: int = 27
attn_drop: int = 0.01
proj_drop: int = 0.01
# RoPE
qk_rope_head_dim: int = dim // n_heads
base: int = 10000.0
# FFN
ffn_drop:int = 0.01
class Embedding(nn.Module):
def init(self,args:ModelArgs):
super().init()
self.vocab_size = args.vocab_size
self.dim = args.dim
self.emb = nn.Embedding(self.vocab_size,self.dim)
def forward(self,x):
x = self.emb(x)
return x
def precompute_freqs_cis(args: ModelArgs):
freqs = 1.0 / (
args.base ** (torch.arange(0, args.qk_rope_head_dim, 2, dtype=torch.float32) / args.qk_rope_head_dim))
seqlen = args.max_seq_len
t = torch.arange(seqlen)
freqs = torch.outer(t, freqs)
freqs = torch.polar(torch.ones_like(freqs), freqs)
return freqs
def apply_rotary_emb(x, freqs):
dtype = x.dtype
x = torch.view_as_complex(x.float().view(x.shape[:-1], -1, 2))
freqs_cis = freqs.view(1, x.size(1), 1, x.size(-1))
y = torch.view_as_real(x freqs_cis).flatten(3)
return y.to(dtype)
def repeat_kv(x, groups: int) -> torch.Tensor:
bs, seq, n_kv_heads, head_dim = x.shape
if groups == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, seq, n_kv_heads, groups, head_dim)
.reshape(bs, seq, n_kv_heads * groups, head_dim)
)
class RMSNorm(nn.Module):
def init(self, dim: int, eps: float = 1e-6):
super().init()
self.dim = dim
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def forward(self, x: torch.Tensor):
return F.rms_norm(x, (self.dim,), self.weight, self.eps)
class GQA(nn.Module):
def init(self, args: ModelArgs):
super().init()
self.args = args
self.dim = args.dim
self.groups = args.groups
self.n_heads = args.n_heads
self.kv_heads = self.n_heads // self.groups
self.head_dim = self.dim // self.n_heads
self.q = nn.Linear(self.dim, self.dim)
self.kv = nn.Linear(self.dim, (self.kv_heads self.head_dim) 2)
self.scale = self.head_dim ** -0.5
self.attn_drop = args.attn_drop
self.wo_drop = args.proj_drop
self.attn_drop = nn.Dropout(self.attn_drop)
self.wo_drop = nn.Dropout(self.wo_drop)
self.wo = nn.Linear(self.dim, self.dim)
def forward(self, x, start_pos, freqs_cis, mask, pad_mask):
bsz, seqlen, feature = x.shape
end_pos = start_pos + seqlen
q = self.q(x).reshape(bsz, seqlen, self.n_heads, feature // self.n_heads)
kv = self.kv(x).reshape(bsz, seqlen, 2, self.kv_heads, feature // self.n_heads).permute(2, 0, 1, 3, 4)
rq, rk, v = apply_rotary_emb(q, freqs_cis), apply_rotary_emb(kv[0], freqs_cis), kv[1]
attn = torch.einsum("bshd,bthd->bsht", rq, repeat_kv(rk, self.groups)) * self.scale # rq @ rk.transpose(-2, -1) * self.scale + mask
pad_mask = pad_mask.unsqueeze(-1).unsqueeze(-1).expand(-1, -1, self.n_heads, seqlen)
pad_mask = (1.0 - pad_mask) * -1e9
if mask is not None:
attn = attn + mask.unsqueeze(1) + pad_mask
scores = attn.softmax(dim=-1, dtype=torch.float32).type_as(x)
scores = self.attn_drop(scores)
x = torch.einsum("bsht,bthd->bshd", scores, repeat_kv(v, self.groups))
x = self.wo(x.flatten(2))
return self.wo_drop(x)
class FFN(nn.Module):
def init(self, args: ModelArgs):
super().init()
self.dim = args.dim
self.w1 = nn.Linear(self.dim, self.dim 4)
self.w2 = nn.Linear(self.dim 4, self.dim)
self.w3 = nn.Linear(self.dim, self.dim * 4)
self.ffn_drop = nn.Dropout(args.ffn_drop)
def forward(self, x):
return self.w2(self.ffn_drop(F.silu(self.w1(x)) * self.w3(x)))
class Block(nn.Module):
def init(self, args: ModelArgs):
super().init()
self.dim = args.dim
self.attn = GQA(args)
self.ffn = FFN(args)
self.attn_norm = RMSNorm(self.dim)
self.ffn_norm = RMSNorm(self.dim)
def forward(self, x, start_pos, freqs_cis, mask, pad_mask):
x = x + self.attn(self.attn_norm(x), start_pos, freqs_cis, mask, pad_mask)
x = x + self.ffn(self.ffn_norm(x))
return x
class Transformer(nn.Module):
def init(self, args: ModelArgs):
super().init()
self.dim = args.dim
self.vocab_size = args.vocab_size
self.emb = Embedding(args)
self.layers = torch.nn.ModuleList()
for layer_id in range(args.n_layers):
self.layers.append(Block(args))
self.norm = RMSNorm(self.dim)
self.head = nn.Linear(self.dim, self.vocab_size)
self.head.weight = self.emb.emb.weight
self.register_buffer("freqs_cis", precompute_freqs_cis(args), persistent=False)
def forward(self, input_ids, attention_mask, start_pos: int = 0, **kwargs):
pad_mask = attention_mask
tokens = input_ids
seqlen = tokens.size(1)
freqs_cis = self.freqs_cis[start_pos:start_pos + seqlen]
h = self.emb(tokens)
mask = None
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device).triu_(1)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask, pad_mask)
h = self.norm(h)
logits = self.head(h)
return logits
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352