
SLS Scan的三段式工作机制是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
SLS Scan设计为三段式工作机制,包括:
L1按时间做过滤,L2按业务字段做过滤,L3在索引命中的结果集上做硬扫描过滤。
L1:按时间做过滤
时间是天然的日志主键,例如存储周期 30 天 100 TB 的数据,查询时间窗口选择为最近 6 小时,则数据量缩减到 1 TB。且时间过滤只需要根据索引(时间字段引入的膨胀比低到可忽略)、meta skip 就可以快速完成。
L2:按业务字段做过滤
这里所说的业务字段可理解为 Loki 的 Label 概念,但更为灵活,可以在日志到达 SLS 之后再自由选择。一般是选择可缩小下一步搜索范围或是被高频访问的字段,例如 K8s 日志可以将 namespace、image、node hostname、log path 设置索引。能匹配业务查询需求的字段索引,将大大地降低需要硬扫描的数据量,降低扫描费用和响应延迟。
L3:硬扫描做过滤
在索引命中的结果集上做最后的硬计算,SLS Scan 用 C++ 实现避免性能表现在数据规模上涨后衰减(Loki 受 GC 影响),部分高频算子做向量化加速。另外,SLS Scan 使用一个大的计算池(几百台 x86 多核服务器)来爆发算力,计算的并发度按照 Logstore(日志库)的 Shard(存储分片)数水平扩展。
这种机制通过逐步缩小搜索范围,提高查询效率和响应速度。


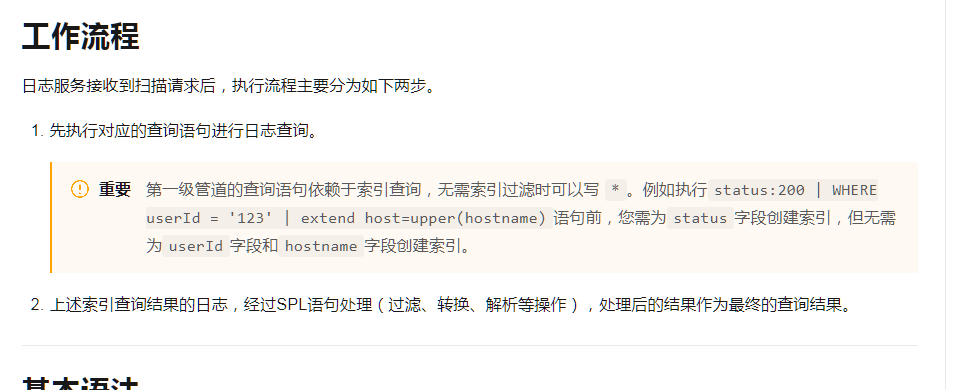 最后一段就是结果输出了
最后一段就是结果输出了