
modelscope-funasr这个问题怎么解决?我这边用aishell1微调后(test/dev 2.2%,1.91%),还没有微调前的字错率低(微调前我测试test数据集上字错率1.95%,dev上字错率1.75%,加了vad以后test/dev 2.11%,1.81%),官方微调好的模型 iic/speech_paraformer-large_asr_nat-zh-cn-16k-aishell1-vocab8404-pytorch 给的结论是 dev/test上取得CER 1.62/1.78,但我这边运行这个微调好的模型报错,报错如下图。 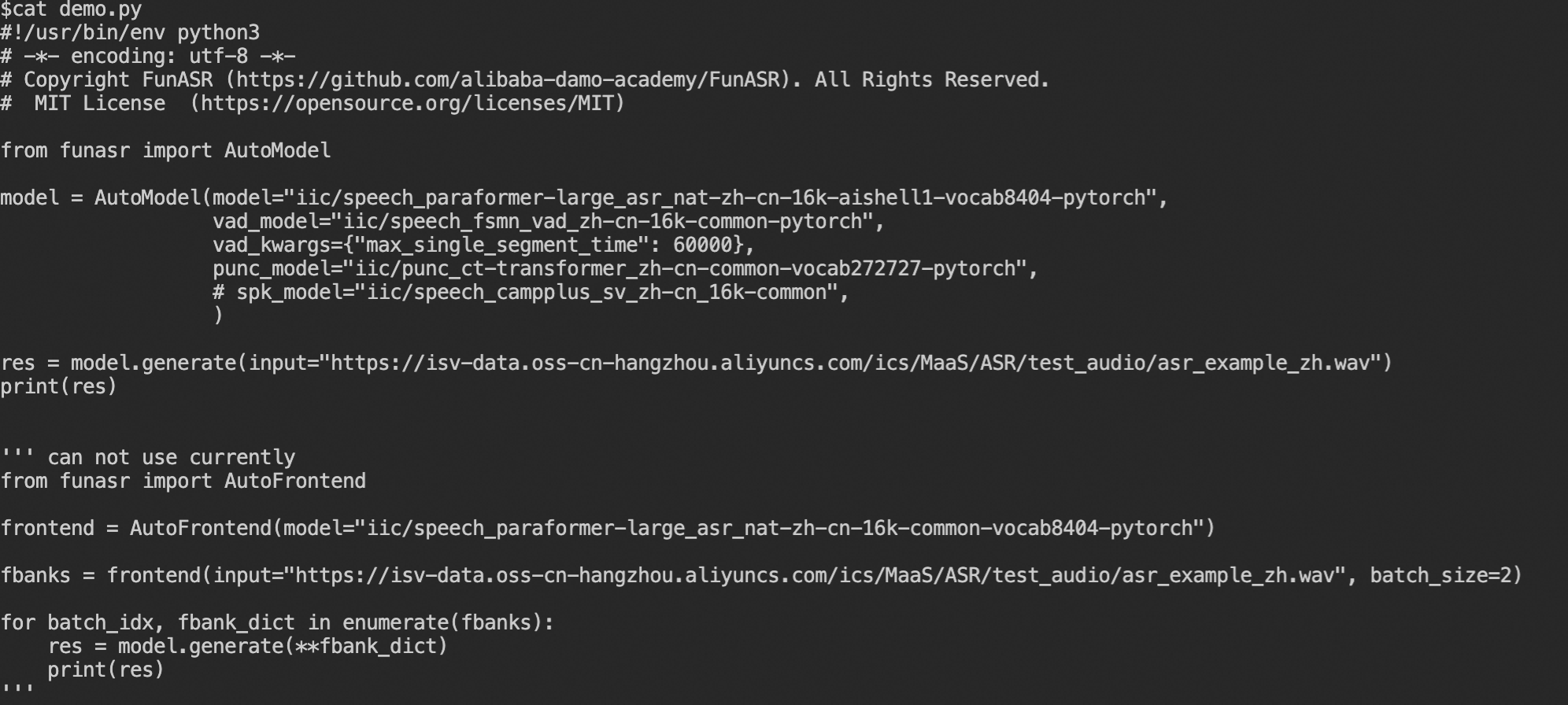

基本用法examples/readme.md,像这些基本用法,看看文档,debug一下就可以了。此回答整理自钉群“modelscope-funasr社区交流”
