
modelscope-funasr批量进行录音ASR的时候,执行一段时间就会出现这种错误,有人知道要怎么解决吗?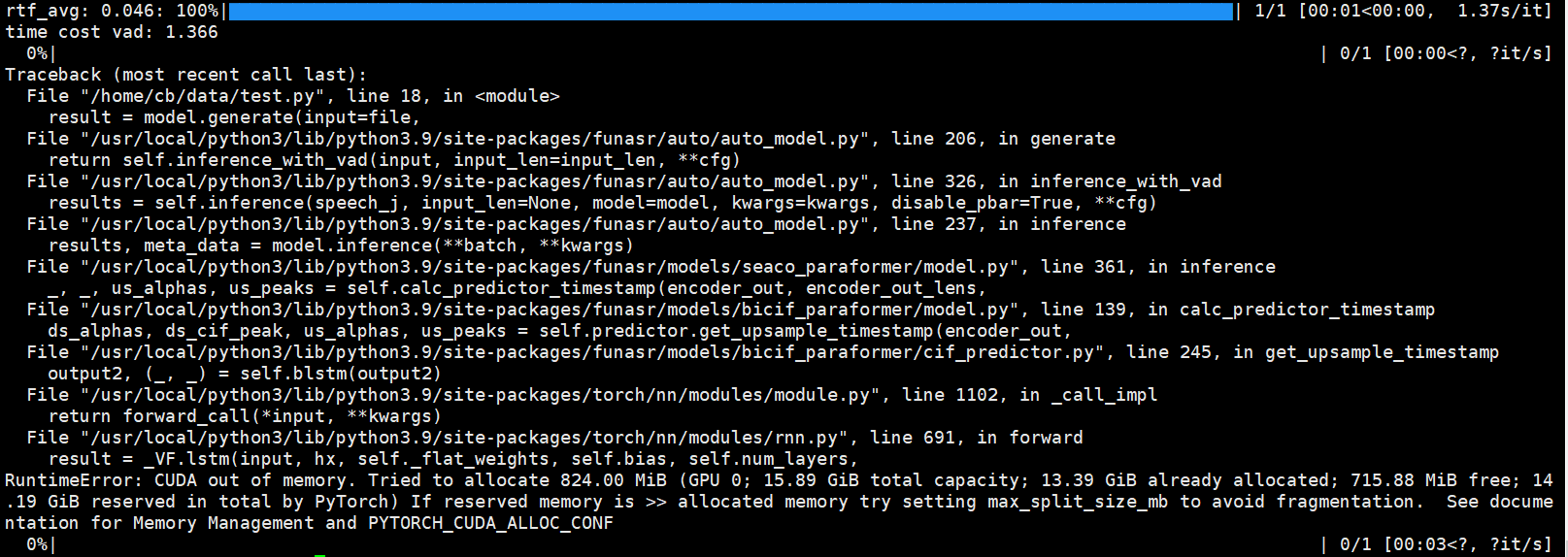
调用方式是这样的:
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
# spk_model="cam++", spk_model_revision="v2.0.2",
)
result = model.generate(input=file,
batch_size_s=600,
hotword='地调')
funasr1.0.5 modelscope1.11.1
根据您提供的信息,我猜测您可能遇到了内存泄漏的问题。在处理大量录音时,如果内存管理不当,可能会导致内存泄漏和程序崩溃。
为了解决这个问题,您可以尝试以下方法:
定期释放内存:在处理每个录音文件之后,确保释放所有相关资源,包括模型、音频数据等。这可以通过使用Python的del关键字或调用对象的close()方法来实现。
限制并发数:如果您的程序可以同时处理多个录音文件,可以考虑限制并发数,以避免同时加载过多的模型和数据导致内存不足。
调整模型参数:您可以尝试调整模型参数,例如减小模型大小或减少批处理大小,以减少内存占用。
检查依赖库:确保您的依赖库是最新版本,并且与您的代码兼容。有时候,旧版本的库可能会导致内存泄漏或其他问题。
使用工具分析内存使用情况:您可以使用Python的内存分析工具(如memory_profiler)来分析程序的内存使用情况,找出可能导致内存泄漏的地方。
重启程序:如果以上方法都无法解决问题,您可以考虑在处理一定数量的录音文件后重启程序,以释放内存并重新开始。但这种方法可能会影响程序的连续性和效率。

