
ModelScope中怎么判断是否微调完和微调成功?推理没问题,但是微调就提示找不到gpu,为什么?[INFO:swift] ===========Tensorboard Log============ [INFO:swift] b'2024-02-29 01:02:41.603174: I tensorflow/core/util/port.cc:111] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0.\n' b'2024-02-29 01:02:41.605542: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.\n' b'2024-02-29 01:02:41.638336: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered\n' b'2024-02-29 01:02:41.638378: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered\n' b'2024-02-29 01:02:41.638398: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered\n' b'2024-02-29 01:02:41.644960: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.\n' b'2024-02-29 01:02:41.645148: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.\n' b'To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.\n' b'2024-02-29 01:02:42.428654: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT\n' b'2024-02-29 01:02:43.126158: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:894] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at
https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355\n
' b'2024-02-29 01:02:43.150072: W tensorflow/core/common_runtime/gpu/gpu_device.cc:2211] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at
https://www.tensorflow.org/install/gpu
for how to download and setup the required libraries for your platform.\n'2024-02-29 15:33:16.133756: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT 启动web-ui时有这个信息,是否正常?[INFO:swift] Setting args.model_type: qwen1half-4b-chat
[INFO:swift] output_dir: /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153623
[INFO:swift] Setting hub_model_id: qwen1half-4b-chat-lora
[INFO:swift] Setting args.lazy_tokenize: False
[INFO:swift] Run training: CUDA_VISIBLE_DEVICES=0 nohup swift sft --model_id_or_path "qwen/Qwen1.5-4B-Chat" --template_type "qwen" --system "You are a helpful assistant." --dataset text2sql-en --train_dataset_sample "10" --save_steps "500" --lora_target_modules q_proj k_proj v_proj --learning_rate "1e-5" --gradient_accumulation_steps "1" --eval_batch_size "1" --add_output_dir_suffix False --output_dir /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153623 --logging_dir /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153623/runs > /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153623/runs/run.log 2>&1 &
[INFO:swift] Setting args.model_type: qwen1half-4b-chat
[INFO:swift] output_dir: /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153655
[INFO:swift] Setting hub_model_id: qwen1half-4b-chat-lora
[INFO:swift] Setting args.lazy_tokenize: False
[INFO:swift] Run training: CUDA_VISIBLE_DEVICES=0 nohup swift sft --model_id_or_path "qwen/Qwen1.5-4B-Chat" --template_type "qwen" --system "You are a helpful assistant." --dataset text2sql-en --train_dataset_sample "10" --save_steps "500" --lora_target_modules q_proj k_proj v_proj --learning_rate "1e-5" --gradient_accumulation_steps "1" --eval_batch_size "1" --add_output_dir_suffix False --output_dir /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153655 --logging_dir /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153655/runs > /mnt/workspace/output/qwen1half-4b-chat/v0-20240229-153655/runs/run.log 2>&1 &
[INFO:swift] ===========Tensorboard Log============
[INFO:swift] b'2024-02-29 15:38:02.508595: I tensorflow/core/util/port.cc:111] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0.\n'
b'2024-02-29 15:38:02.510925: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.\n'
b'2024-02-29 15:38:02.543542: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered\n'
b'2024-02-29 15:38:02.543590: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered\n'
b'2024-02-29 15:38:02.543610: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered\n'
b'2024-02-29 15:38:02.549573: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.\n'
b'2024-02-29 15:38:02.549785: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.\n'
b'To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.\n'
b'2024-02-29 15:38:03.297962: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT\n'
b'2024-02-29 15:38:04.135040: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:894] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at
https://github.com/torvalds/linux/blob/v6.0/Docum
entation/ABI/testing/sysfs-bus-pci#L344-L355\n'
b'2024-02-29 15:38:04.309489: W tensorflow/core/common_runtime/gpu/gpu_device.cc:2211] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at
https://www.tensorflow.org/install/gpu
for how to download and setup the required libraries for your platform.\n'
b'Skipping registering GPU devices...\n'
b'\n'
b'NOTE: Using experimental fast data loading logic. To disable, pass\n'
b' "--load_fast=false" and report issues on GitHub. More details:\n'
b'
https://github.com/tensorflow/tensorboard/issues/4784\n'
b'\n'
b'Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all\n'
b'TensorBoard 2.15.1 at
http://localhost:6006/
(Press CTRL+C to quit)\n'都是用默认参数,只是加了一个数据集Ha,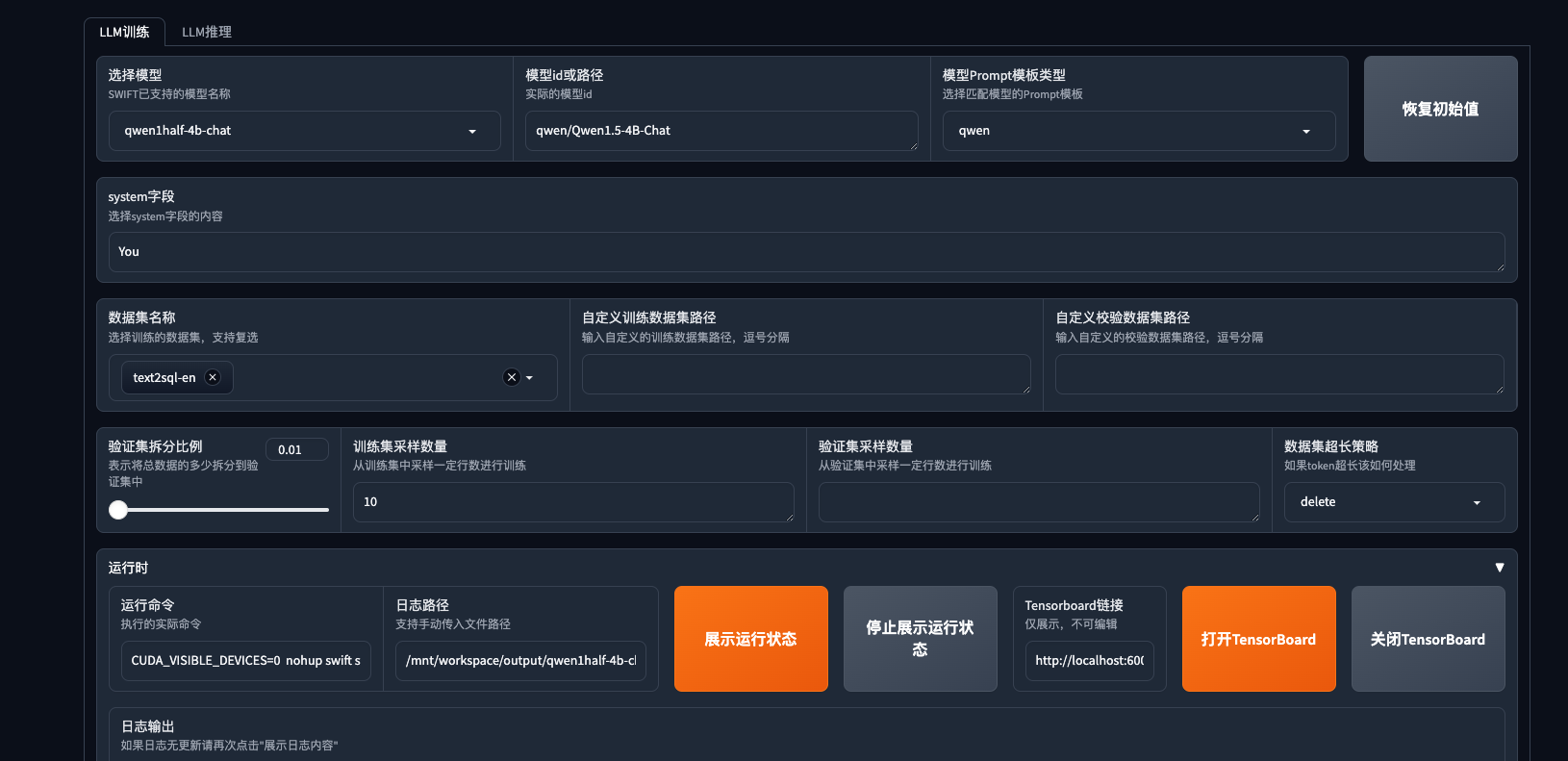
 刚才拉的安装。因为每次进去环境都要重新安装swift,应该都是最新的。
刚才拉的安装。因为每次进去环境都要重新安装swift,应该都是最新的。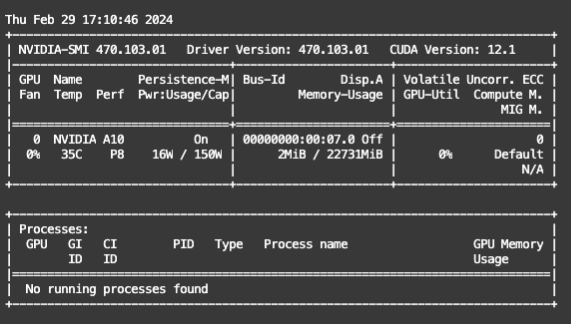 新错误AttributeError: 'int' object has no attribute 'split'
新错误AttributeError: 'int' object has no attribute 'split'
Traceback (most recent call last):
File "/opt/conda/lib/python3.10/site-packages/gradio/queueing.py", line 407, in call_prediction
output = await route_utils.call_process_api(
File "/opt/conda/lib/python3.10/site-packages/gradio/route_utils.py", line 226, in call_process_api
output = await app.get_blocks().process_api(
File "/opt/conda/lib/python3.10/site-packages/gradio/blocks.py", line 1550, in process_api
result = await self.call_function(
File "/opt/conda/lib/python3.10/site-packages/gradio/blocks.py", line 1185, in call_function
prediction = await anyio.to_thread.run_sync(
File "/opt/conda/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/opt/conda/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2134, in run_sync_in_worker_thread
return await future
File "/opt/conda/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 851, in run
result = context.run(func, args)
File "/opt/conda/lib/python3.10/site-packages/gradio/utils.py", line 661, in wrapper
response = f(args, kwargs)
File "/opt/conda/lib/python3.10/site-packages/swift/ui/llm_train/llm_train.py", line 325, in train_local
run_command, sft_args, other_kwargs = cls.train(*args)
File "/opt/conda/lib/python3.10/site-packages/swift/ui/llm_train/llm_train.py", line 268, in train
{
File "/opt/conda/lib/python3.10/site-packages/swift/ui/llm_train/llm_train.py", line 269, in
key: value.split(' ')
AttributeError: 'int' object has no attribute 'split'pip install swift,然后pip install gradio==3.50.2 然后swift web-ui,然后随便选了一个qwen1.7的模型,和一个训练集,训练数据改成10,然后就开始点击微调按钮,然后就有错了
用这个命令看下,用了显卡的,watch -n 1 nvidia-smi。此回答来自钉群魔搭ModelScope开发者联盟群 ①。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
