
modelscope-funasr这边使用asr的pipeline没有问题,但是使用speaker_diarization却报错,这是怎么回事呢?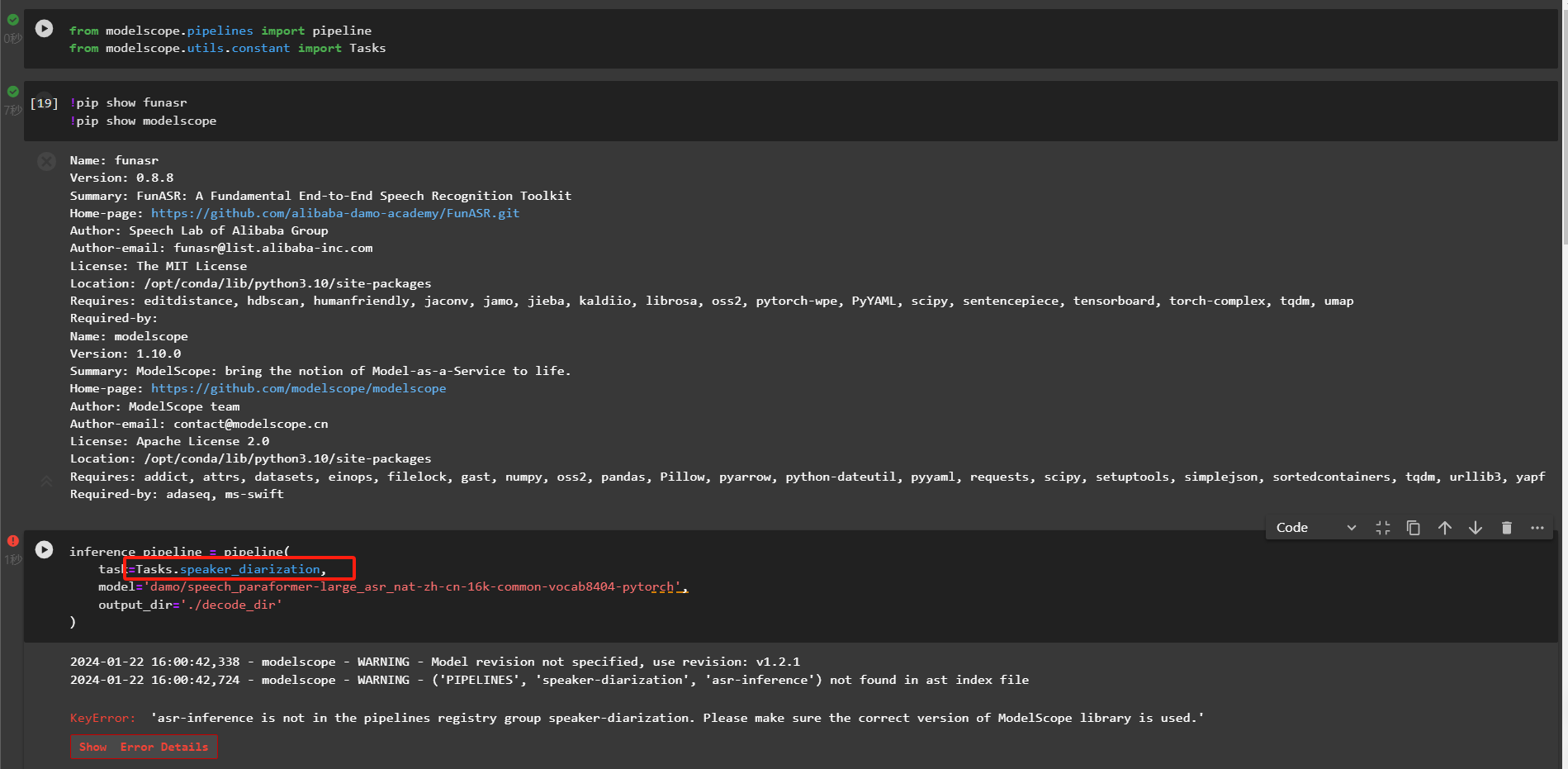
在使用ModelScope-FunASR时,如果ASR的Pipeline能够正常运行,但speaker_diarization(说话人分离)功能报错,可能是由于以下原因导致的。以下是详细分析和解决方法:
speaker_diarization功能可能依赖额外的模型或工具包,而这些依赖项可能未正确安装或配置。
检查依赖安装
确保您已按照官方文档正确安装了所有依赖项。例如:
pip install -r requirements.txt
pip install funasr[clip]
如果speaker_diarization需要特定的扩展包,请参考官方文档确认是否需要额外安装。
验证安装完整性
使用以下命令验证FunASR工具包是否完整安装:
python -c "import funasr.utils.cli_utils; funasr.utils.cli_utils.print_info()"
如果输出中未包含与speaker_diarization相关的模块信息,则说明相关依赖未正确安装。
speaker_diarization对输入数据的格式有严格要求,可能与ASR的Pipeline不同。如果输入数据格式不符合预期,可能会导致报错。
检查输入数据格式
确保输入音频文件符合speaker_diarization的要求,例如采样率、声道数等。通常,speaker_diarization需要单声道、16kHz采样的音频文件。
参考示例代码
参考官方文档中的示例代码,确保输入数据的构造方式正确。例如:
from funasr import AutoModel
model = AutoModel(model="damo/speech_speaker-diarization_common")
result = model.generate(input="path_to_audio_file.wav")
print(result)
speaker_diarization可能依赖多个子模型(如声纹提取模型、聚类模型等),如果某个子模型未正确加载,会导致报错。
检查模型路径
确保speaker_diarization所需的模型文件已正确下载并加载。可以通过以下方式检查:
from funasr import AutoModel
model = AutoModel(model="damo/speech_speaker-diarization_common")
print(model.model_paths)
如果某些模型路径为空或报错,说明模型未正确加载。
重新下载模型
如果发现模型文件缺失,可以尝试重新下载:
funasr-download --model damo/speech_speaker-diarization_common
speaker_diarization可能需要额外的配置参数,例如聚类算法的选择、阈值设置等。如果这些参数未正确配置,可能会导致报错。
检查配置参数
查阅官方文档,确认speaker_diarization所需的配置参数,并根据需求进行调整。例如:
result = model.generate(
input="path_to_audio_file.wav",
param1=value1,
param2=value2
)
调试参数
如果不确定具体参数的作用,可以尝试使用默认值,逐步调整以找到合适的配置。
speaker_diarization可能对运行环境有特殊要求,例如Python版本、CUDA版本等。如果环境不兼容,可能会导致报错。
检查Python版本
确保您的Python版本为3.7或更高版本。
检查CUDA版本
如果使用GPU加速,确保CUDA版本与PyTorch兼容。可以通过以下命令检查:
nvcc --version
python -c "import torch; print(torch.cuda.is_available())"
更新依赖
如果发现环境不兼容,可以尝试更新相关依赖:
pip install --upgrade torch torchvision torchaudio
如果上述方法未能解决问题,建议通过日志进一步分析错误原因。
查看错误日志
检查报错信息中的具体错误码或提示,定位问题来源。例如:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
...
启用调试模式
在调用speaker_diarization时,启用调试模式以获取更详细的日志信息:
result = model.generate(input="path_to_audio_file.wav", debug=True)
speaker_diarization可能涉及复杂的Pipeline流程,了解其限制和依赖关系有助于避免错误场景的应用。如果以上步骤仍无法解决问题,建议提供具体的错误信息(如完整的报错日志),以便进一步分析和解决。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
