
Flink请教下这个配置,在1.16上能用吗?我看文档这么写的,但是用的时候没找到这个api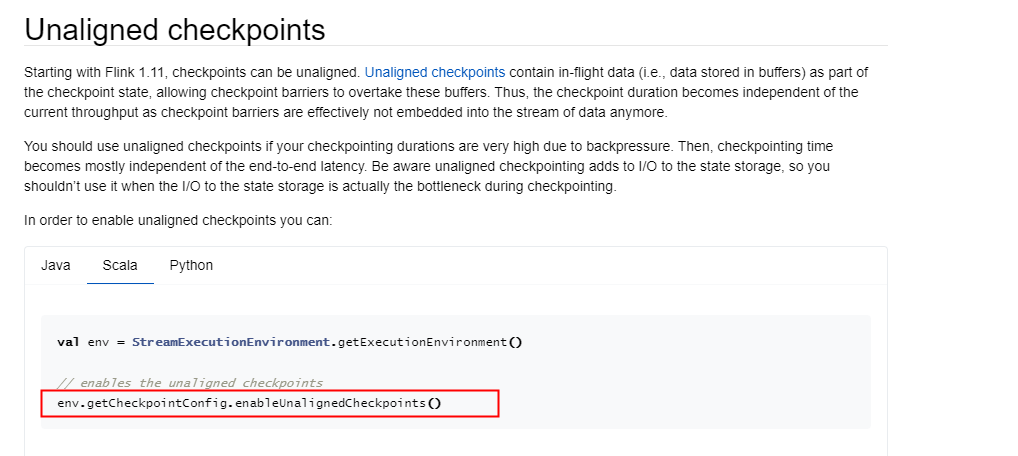
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题,您提到的配置或API在Flink 1.16版本中是否可用需要具体分析。以下是基于知识库资料的详细解答:
您提到“这个配置”但未明确指出具体的配置项或API名称。为了准确回答您的问题,请先确认以下信息: - 您提到的配置项或API是否与Flink的窗口聚合、批处理调优、Python作业开发或其他功能相关? - 如果是某个特定的函数或参数,请提供其名称(例如execution.batch.adaptive.auto-parallelism.enabled 或 pipeline.classpaths)。
如果可以提供更多上下文,将有助于更精准地定位问题。
根据知识库中的信息,不同Flink版本对功能的支持可能存在差异。以下是一些关键点:
TUMBLE、HOP、SESSION等),请确认是否涉及更新流场景。如果是,可能需要升级到更高版本的Flink或VVR以获得支持。execution.batch.adaptive.auto-parallelism.enabled)在实时计算引擎VVR 8.0及以上版本中默认开启。然而,Flink 1.16社区版并未提及此功能,因此该配置可能仅适用于VVR 8.0及以上版本。pipeline.classpaths相关(用于本地调试包含连接器的作业),该配置在Flink 1.16版本中是支持的。但需要注意,连接器的依赖可能需要手动添加uber JAR包。如果在Flink 1.16版本中未找到相关API或配置,可能的原因包括:
pipeline.classpaths配置路径。execution.batch.adaptive.auto-parallelism.enabled)仅在VVR 8.0及以上版本中有效。希望以上信息对您有所帮助!如有进一步问题,请随时补充说明。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

