
Flink整库同步 如何把数据丢入到 datahub 中?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要将Flink整库同步到DataHub中,你需要按照以下步骤操作:
首先,确保你已经安装了DataHub和Flink。
在Flink中,创建一个自定义的SourceFunction或SinkFunction,用于将数据从Flink读取或写入DataHub。
使用addSource()或addSink()方法将自定义的函数添加到Flink作业中。
配置Flink作业以连接到DataHub。这通常涉及到设置DataHub的连接信息(如主机名、端口号、用户名和密码等)。
运行Flink作业,它将自动将数据从源读取并写入DataHub。
以下是一个简单的示例,展示了如何将Flink整库同步到DataHub中:
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.datahub.DataHubSink;
import org.apache.flink.streaming.connectors.datahub.config.DataHubConnectionConfig;
import org.apache.flink.streaming.connectors.datahub.config.DataHubWriterConfig;
public class FlinkToDataHub {
public static void main(String[] args) throws Exception {
// 创建Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Flink数据源读取数据
DataStream<String> input = env.readTextFile("path/to/your/input/file");
// 配置DataHub连接信息
DataHubConnectionConfig dataHubConfig = new DataHubConnectionConfig()
.setHost("your-datahub-host")
.setPort(your-datahub-port)
.setUsername("your-username")
.setPassword("your-password");
// 配置DataHub写入器
DataHubWriterConfig writerConfig = new DataHubWriterConfig()
.setEntityType("your-entity-type")
.setPrimaryKeyFields("your-primary-key-fields")
.setUpsertMode(true);
// 将数据写入DataHub
input.addSink(new DataHubSink<>(dataHubConfig, writerConfig));
// 启动Flink作业
env.execute("Flink to DataHub");
}
}
请根据你的实际情况修改代码中的连接信息、实体类型和主键字段等参数。
在Apache Flink中,将整个数据库的数据同步到阿里云DataHub中,可以通过以下步骤实现:
数据源配置:
数据转换处理:
配置DataHub Sink:
示例代码片段(Scala API):
import org.apache.flink.streaming.connectors.datahub.DatahubSink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.datastream.DataStream
// 假设dataStream是经过处理后的DataStream
val dataStream: DataStream[String] = ...
val properties = new Properties()
properties.setProperty("endpoint", "<your-datahub-endpoint>")
properties.setProperty("accessId", "<your-access-key-id>")
properties.setProperty("accessKey", "<your-access-key-secret>")
properties.setProperty("projectName", "<your-project-name>")
properties.setProperty("topicName", "<your-topic-name>")
dataStream.addSink(new DatahubSink[String](
properties,
new SimpleStringSchema() // 或者使用符合DataHub Topic期望的自定义序列化器
))
对于Flink SQL,虽然没有直接的Datahub Sink connector,但是可以通过Flink的Table/SQL API结合JDBC Sink Connector或者其他自定义Sink来间接实现数据写入DataHub。如果DataHub提供了Flink专用的Sink Connector,则可以直接在Flink SQL中声明使用。
请确保Flink作业的并行度、资源分配以及DataHub Topic的吞吐能力都能满足数据同步的需求,避免数据积压或同步延迟。同时,务必遵循DataHub的最佳实践,保证数据的一致性和安全性。DataHub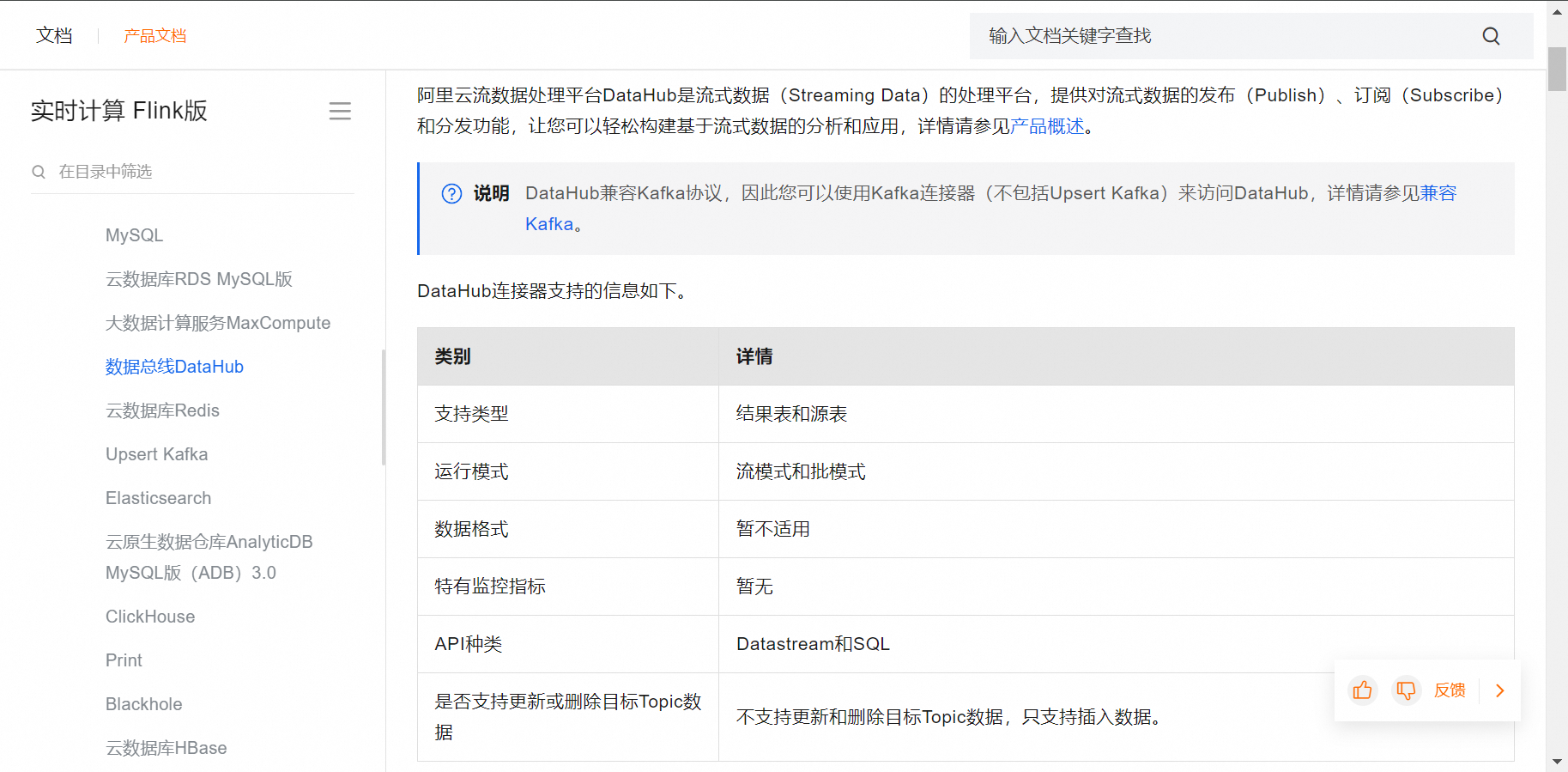
Apache Flink 是一个流处理和批处理的开源框架,而 Apache DataHub 是一个用于存储、管理和探索数据的数据平台。要将 Flink 中的数据同步到 DataHub,您需要采取一些步骤来实现这一目标。
以下是使用 Flink 将数据同步到 DataHub 的基本步骤:
1、 设置 DataHub:
* 首先,您需要在 DataHub 上创建一个存储库或项目来存储数据。
* 配置您的 DataHub 实例以允许外部连接,特别是来自 Flink 的连接。
2、 设置 Flink:
* 确保您的 Flink 集群已正确配置并正在运行。
* 确保 Flink 可以连接到 DataHub。这可能涉及到配置 Flink 的连接参数,如主机名和端口。
3、 编写 Flink 作业:
* 使用 Flink SQL 或 DataStream API 编写一个作业,该作业从源数据源读取数据。
* 使用适当的连接器或库将数据写入 DataHub。例如,您可能需要使用一个专门用于与 DataHub 交互的连接器或库。
4、 配置连接器和目标:
* 根据您使用的连接器或库,配置 Flink 以连接到 DataHub 并定义目标表或位置。
* 确保您的目标配置正确,以便数据被写入预期的存储库或项目中。
5、 运行 Flink 作业:
* 提交您的 Flink 作业以开始从源读取数据并将其写入 DataHub。
* 监控作业的执行以确保数据正确传输。
6、 验证数据:
* 在 DataHub 中验证接收到的数据,确保其完整性和准确性。
7、 优化和调整:
* 根据需要调整 Flink 作业和配置,以提高性能和可靠性。
* 根据实际的数据流和需求优化传输策略。
8、 维护和监控:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


