实时计算平台版本:v3.16.2r-blink-SP002
flink版本:blink-1.6.4
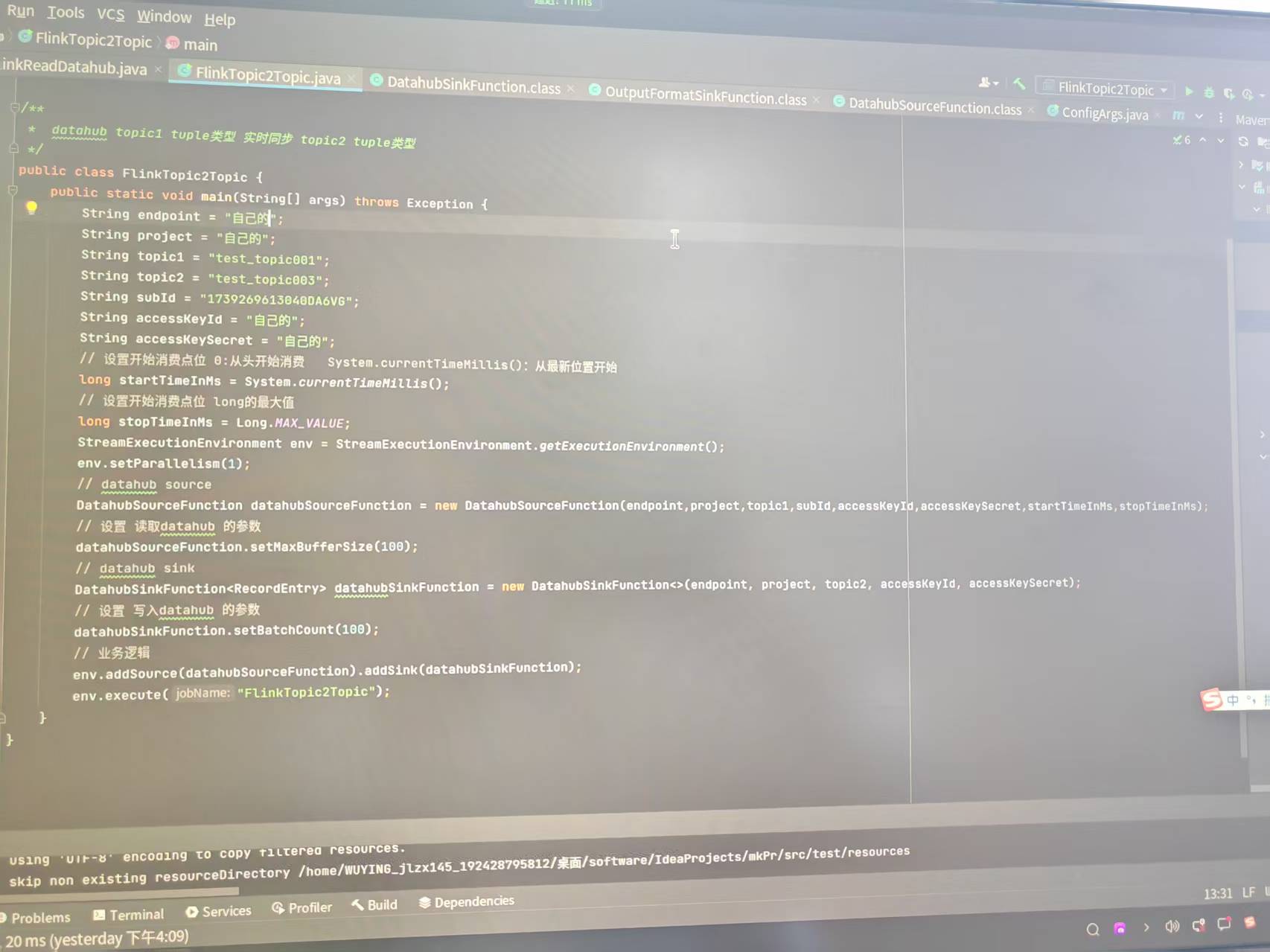
给一个靠谱的完整的能跑通的demo,不要让我看文档了,翻遍了所有flink读取datahup的demo没有一个能跑通的,都是各种报错, 找了N多个技术支持给了技术文档还是不行,公司购买的 实时计算平 和 datahup 组件,就给了一个文档还不能用,按照技术文档连一个flink任务都没有跑起来过,
Demo地址 Git地址:https://github.com/alibaba/alibaba-flink-connectors/blob/flink-1.5.2-compatible/datahub-connector
报错内容1:
2024-09-22 11:48:43,791 ERROR [Topology-0 (1/1)] org.apache.flink.streaming.runtime.tasks.StreamTask - Could not execute the task Source: Custom Source -> Flat Map -> Sink: Unnamed (1/1), aborting the execution
java.lang.NoSuchMethodError: org.apache.flink.api.common.state.OperatorStateStore.getUnionListState(Lorg/apache/flink/api/common/state/ListStateDescriptor;)Lorg/apache/flink/api/common/state/ListState;
at com.alibaba.flink.connectors.common.source.AbstractDynamicParallelSource.initializeState(AbstractDynamicParallelSource.java:115)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.initializeState(AbstractUdfStreamOperator.java:130)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:289)
at org.apache.flink.streaming.runtime.tasks.StreamTask.initializeOperators(StreamTask.java:872)
at org.apache.flink.streaming.runtime.tasks.StreamTask.initializeState(StreamTask.java:859)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:292)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:833)
at java.lang.Thread.run(Thread.java:834)
报错内容2:
by:java.lang.NoClassDeffoundError:org/apache/flink/shaded/guava18/com/google/common/cache/Cacheloader
atcom.alibaba.flink.connectors.datahub.datastream.sourceDatahubSourceFunction.createProvider(DatahubSourceFunction.java269)
at com.alibaba.flink,connectors.datahub.datastream.sourceDatahubsourceFunction.init(DatahubSourceFunction.java115)
at com.alibaba.flink.connectors.datahub.datastream.example.DatahubsourceFunctionExample.runExample
tahubSourceFunctionExample.java:46)
at com.alibaba.flink.connectors.datahub.datastream.example.DatahubSourceFunctionExample.main
tahubSourceFunctionExample.java:68)
at sun.reflect.NativeMethodAccessorImpl.invokeo(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
代码如下:
public class DatahubSourceFunctionExample implements Serializable {
private String endPoint = "";
private String accessId = "";
private String accessKey = "";
private String projectName = "";
private String topicName = "";
public void runExample() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DatahubSourceFunction datahubSource =
new DatahubSourceFunction(endPoint, projectName, topicName, accessId, accessKey, 0,
Long.MAX_VALUE, 1, 1, 1);
env.addSource(datahubSource).flatMap(
(FlatMapFunction<List<RecordEntry>, Tuple2<String, Long>>) (recordEntries, collector) -> {
for (RecordEntry recordEntry : recordEntries) {
collector.collect(getStringLongTuple2(recordEntry));
}
}).returns(new TypeHint<Tuple2<String, Long>>() {}).print();
env.execute();
}
private Tuple2<String, Long> getStringLongTuple2(RecordEntry recordEntry) {
Tuple2<String, Long> tuple2 = new Tuple2<>();
TupleRecordData recordData = (TupleRecordData) (recordEntry.getRecordData());
tuple2.f0 = (String) recordData.getField(0);
tuple2.f1 = (Long) recordData.getField(1);
return tuple2;
}
public static void main(String[] args) throws Exception {
DatahubSourceFunctionExample sourceFunctionExample = new DatahubSourceFunctionExample();
sourceFunctionExample.runExample();
}
}
pom文件:
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.12.2-public</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>jul-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<!--<exclusion>-->
<!--<artifactId>jackson-databind</artifactId>-->
<!--<groupId>com.fasterxml.jackson.core</groupId>-->
<!--</exclusion>-->
<!--<exclusion>-->
<!--<artifactId>jackson-annotations</artifactId>-->
<!--<groupId>com.fasterxml.jackson.core</groupId>-->
<!--</exclusion>-->
</exclusions>
</dependency>
<dependency>
<groupId>com.alibaba.flink</groupId>
<artifactId>aliyun-connectors-common</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<!--necessary for datahub example run-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-netty</artifactId>
<version>4.0.27.Final-2.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>datahub-client-library</artifactId>
<version>1.1.12-public</version>
</dependency>
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要使用Apache Flink实时计算读取DataHub作为数据源并写出数据,您可以参考以下示例代码和配置说明。此示例适用于基于Flink的实时数据处理场景,展示了如何配置Flink作业以连接到DataHub并进行数据读写操作。
首先,配置Flink作业以从DataHub读取数据。这里使用DatahubSourceFunction来实现数据源的读取逻辑:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.aliyun.datahub.client.function.source.DatahubSourceFunction;
public class DatahubFlinkReadDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// DataHub连接配置
DatahubSourceFunction datahubSource = new DatahubSourceFunction(
"<yourEndPoint>", // DataHub endpoint
"<yourProjectName>", // 项目名称
"<yourTopicName>", // 主题名称
"<yourSubId>", // 订阅ID
"<yourAccessId>", // AccessKey ID
"<yourAccessKey>", // AccessKey Secret
"public", // schema类型,默认为"public"
false // 是否开启schema注册,默认为false
);
// 添加source到流执行环境
env.addSource(datahubSource)
.print(); // 打印读取的数据,实际应用中应替换为进一步的数据处理逻辑
// 触发执行
env.execute("Datahub Flink Read Demo");
}
}
若需将处理后的数据写回DataHub,您需要配置一个sink。以下是一个简化的sink配置示例,实际应用中您可能需要根据处理逻辑调整:
CREATE TEMPORARY TABLE datahub_sink (
name VARCHAR
) WITH (
'connector' = 'datahub',
'endPoint' = '<yourEndPoint>',
'project' = '<yourProjectName>',
'topic' = '<yourTopicName>',
'accessId' = '${secret_values.ak_id}',
'accessKey' = '${secret_values.ak_secret}',
'batchSize' = '512000', -- 批量写入大小
'batchCount' = '500' -- 批量写入计数
);
-- 假设有一个名为processed_data的流,将其插入到datahub_sink
INSERT INTO datahub_sink SELECT LOWER(name) FROM processed_data;
<yourEndPoint>、<yourProjectName>、<yourTopicName>、<yourSubId>、<yourAccessId>、<yourAccessKey>等占位符为您的实际DataHub配置信息。maxFetchSize、maxBufferSize等参数以适应您的数据吞吐需求。不同版本的 Flink 设计的。请确保您使用的 connector 与您的 Flink 版本兼容。
不同版本的 Flink 设计的。请确保您使用的 connector 与您的 Flink 版本兼容。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。