
Flink怎么对接oracle数据源呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要将Flink对接Oracle数据源,首先需要引入flink-connector-oracle-cdc要将Flink对接Oracle数据源,首先需要引入flink-connector-oracle-cdc连接器,该连接器是基于Debezium实现的,能够从Oracle等数据库读取存量历史数据和增量变更数据。然后,可以使用Flink SQL来创建源表并读取数据,具体操作如下:
-- 创建Oracle CDC源表table_source_oracle,从Oracle数据库中读取数据
CREATE TABLE table_source_oracle (
id INT,
name STRING,
description STRING,
weight DECIMAL(10,3)
) WITH (
'connector' = 'oracle-cdc',
'hostname' = '<oracle_host',
'port' = 'oracle_port',
'username' = 'oracle_user',
'password' = 'oracle_password',
'database' = 'oracle_db',
'table' = 'oracle_table'
);
在上述代码中,需要将oracle_host、oracle_port、oracle_user、oracle_password、oracle_db和oracle_table替换为实际的Oracle数据库连接信息和表名。这样,就可以通过Flink SQL从Oracle数据库中读取数据了。
Apache Flink对接Oracle数据源通常通过Flink的JDBC connector来实现。JDBC connector允许Flink从各种支持JDBC协议的数据库中读取数据或向这些数据库写入数据,其中包括Oracle数据库。
以下是一个使用Flink JDBC connector从Oracle数据库中读取数据的基本步骤:
添加依赖:
如果使用Maven管理项目依赖,请在pom.xml文件中添加Flink JDBC connector的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>YOUR_FLINK_VERSION</version>
</dependency>
其中YOUR_FLINK_VERSION替换为你使用的Flink版本号。
创建JDBC连接:
设置Oracle数据库连接所需的URL、用户名和密码,以及其他可能的连接属性。
final String url = "jdbc:oracle:thin:@//your-oracle-server:port/service_name";
final String username = "your_username";
final String password = "your_password";
// 创建JDBC连接选项
JdbcConnectionOptions connectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl(url)
.withDriverName("oracle.jdbc.driver.OracleDriver")
.withUsername(username)
.withPassword(password)
.build();
创建JDBC数据源:
使用JdbcInputFormat或JdbcSource(Flink 1.13及以上版本推荐使用JdbcSource)来读取Oracle数据。
// 构建表查询
String query = "SELECT * FROM your_table";
// 创建JDBC数据源
JdbcInputFormat jdbcInputFormat = JdbcInputFormat.buildJdbcInputFormat()
.setDrivername("oracle.jdbc.driver.OracleDriver")
.setDBUrl(url)
.setUsername(username)
.setPassword(password)
.setQuery(query)
// 根据表结构设置字段和类型映射
.setRowTypeInfo(new RowTypeInfo(...))
.build();
// 或者在Flink 1.13及以上版本中使用JdbcSource
JdbcSource<Row> jdbcSource = JdbcSource.builder()
.setDrivername("oracle.jdbc.driver.OracleDriver")
.setDBUrl(url)
.setUsername(username)
.setPassword(password)
.setQuery(query)
.setRowMapper(new JdbcRowMapper<Row>() {
@Override
public Row mapRow(ResultSet resultSet) throws SQLException {
// ...这里根据ResultSet创建Row对象
}
})
.build();
将数据源与Flink作业连接起来:
创建一个DataStream或Table,然后使用上述的JDBC数据源作为数据来源。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 对于DataStream API
DataStream<Row> stream = env.createInput(jdbcInputFormat);
// 或者对于Table API & SQL
TableEnvironment tableEnv = TableEnvironment.create(...);
TableResult result = tableEnv.executeSql("CREATE TABLE oracle_table (... AS SELECT * FROM your_table WITH ('connector'='jdbc', 'url'='" + url + "', 'table-name'='your_table', 'username'='" + username + "', 'password'='" + password + "')");
// 然后可以进一步处理这些数据,如窗口聚合、转换等
实际开发时应确保Oracle的JDBC驱动(如ojdbc*.jar)已经被添加到Flink作业的类路径中,这样才能成功建立到Oracle数据库的连接。此外,为了安全起见,强烈建议不要在代码中硬编码密码,而是通过环境变量、配置文件或其他安全方式传递敏感信息。在Flink作业提交时,可以将这些连接参数作为作业配置的一部分传入。JDBC
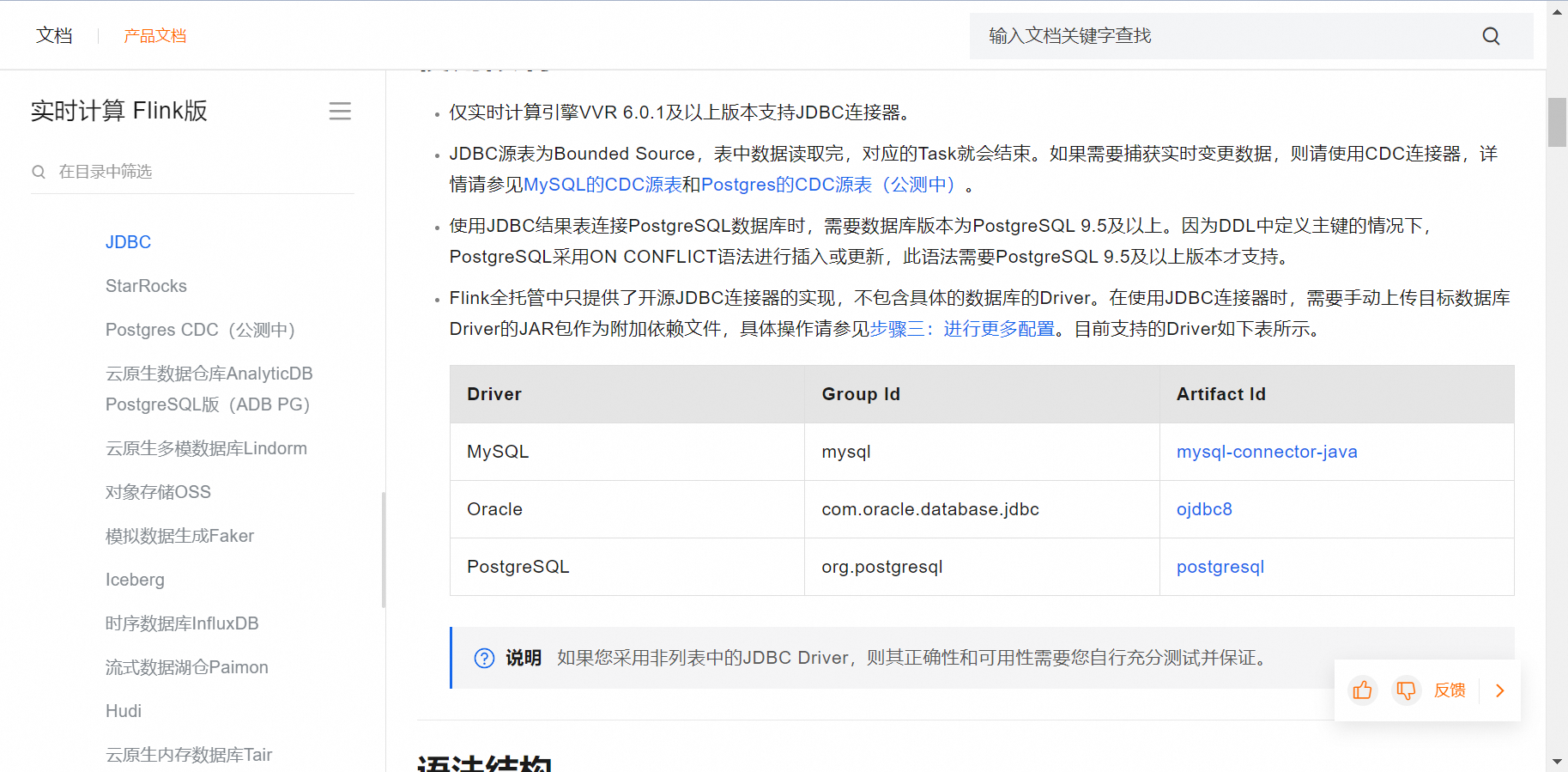
阿里云的Flink对接Oracle数据源通常可以通过以下步骤实现:
配置连接器:
添加依赖:
创建表源:
CREATE TABLE oracle_table (
column1 STRING,
column2 INT,
...
) WITH (
'connector' = 'oracle-cdc',
'hostname' = '<your_oracle_host>',
'port' = '<your_oracle_port>',
'username' = '<your_username>',
'password' = '<your_password>',
'database-name' = '<your_database_name>',
'table-name' = '<your_oracle_source_table>',
-- 其他配置项...
);
安全组和网络设置:
测试连接和同步数据:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


