
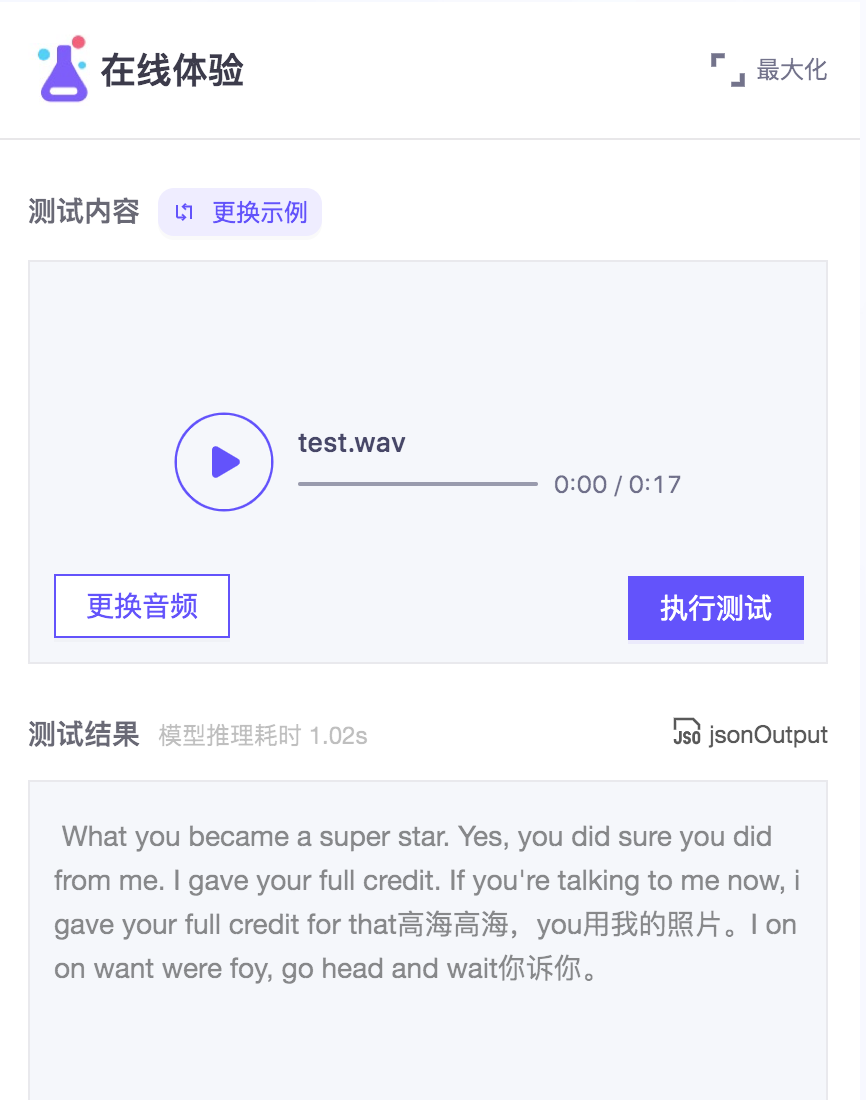
在modelscope-funasr体验了这个,同一段音频,每次执行,输出有小差异,这样不正常吧?
在modelscope-funasr体验了这个,同一段音频,每次执行,输出有小差异,这样不正常吧?https://www.modelscope.cn/models/damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary 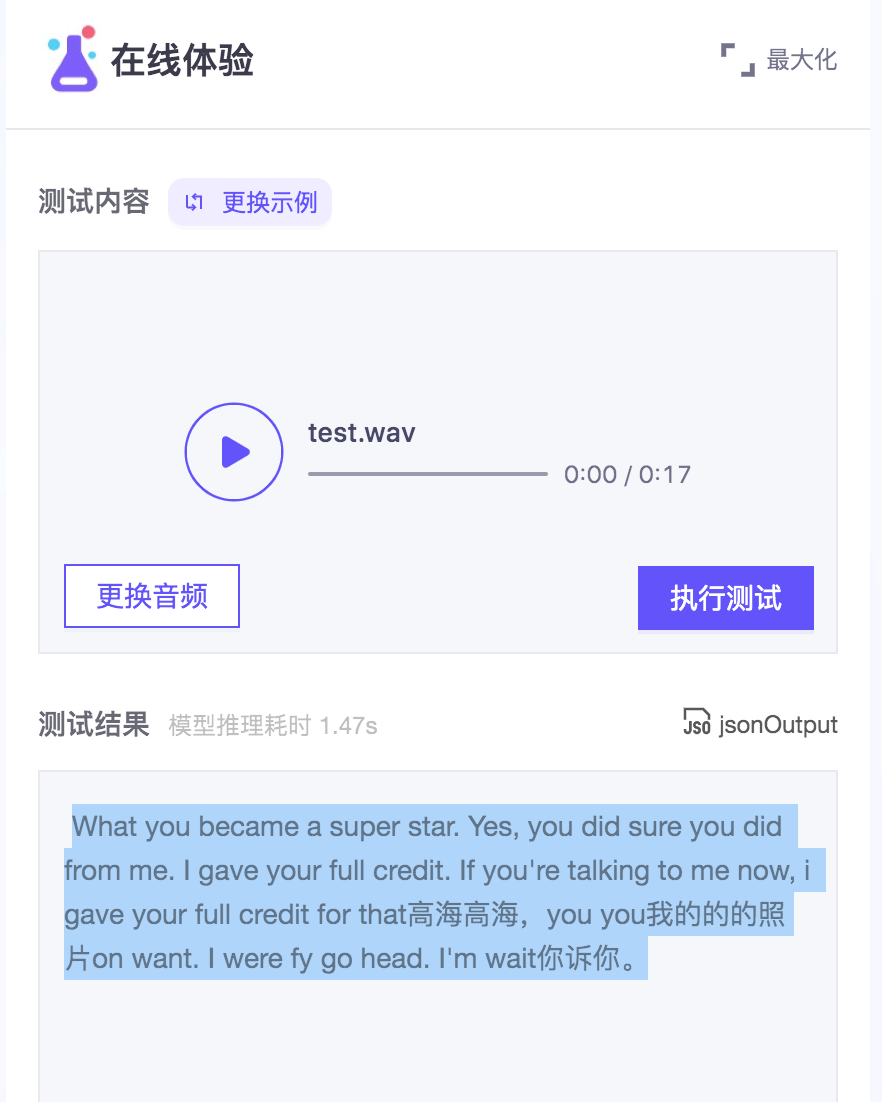
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
在语音识别任务中,同一段音频每次执行输出有小差异是比较常见的情况。这可能是由于以下几个原因导致的:
模型的随机性:某些语音识别模型(如基于深度学习的模型)在推理过程中会引入一定的随机性,例如使用不同的dropout率、随机采样等。因此,即使输入相同的音频,每次执行可能会得到稍有不同的输出结果。
音频质量:如果输入的音频质量不好,例如存在噪声、变调等问题,那么在进行语音识别时,模型可能会对这些问题进行不同的处理,从而导致每次执行输出有小差异。
数据处理和预处理的差异:在语音识别任务中,通常会对输入的音频进行一些预处理操作,例如降噪、特征提取等。如果每次执行时这些操作的处理方式或参数有所不同,也会导致输出结果有小差异。
虽然每次执行输出有小差异是正常的现象,但如果这种差异过大或者对结果的准确性产生了明显影响,可能需要进一步检查和优化模型或数据处理流程。
2024-01-13 14:38:03赞同 展开评论 -
这种情况可能是由于模型的随机性导致的。FunASR是一个基于深度学习的语音识别系统,它使用大量的训练数据和复杂的神经网络结构来提高识别的准确性。然而,由于模型的训练过程涉及到随机初始化和权重更新等操作,因此每次执行时可能会产生不同的结果。
如果你希望获得更稳定的结果,可以尝试多次运行FunASR并取平均值或中位数作为最终输出。此外,你还可以考虑使用其他更加稳定的语音识别系统,如百度、腾讯等公司的语音识别产品。
2024-01-12 11:47:34赞同 展开评论 -
应该是提特征开了dither扰动,总体不影响效果,但是个别sample重复推理效果可能没法完全一致。这个可以在后面把dither关了。此回答整理自钉群“modelscope-funasr社区交流”
2024-01-10 17:03:20赞同 展开评论

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352